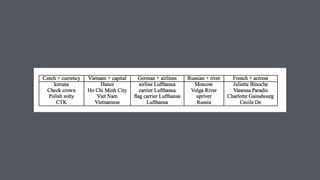
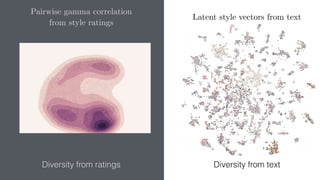
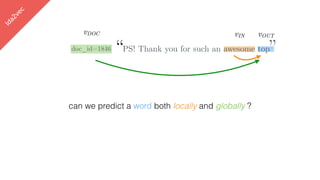
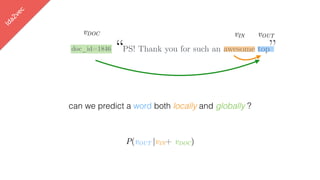
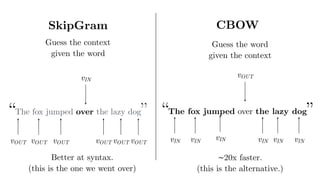
This document summarizes the lda2vec model, which combines aspects of word2vec and LDA. Word2vec learns word embeddings based on local context, while LDA learns document-level topic mixtures. Lda2vec models words based on both their local context and global document topic mixtures to leverage both approaches. It represents documents as mixtures over sparse topic vectors similar to LDA to maintain interpretability. This allows it to predict words based on local context and global document content.


























![w
ord2vec
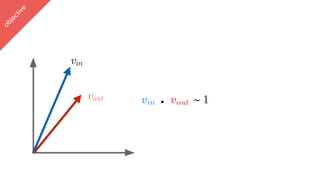
vin . vout ∈ [-1,1]
objective](https://image.slidesharecdn.com/datadaytalk-160116232525/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-30-320.jpg)
![w
ord2vec
But we’d like to measure a probability.
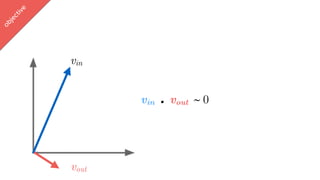
vin . vout ∈ [-1,1]
objective](https://image.slidesharecdn.com/datadaytalk-160116232525/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-31-320.jpg)
![w
ord2vec
But we’d like to measure a probability.
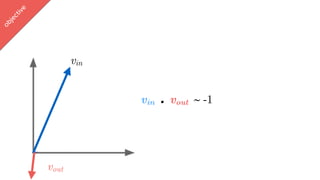
softmax(vin . vout ∈ [-1,1])
objective
∈ [0,1]](https://image.slidesharecdn.com/datadaytalk-160116232525/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-32-320.jpg)
![w
ord2vec
But we’d like to measure a probability.
softmax(vin . vout ∈ [-1,1])
Probability of choosing 1 of N discrete items.
Mapping from vector space to a multinomial over words.
objective](https://image.slidesharecdn.com/datadaytalk-160116232525/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-33-320.jpg)
![w
ord2vec
But we’d like to measure a probability.
exp(vin . vout ∈ [0,1])softmax ~
objective](https://image.slidesharecdn.com/datadaytalk-160116232525/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-34-320.jpg)
![w
ord2vec
But we’d like to measure a probability.
exp(vin . vout ∈ [-1,1])
Σexp(vin . vk)
softmax =
objective
Normalization term over all words
k ∈ V](https://image.slidesharecdn.com/datadaytalk-160116232525/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-35-320.jpg)
![w
ord2vec
But we’d like to measure a probability.
exp(vin . vout ∈ [-1,1])
Σexp(vin . vk)
softmax = = P(vout|vin)
objective
k ∈ V](https://image.slidesharecdn.com/datadaytalk-160116232525/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-36-320.jpg)


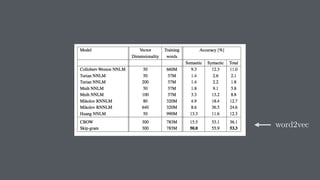

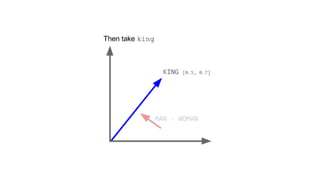
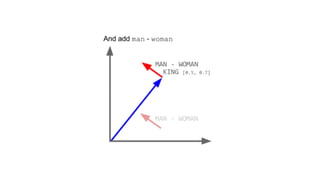
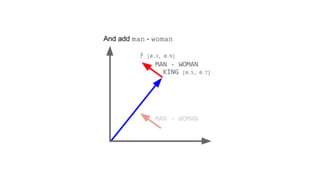

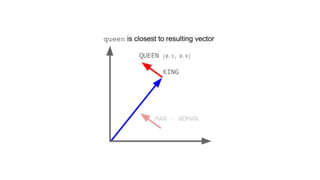
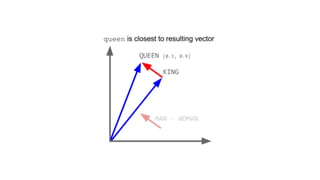
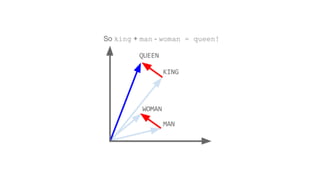
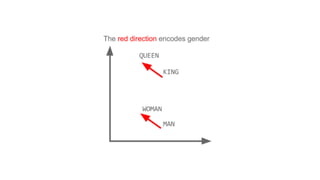


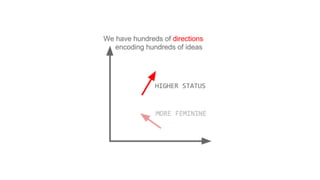
















![[ -0.75, -1.25, -0.55, -0.12, +2.2] [ 0%, 9%, 78%, 11%]
typical word2vec vector typical LDA document vector](https://image.slidesharecdn.com/datadaytalk-160116232525/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-73-320.jpg)
![typical word2vec vector
[ 0%, 9%, 78%, 11%]
typical LDA document vector
[ -0.75, -1.25, -0.55, -0.12, +2.2]
All sum to 100%All real values](https://image.slidesharecdn.com/datadaytalk-160116232525/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-74-320.jpg)
![5D word2vec vector
[ 0%, 9%, 78%, 11%]
5D LDA document vector
[ -0.75, -1.25, -0.55, -0.12, +2.2]
Sparse
All sum to 100%
Dimensions are absolute
Dense
All real values
Dimensions relative](https://image.slidesharecdn.com/datadaytalk-160116232525/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-75-320.jpg)
![100D word2vec vector
[ 0%0%0%0%0% … 0%, 9%, 78%, 11%]
100D LDA document vector
[ -0.75, -1.25, -0.55, -0.27, -0.94, 0.44, 0.05, 0.31 … -0.12, +2.2]
Sparse
All sum to 100%
Dimensions are absolute
Dense
All real values
Dimensions relative
dense sparse](https://image.slidesharecdn.com/datadaytalk-160116232525/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-76-320.jpg)
![100D word2vec vector
[ 0%0%0%0%0% … 0%, 9%, 78%, 11%]
100D LDA document vector
[ -0.75, -1.25, -0.55, -0.27, -0.94, 0.44, 0.05, 0.31 … -0.12, +2.2]
Similar in fewer ways
(more interpretable)
Similar in 100D ways
(very flexible)
+mixture
+sparse](https://image.slidesharecdn.com/datadaytalk-160116232525/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-77-320.jpg)







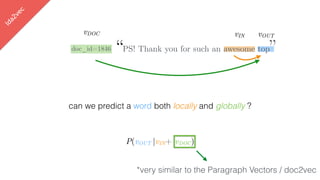





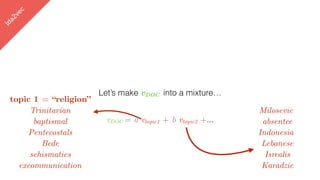
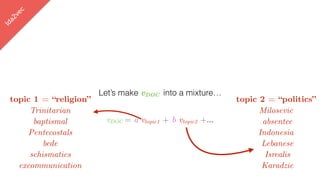

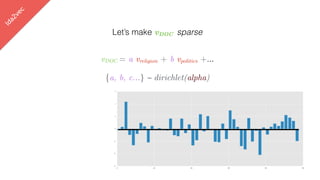
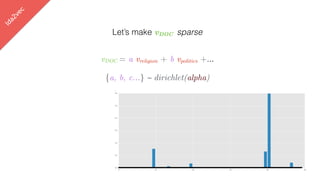
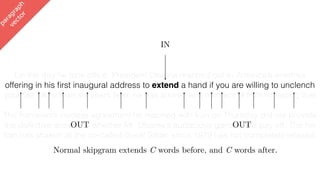
![lda2vec
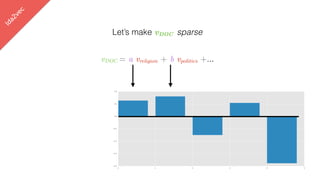
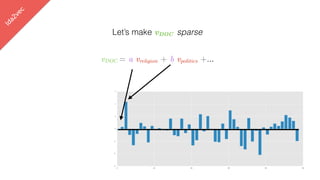
Let’s make vDOC sparse
[ -0.75, -1.25, …]
vDOC = a vreligion + b vpolitics +…](https://image.slidesharecdn.com/datadaytalk-160116232525/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-99-320.jpg)
























![from gensim.models import Doc2Vec
fn = “item_document_vectors”
model = Doc2Vec.load(fn)
model.most_similar('pregnant')
matches = list(filter(lambda x: 'SENT_' in x[0], matches))
# ['...I am currently 23 weeks pregnant...',
# '...I'm now 10 weeks pregnant...',
# '...not showing too much yet...',
# '...15 weeks now. Baby bump...',
# '...6 weeks post partum!...',
# '...12 weeks postpartum and am nursing...',
# '...I have my baby shower that...',
# '...am still breastfeeding...',
# '...I would love an outfit for a baby shower...']
sentence
search](https://image.slidesharecdn.com/datadaytalk-160116232525/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-133-320.jpg)






















































![[SmartNews] Globally Scalable Web Document Classification Using Word2Vec](https://cdn.slidesharecdn.com/ss_thumbnails/smartnewsdocumentclassification-150428133649-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)







































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)








