More Related Content

PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoWebmining#17 
PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoNLP#9 
PDF
Jubatus: 分散協調をキーとした大規模リアルタイム機械学習プラットフォーム 
PDF

PDF
情報抽出入門 〜非構造化データを構造化させる技術〜 
PDF
Jubatusの紹介@第6回さくさくテキストマイニング 
PDF

PDF
What's hot

PDF
Twitter分析のためのリアルタイム分析基盤@第4回Twitter研究会 
PDF
機械学習チュートリアル@Jubatus Casual Talks 
PDF
Development and Experiment of Deep Learning with Caffe and maf 
PDF

PDF

PDF
Jubatusにおける大規模分散オンライン機械学習 
PPTX

PDF

PDF
Python 機械学習プログラミング データ分析演習編 
PDF
乱択データ構造の最新事情 -MinHash と HyperLogLog の最近の進歩- 
PDF

PDF
Pythonによるソーシャルデータ分析―わたしはこうやって修士号を取得しました― 
PDF

PDF
ICML2013読み会 ELLA: An Efficient Lifelong Learning Algorithm 
PDF

PDF

PDF

PDF

PDF

PDF
Randomforestで高次元の変数重要度を見る #japanr LT Viewers also liked

PDF
パーソナライズニュースを支えるML業務のまわしかた@Yahoo! JAPAN 
PDF
Machine Learning Casual Talks opening talk 
PDF
Julia 100 exercises #JuliaTokyo 
PDF
素人がDeep Learningと他の機械学習の性能を比較してみた 
PDF
Introduction to Kanagawa Ruby Kaigi01 #kana01 
PDF

PDF
Statistical Semantic入門 ~分布仮説からword2vecまで~ ![[D23] SQL Server 2014 リリース記念!~Hekaton, カラムストアを試して、さらにギンギンに速くしてみました!~by Daisuk...](https://cdn.slidesharecdn.com/ss_thumbnails/d23iti-140624011401-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[D23] SQL Server 2014 リリース記念!~Hekaton, カラムストアを試して、さらにギンギンに速くしてみました!~by Daisuk... 
PDF
ACL2011読み会 Exploiting Web-Derived Selectional Preference to Improve Statistic... 
PPTX
Jubatus workshop - 分散処理の仕組み 
PDF
形態素列パターンマッチャー�MIURAをつくりました @DSIRNLP#6 
PDF

PDF
N-gram統計量からの係り受け情報の復元 (YANS2011) 
PDF
20140618 google earthの最前線 
PDF

PDF

PPTX
DBpedia Citation Challenge. (Not only) Polish Citations in Wikipedia: analysi... 
PPTX

PDF
UXデザインとコンセプト評価�~俺様企画はだめなのよ 
PDF
Similar to Jubatusにおける機械学習のテスト@MLCT

PDF

PDF

PPTX

PDF
Testing machine learning development 
PDF
Machine learning CI/CD with OSS 
PDF

PDF

PDF

PDF
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太 
PPTX
Coursera machine learning week6 
PDF

PDF

PDF

PDF

PPTX
Beyond Accuracy: Behavioral Testing of NLP Models with CheckList 
PDF

PDF

PPTX
機械学習応用システムの開発技術�(機械学習工学)�の現状と今後の展望� 
PDF

PDF
A Machine Learning Framework for Programming by Example More from Yuya Unno

PDF

PDF

PDF
ベンチャー企業で言葉を扱うロボットの研究開発をする 
PDF

PDF

PDF

PDF

PDF
最先端NLP勉強会�“Learning Language Games through Interaction”�Sida I. Wang, Percy L... 
PDF

PDF
Chainerのテスト環境とDockerでのCUDAの利用 
PDF

PDF
NIP2015読み会「End-To-End Memory Networks」 
PDF

PDF

PDF

PDF

PDF

PDF
大規模データ時代に求められる自然言語処理 -言語情報から世界を捉える- 
PDF
EMNLP2014読み会 "Efficient Non-parametric Estimation of Multiple Embeddings per ... 
PDF
企業における自然言語処理技術の活用の現場(情報処理学会東海支部主催講演会@名古屋大学) Recently uploaded

PDF
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard 
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」 
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研) 
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector 
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S... 
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis 
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望 
PDF
PMBOK 7th Edition_Project Management Context Diagram 
PDF
PMBOK 7th Edition Project Management Process Scrum 
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信 
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf 
PDF
PMBOK 7th Edition_Project Management Process_WF Type Development 
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版 Jubatusにおける機械学習のテスト@MLCT
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
雰囲気だけ・・・
19
void normal_herd::update(
const common::sfv_t&sfv, float margin, float variance,
const string& pos_label, const string& neg_label) {
for (common::sfv_t::const_iterator it = sfv.begin(); it != sfv.end(); ++it) {
// 中略略
storage_->set2(feature, pos_label,
storage::val2_t(pos_val.v1 + (1.f - margin) * val_covariance_pos
/ (val_covariance_pos * val + 1.f / C),
1.f / ((1.f / pos_val.v2) + (2 * C + C * C * variance) * val * val)));
if (neg_label != "") {
storage_->set2(feature, neg_label,
storage::val2_t(neg_val.v1 + (1.f - margin) * val_covariance_neg
/ (val_covariance_neg * val + 1.f / C),
1.f / ((1.f / neg_val.v2) + (2 * C + C * C * variance) * val * val)));
}
}
}
この中に⼀一箇所だけ+と−を間違えています
- 20.
- 21.
- 22.
- 23.
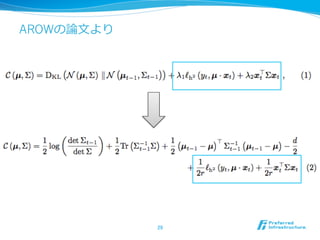
正直すまんかった
@@ -38,7 +38,7@@ void PA::train(const sfv_t& sfv, const
string& label) {"
if (sfv_norm == 0.f) {"
return;"
}"
- update_weight(sfv, loss / sfv_norm, label,
incorrect_label);"
+ update_weight(sfv, loss / (2 * sfv_norm), label,
incorrect_label);"
}"
"
string PA::name() const {
23
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
直しました
--- a/src/classifier/arow.cpp"
+++ b/src/classifier/arow.cpp"
@@-40,7 +40,7 @@ void AROW::train(const sfv_t& sfv, const
string& label){"
if (margin >= 1.f) {"
return;"
}"
- float beta = 1.f / (variance + config.C);"
+ float beta = 1.f / (variance + 1.f / config.C);"
float alpha = (1.f - margin) * beta; // max(0, 1-
margin) = 1-margin"
update(sfv, alpha, beta, label, incorrect_label);"
}
34
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
























![みんな⼤大好き-cオプション
l 「Cいくつにした?」と聞かれる
l 正則化項と損失の⽐比率率率を調整する重みのこと
26
% svm-train"
Usage: svm-train [options] training_set_file
[model_file]"
options:"
..."
-c cost : set the parameter C of C-SVC, epsilon-SVR,
and nu-SVR (default 1)"
...](https://image.slidesharecdn.com/20140606mlct-140606061901-phpapp02/85/Jubatus-MLCT-26-320.jpg)