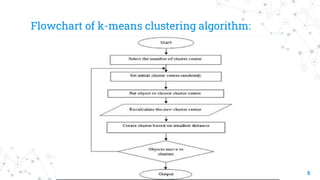
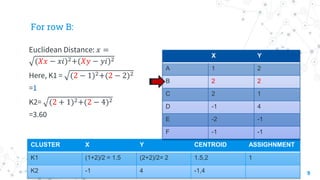
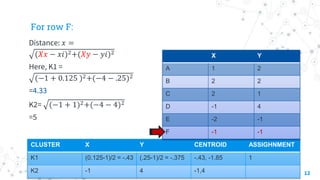
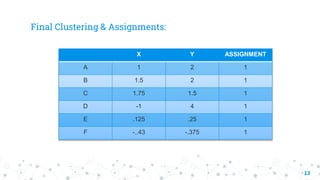
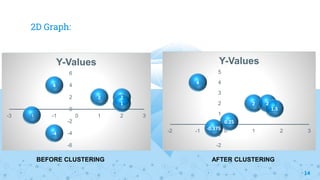
The document explains the k-means clustering algorithm and its implementation steps, highlighting how to categorize a dataset into groups using unsupervised learning. It provides a detailed pseudocode, methodological approach for initial centroids, and iterative calculations for assigning data points to clusters. Additionally, it includes a practical example of performing k-means clustering on a given set of points and visualizing the results on a 2D graph.