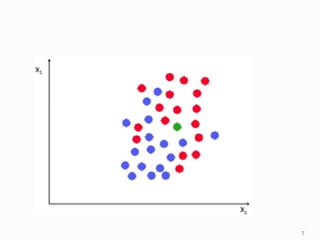
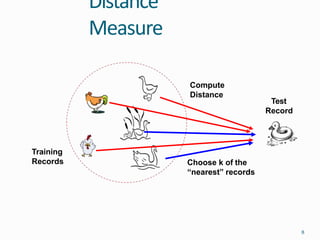
This document discusses the K-nearest neighbors (KNN) algorithm, an instance-based learning method used for classification. KNN works by identifying the K training examples nearest to a new data point and assigning the most common class among those K neighbors to the new point. The document covers how KNN calculates distances between data points, chooses the value of K, handles feature normalization, and compares strengths and weaknesses of the approach. It also briefly discusses clustering, an unsupervised learning technique where data is grouped based on similarity.







![DistanceBetweenNeighbors
• Calculate the distance between newexample
(E)and all examplesin the trainingset.
• Euclidean distance between two examples.
– X=[x1,x2,x3,..,xn]
– Y=[y1,y2,y3,...,yn]
– TheEuclidean distance between X and Yisdefined
as:
11
n
i1
2
(xi yi )D(X ,Y ) ](https://image.slidesharecdn.com/knn-160904075605-converted-191209005536/85/Knn-160904075605-converted-10-320.jpg)

![3-KNN:Example(1)
12
sqrt [(35-37)2+(35-50)2+(3-
2)2]=15.16
sqrt [(22-37)2+(50-50)2+(2-
2)2]=15
sqrt [(25-37)2+(40-50)2+(4-
2)2]=15.74
?
Distance from John
sqrt [(63-37)2+(200-50)2 +(1-
2)2]=152.23
sqrt [(59-37)2+(170-50)2 +(1-
2)2]=122
Customer Age Income No.
credit
cards
Class
George 35 35K 3 No
Rachel 22 50K 2 Yes
Steve 63 200K 1 No
Tom 59 170K 1 No
Anne 25 40K 4 Yes
John 37 50K 2 YES](https://image.slidesharecdn.com/knn-160904075605-converted-191209005536/85/Knn-160904075605-converted-12-320.jpg)















































































