Downloaded 80 times













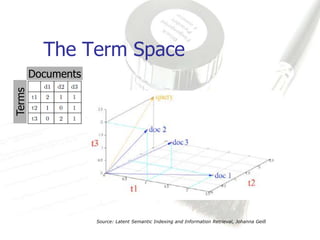
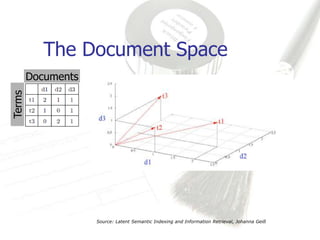

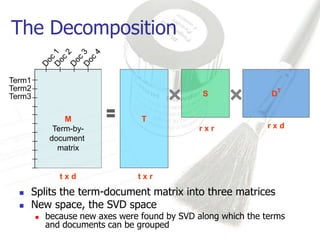


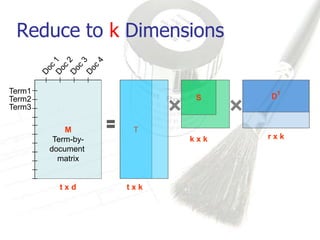
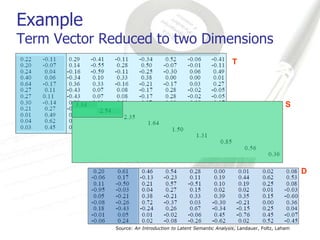
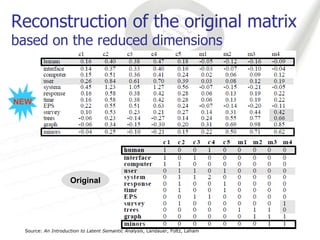








Latent Semantic Analysis (LSA) is a mathematical technique that infers semantic relationships by analyzing large volumes of text through singular value decomposition (SVD) and dimensionality reduction, without relying on syntactic or lexical information. It evaluates word and passage connections to measure semantic similarity, which can enhance information retrieval processes by facilitating more accurate matches between queries and documents. LSA demonstrates significant improvements in correlation metrics for semantic similarity, indicating its effectiveness over traditional methods.










![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2740-thumbnail.jpg?width=640&height=640&fit=bounds)









































