Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
A俺
Uploaded by
antibayesian 俺がS式だ
3,899 views
Sakusaku svm
Education
◦
Read more
13
Save
Share
Embed
Embed presentation
Download
Downloaded 47 times
1
/ 31
2
/ 31
3
/ 31
4
/ 31
5
/ 31
6
/ 31
7
/ 31
8
/ 31
9
/ 31
10
/ 31
11
/ 31
12
/ 31
13
/ 31
14
/ 31
15
/ 31
16
/ 31
17
/ 31
18
/ 31
19
/ 31
20
/ 31
21
/ 31
22
/ 31
23
/ 31
24
/ 31
25
/ 31
26
/ 31
27
/ 31
28
/ 31
29
/ 31
30
/ 31
31
/ 31
More Related Content
PDF
あんちべのすべらない話~俺のツイートがこんなにウケないはずがない~
by
antibayesian 俺がS式だ
PDF
SVM実践ガイド (A Practical Guide to Support Vector Classification)
by
sleepy_yoshi
PPTX
Pythonとdeep learningで手書き文字認識
by
Ken Morishita
PDF
Active Learning from Imperfect Labelers @ NIPS読み会・関西
by
Taku Tsuzuki
PDF
Active Learning 入門
by
Shuyo Nakatani
PDF
機械学習を使った時系列売上予測
by
DataRobotJP
PDF
DATUM STUDIO PyCon2016 Turorial
by
Tatsuya Tojima
PDF
KDD2014勉強会: Large-Scale High-Precision Topic Modeling on Twitter
by
sleepy_yoshi
あんちべのすべらない話~俺のツイートがこんなにウケないはずがない~
by
antibayesian 俺がS式だ
SVM実践ガイド (A Practical Guide to Support Vector Classification)
by
sleepy_yoshi
Pythonとdeep learningで手書き文字認識
by
Ken Morishita
Active Learning from Imperfect Labelers @ NIPS読み会・関西
by
Taku Tsuzuki
Active Learning 入門
by
Shuyo Nakatani
機械学習を使った時系列売上予測
by
DataRobotJP
DATUM STUDIO PyCon2016 Turorial
by
Tatsuya Tojima
KDD2014勉強会: Large-Scale High-Precision Topic Modeling on Twitter
by
sleepy_yoshi
What's hot
PDF
Mplusの使い方 初級編
by
Hiroshi Shimizu
PDF
ノンパラベイズ入門の入門
by
Shuyo Nakatani
PDF
よくわかる条件分岐
by
Noriyuki Ito
PDF
分類問題 - 機械学習ライブラリ scikit-learn の活用
by
y-uti
PPTX
特徴ベクトル変換器を作った話
by
Tokoroten Nakayama
PDF
Mplusの使い方 中級編
by
Hiroshi Shimizu
PDF
Pythonによる機械学習
by
Kimikazu Kato
PDF
TensorFlowによるニューラルネットワーク入門
by
Etsuji Nakai
PPTX
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
by
Shushi Namba
PDF
異常行動検出入門 – 行動データ時系列のデータマイニング –
by
Yohei Sato
PDF
機械学習の理論と実践
by
Preferred Networks
PDF
続・わかりやすいパターン認識 第7章「マルコフモデル」
by
T T
PDF
機会学習ハッカソン:ランダムフォレスト
by
Teppei Baba
PDF
論文紹介 Identifying Implementation Bugs in Machine Learning based Image Classifi...
by
y-uti
PDF
それっぽく感じる機械学習
by
Yuki Igarashi
PDF
Jubatusの特徴変換と線形分類器の仕組み
by
JubatusOfficial
PDF
第1回 Jubatusハンズオン
by
Yuya Unno
PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoWebmining#17
by
Yuya Unno
PDF
はてなインターン「機械学習」
by
Hatena::Engineering
PDF
TensorFlow を使った 機械学習ことはじめ (GDG京都 機械学習勉強会)
by
徹 上野山
Mplusの使い方 初級編
by
Hiroshi Shimizu
ノンパラベイズ入門の入門
by
Shuyo Nakatani
よくわかる条件分岐
by
Noriyuki Ito
分類問題 - 機械学習ライブラリ scikit-learn の活用
by
y-uti
特徴ベクトル変換器を作った話
by
Tokoroten Nakayama
Mplusの使い方 中級編
by
Hiroshi Shimizu
Pythonによる機械学習
by
Kimikazu Kato
TensorFlowによるニューラルネットワーク入門
by
Etsuji Nakai
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
by
Shushi Namba
異常行動検出入門 – 行動データ時系列のデータマイニング –
by
Yohei Sato
機械学習の理論と実践
by
Preferred Networks
続・わかりやすいパターン認識 第7章「マルコフモデル」
by
T T
機会学習ハッカソン:ランダムフォレスト
by
Teppei Baba
論文紹介 Identifying Implementation Bugs in Machine Learning based Image Classifi...
by
y-uti
それっぽく感じる機械学習
by
Yuki Igarashi
Jubatusの特徴変換と線形分類器の仕組み
by
JubatusOfficial
第1回 Jubatusハンズオン
by
Yuya Unno
Jubatusのリアルタイム分散レコメンデーション@TokyoWebmining#17
by
Yuya Unno
はてなインターン「機械学習」
by
Hatena::Engineering
TensorFlow を使った 機械学習ことはじめ (GDG京都 機械学習勉強会)
by
徹 上野山
Viewers also liked
PDF
全文検索入門
by
antibayesian 俺がS式だ
PDF
Pythonで簡単ネットワーク分析
by
antibayesian 俺がS式だ
PDF
さくさくテキストマイニング入門セッション
by
antibayesian 俺がS式だ
PDF
企業における統計学入門
by
antibayesian 俺がS式だ
PDF
ガチャとは心の所作
by
antibayesian 俺がS式だ
PDF
SPSSで簡単テキストマイニング
by
antibayesian 俺がS式だ
PDF
神の言語による自然言語処理
by
antibayesian 俺がS式だ
PDF
テキストマイニングのイメージと実際
by
antibayesian 俺がS式だ
PDF
チームラボ忘年会
by
antibayesian 俺がS式だ
PDF
Python東海Vol.5 IPythonをマスターしよう
by
Hiroshi Funai
PPTX
第1回茶ッカソン in Tokyo プレゼンシート「チームNifty」
by
kakusan40
PDF
Credential social media_live_v1_3
by
Social Media Live!
PDF
Credential twittorebiew v1.3
by
Social Media Live!
PDF
第1回茶ッカソン in Tokyo プレゼンシート「FULLER」
by
kakusan40
全文検索入門
by
antibayesian 俺がS式だ
Pythonで簡単ネットワーク分析
by
antibayesian 俺がS式だ
さくさくテキストマイニング入門セッション
by
antibayesian 俺がS式だ
企業における統計学入門
by
antibayesian 俺がS式だ
ガチャとは心の所作
by
antibayesian 俺がS式だ
SPSSで簡単テキストマイニング
by
antibayesian 俺がS式だ
神の言語による自然言語処理
by
antibayesian 俺がS式だ
テキストマイニングのイメージと実際
by
antibayesian 俺がS式だ
チームラボ忘年会
by
antibayesian 俺がS式だ
Python東海Vol.5 IPythonをマスターしよう
by
Hiroshi Funai
第1回茶ッカソン in Tokyo プレゼンシート「チームNifty」
by
kakusan40
Credential social media_live_v1_3
by
Social Media Live!
Credential twittorebiew v1.3
by
Social Media Live!
第1回茶ッカソン in Tokyo プレゼンシート「FULLER」
by
kakusan40
Similar to Sakusaku svm
PDF
Jubatusにおける大規模分散オンライン機械学習
by
Preferred Networks
PDF
コンピュータ先端ガイド2巻3章勉強会(SVM)
by
Masaya Kaneko
PDF
Pythonによる機械学習入門〜基礎からDeep Learningまで〜
by
Yasutomo Kawanishi
PDF
bigdata2012ml okanohara
by
Preferred Networks
PDF
R による文書分類入門
by
Takeshi Arabiki
PDF
判別分析
by
Satoru Yamamoto
PPTX
SVMについて
by
mknh1122
PDF
2013.07.15 はじパタlt scikit-learnで始める機械学習
by
Motoya Wakiyama
PDF
MapReduceによる大規模データを利用した機械学習
by
Preferred Networks
PDF
PoisoningAttackSVM (ICMLreading2012)
by
Hidekazu Oiwa
PPTX
第七回統計学勉強会@東大駒場
by
Daisuke Yoneoka
PPT
SVM&R with Yaruo!!
by
guest8ee130
PDF
パターン認識 第12章 正則化とパス追跡アルゴリズム
by
Miyoshi Yuya
PDF
機械学習
by
Hikaru Takemura
PDF
第1回 Jubatusハンズオン
by
JubatusOfficial
PPTX
集合知第7回
by
Noboru Kano
PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoNLP#9
by
Yuya Unno
PDF
Pfi last seminar
by
Hidekazu Oiwa
PPTX
0610 TECH & BRIDGE MEETING
by
健司 亀本
PDF
2013 JOI春合宿 講義6 機械学習入門
by
Hiroshi Yamashita
Jubatusにおける大規模分散オンライン機械学習
by
Preferred Networks
コンピュータ先端ガイド2巻3章勉強会(SVM)
by
Masaya Kaneko
Pythonによる機械学習入門〜基礎からDeep Learningまで〜
by
Yasutomo Kawanishi
bigdata2012ml okanohara
by
Preferred Networks
R による文書分類入門
by
Takeshi Arabiki
判別分析
by
Satoru Yamamoto
SVMについて
by
mknh1122
2013.07.15 はじパタlt scikit-learnで始める機械学習
by
Motoya Wakiyama
MapReduceによる大規模データを利用した機械学習
by
Preferred Networks
PoisoningAttackSVM (ICMLreading2012)
by
Hidekazu Oiwa
第七回統計学勉強会@東大駒場
by
Daisuke Yoneoka
SVM&R with Yaruo!!
by
guest8ee130
パターン認識 第12章 正則化とパス追跡アルゴリズム
by
Miyoshi Yuya
機械学習
by
Hikaru Takemura
第1回 Jubatusハンズオン
by
JubatusOfficial
集合知第7回
by
Noboru Kano
Jubatusのリアルタイム分散レコメンデーション@TokyoNLP#9
by
Yuya Unno
Pfi last seminar
by
Hidekazu Oiwa
0610 TECH & BRIDGE MEETING
by
健司 亀本
2013 JOI春合宿 講義6 機械学習入門
by
Hiroshi Yamashita
Sakusaku svm
1.
SakuSakuSVMで さくさくツイートマイニング!
2.
自己紹介 ●
ID:AntiBayesian ● あんちべ!とお呼び下さい ● 専門:テキストマイニング、自然言語処理 ● 職業:某ATMが○○な銀行で金融工学研究員とか いう胡散臭い素敵なことしてる ● 自然言語処理職大絶賛募集中!!!! ● math.empress@gmail.com 2
3.
twitterをマイニングしたい! tweet分析するとこんなことが出来る(かも?) 1.自分のtweetがウケルかどうかpostする前に予測 2.スパムアカウントを自動で見分けてスパム報告 3.デマ情報の抽出 4.盗作tweetかどうか判定 5.ネカマかどうか判定
3
4.
Postする前に
ウケルかどうか 判定してみたよ あんちべのすべらない話 ~俺のツイートがこんなにウケないはずがない~ http://www.slideshare.net/AntiBayesian/ss-8487534 4
5.
分析の流れ 1.学習データ(正例、負例)を用意する 2.学習データから予測モデルを立てる ➢
正例・負例の特徴を抽出し、どのような要素を持てば正 負のどちらかに判別出来るかを学習する 3.対象のtweetを予測モデルに放り込んで判定 ➢ 正例の特徴を強く持つtweetは正例のクラスへ、負例の 特徴を強く持つtweetは負例のクラスへ、分類器で自動 分類 5
6.
正例、負例の例 ●
スパムアカウントかどうか見分けたい ➢ 正例:スパムアカウント、負例:非スパムアカウント ● デマ情報かどうか判別したい ➢ 正例:デマtweet、負例:正しいtweet ● 正例・負例は逆でも良い(正:非スパム、負:スパム 等)。抽出したいものを正例にするケースが多い ● 重要なのは、やりたいことに応じてデータを収集 し、クラスを適切に設定すること 6
7.
やりたいことを決めよう! ●
自分のtweetがウケルか予測したい! ● もう渾身のネタが滑るのは嫌だ!!! ● じゃあデータは何が必要??? ● 正例:☆が沢山ついてるtweet、負例:☆ついてな いtweetにすると良いのでは??? 7
8.
学習データを集めよう ●
正例:favstarから人気tweetを取得 ● 負例:twitter Streaming APIから適当にサンプリン グ ● 正例負例、各々約3万件ずつチョイス ● 正例には1、負例には-1クラスタグを付ける ※Tweetを取得するツール作ったよ! http://d.hatena.ne.jp/AntiBayesian/20110702 8
9.
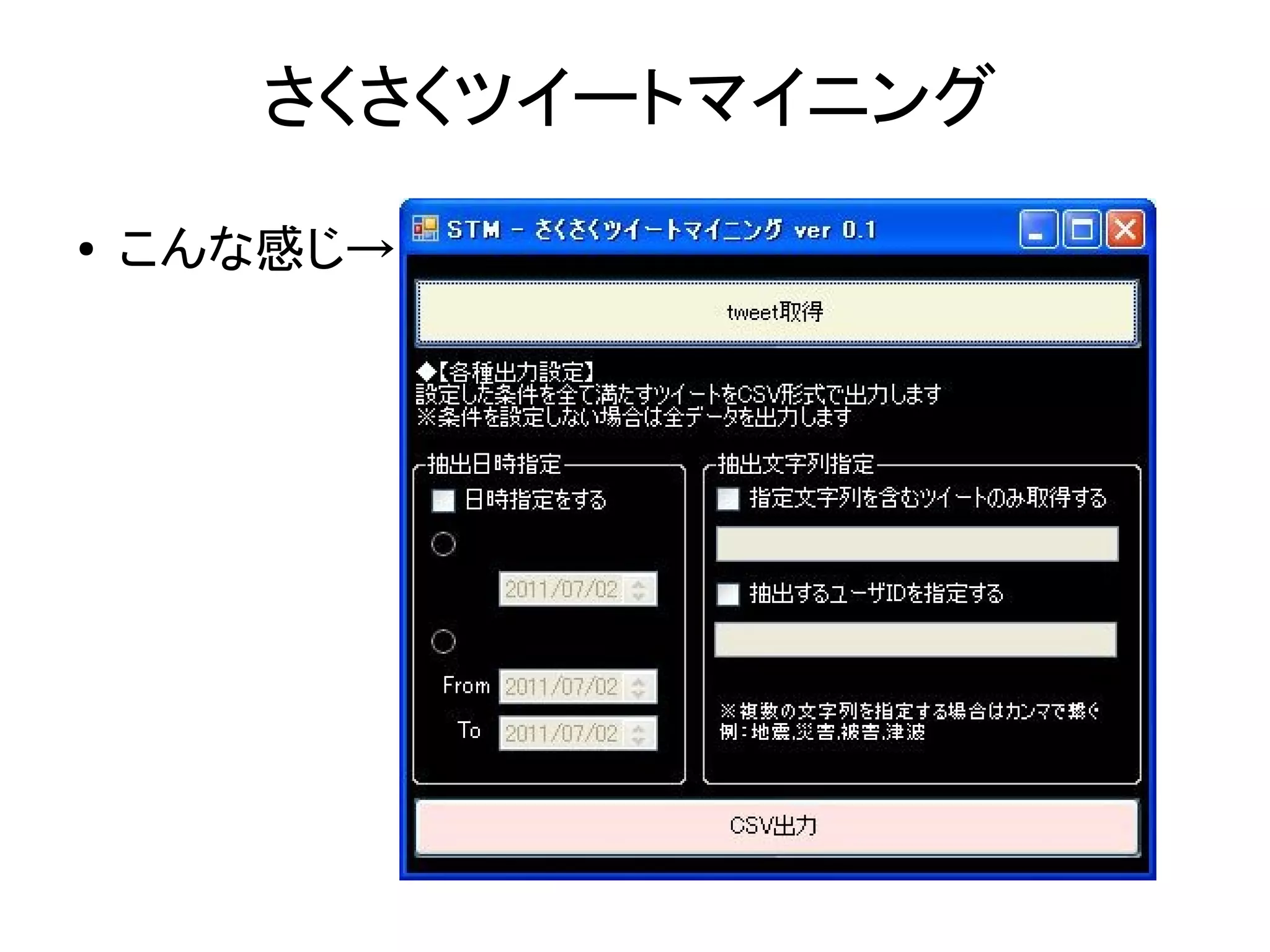
さくさくツイートマイニング ●
こんな感じ→
10.
学習データ
11.
テストデータ ● 実際に分類をしたいデータ
● クラスタグは仮置きする ※今回は精度を実感しやすくするため、fav, nonfav が判明しているものをテストデータに用いる。具体的 には、favstar, StreamingAPIから取得したデータのう ち、6月末までのもの約3万件を学習データに、7月以 降のもの約200件をテストデータに用いる。favの tweetがどれ位の精度でfavに分類されるか見る
12.
データ集めたし、 準備万端!!! さぁ分析するか!
12
13.
・・・
13
14.
どうやって???
14
15.
分類器って何??? ●
正負例から各々の特徴を抽出・学習して、与えた データの正負を自動で判別してくれるもの – 正負のデータ(答え)が予め用意されてる学習を、教師有り学 習と言う ● 様々な分類器がある ● ナイーブベイズ ● 決定木 ● パーセプトロン ● SVM(サポートベクターマシーン) ● 今回はSVMを使うよ! 15
16.
なぜSVMを使うの??? ●
現在大変よく使われてる手法 ● 超パワフル ● テキストデータは高次元になりがち。SVMは高次 元の分類に強み ● 沢山の種類・工夫が既にあり、探せば良いのが幾 らでも見つかる ● “超平面”とか”次元の呪い”とか”カーネルトリック” とか、出てくる単語が格好良くて中二病をくすぐる 16
17.
SVMとは??? ●
データを高次元に写像して分類する手法 “サポートベクターマシンは、本来は線形分離不可能な問題には適用で きない。 しかし、再生核ヒルベルト空間の理論を取り入れたカーネル関 数を用いてパターンを有限もしくは無限次元の特徴空間へ写像し、特 徴空間上で線形分離を行う手法が 1992年に Vladimir Vapnik らに よって提案された。 これにより、非線形分類問題にも優れた性能を発揮 することがわかり、近年特に注目を集めている。 なお、カーネル関数を取り入れた一連の手法では、どのような写像が行 われるか知らずに計算できることから、カーネルトリック (Kernel Trick) と呼ばれている” by Wikipedia 17
18.
ヽ(・∀・ヽ) ワッケ!! (ノ・∀・)ノ ワッカ!! ヽ(・∀・)ノ
ラン!! 18
19.
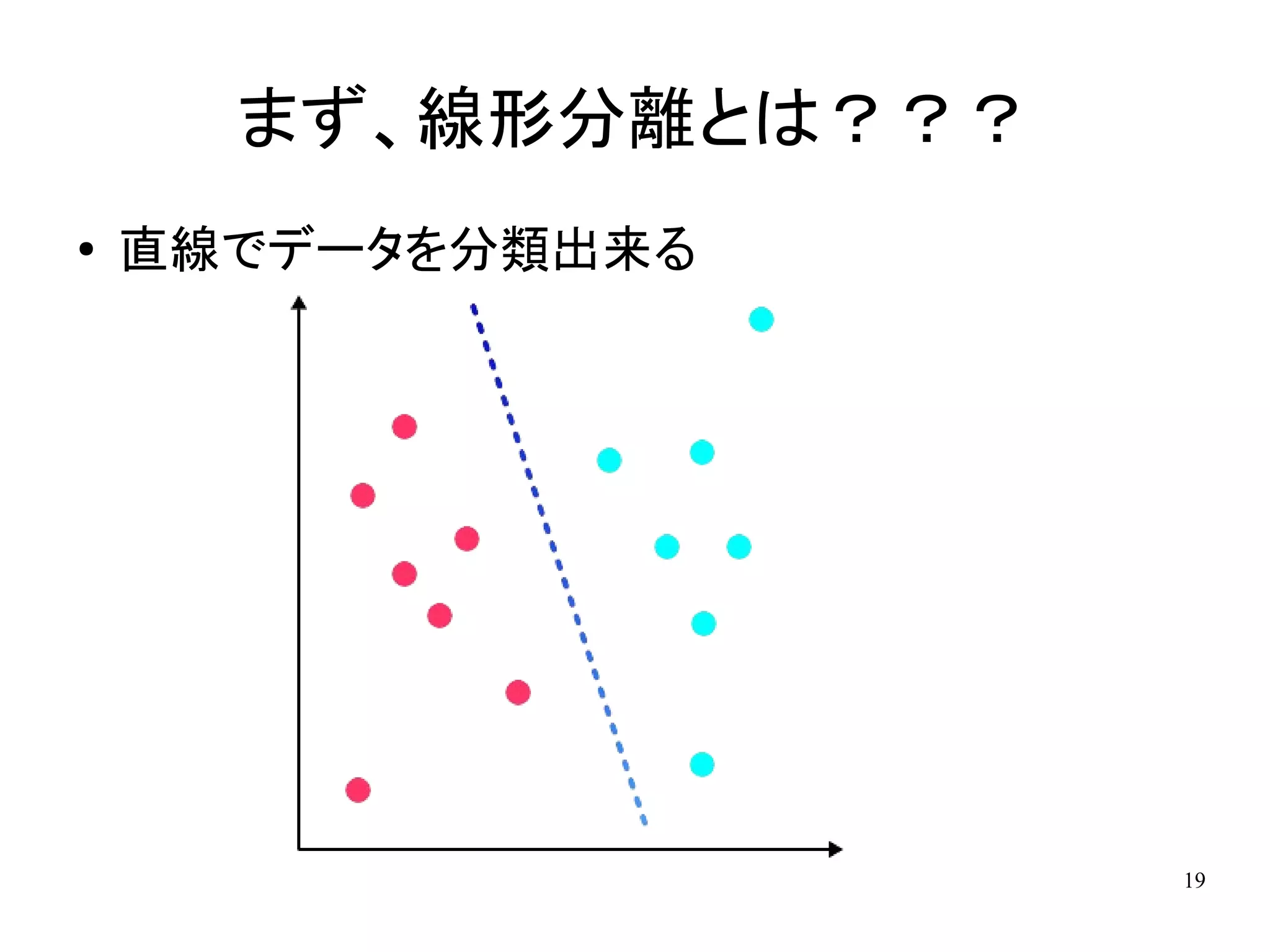
まず、線形分離とは??? ●
直線でデータを分類出来る 19
20.
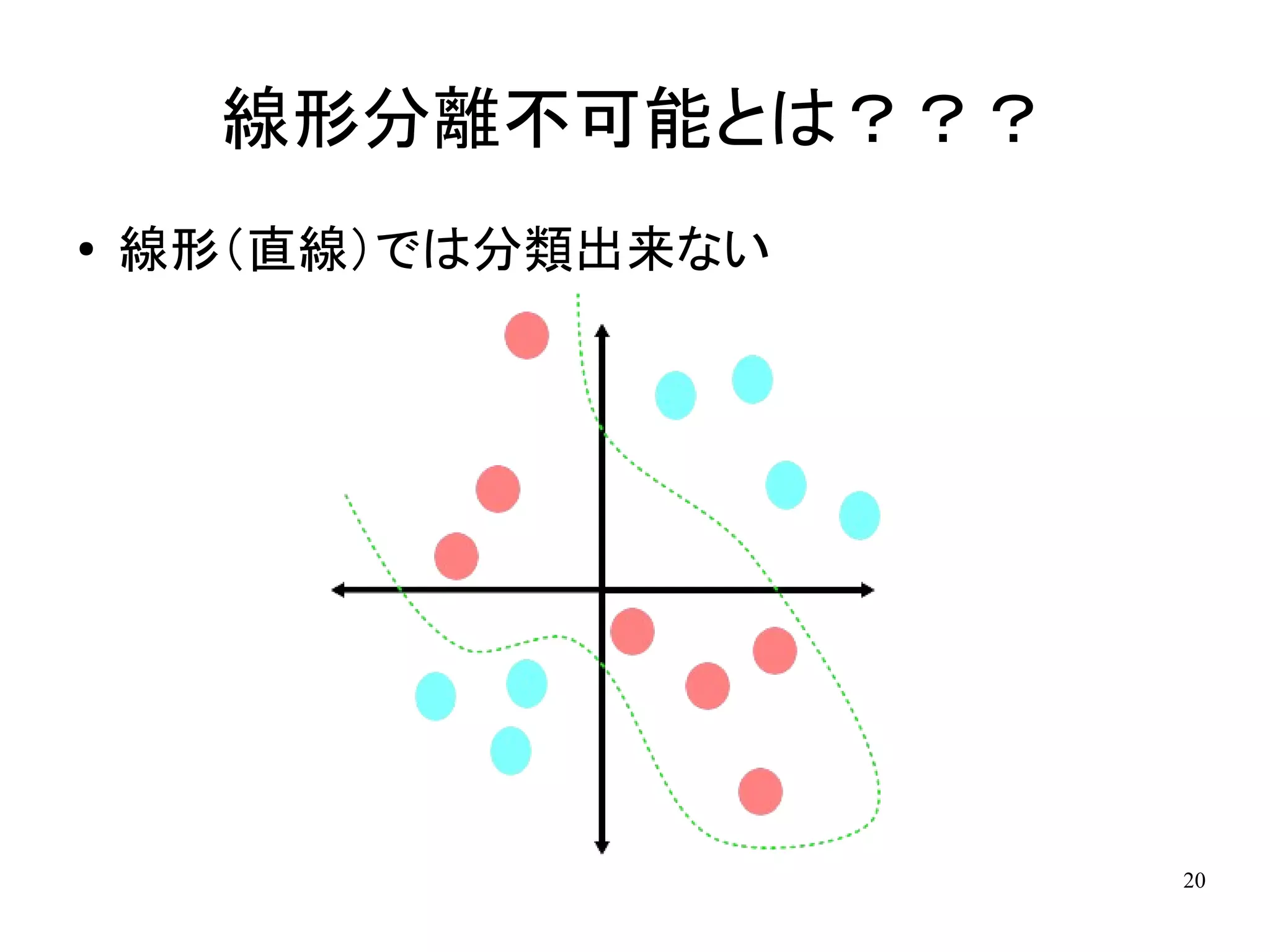
線形分離不可能とは??? ●
線形(直線)では分類出来ない 20
21.
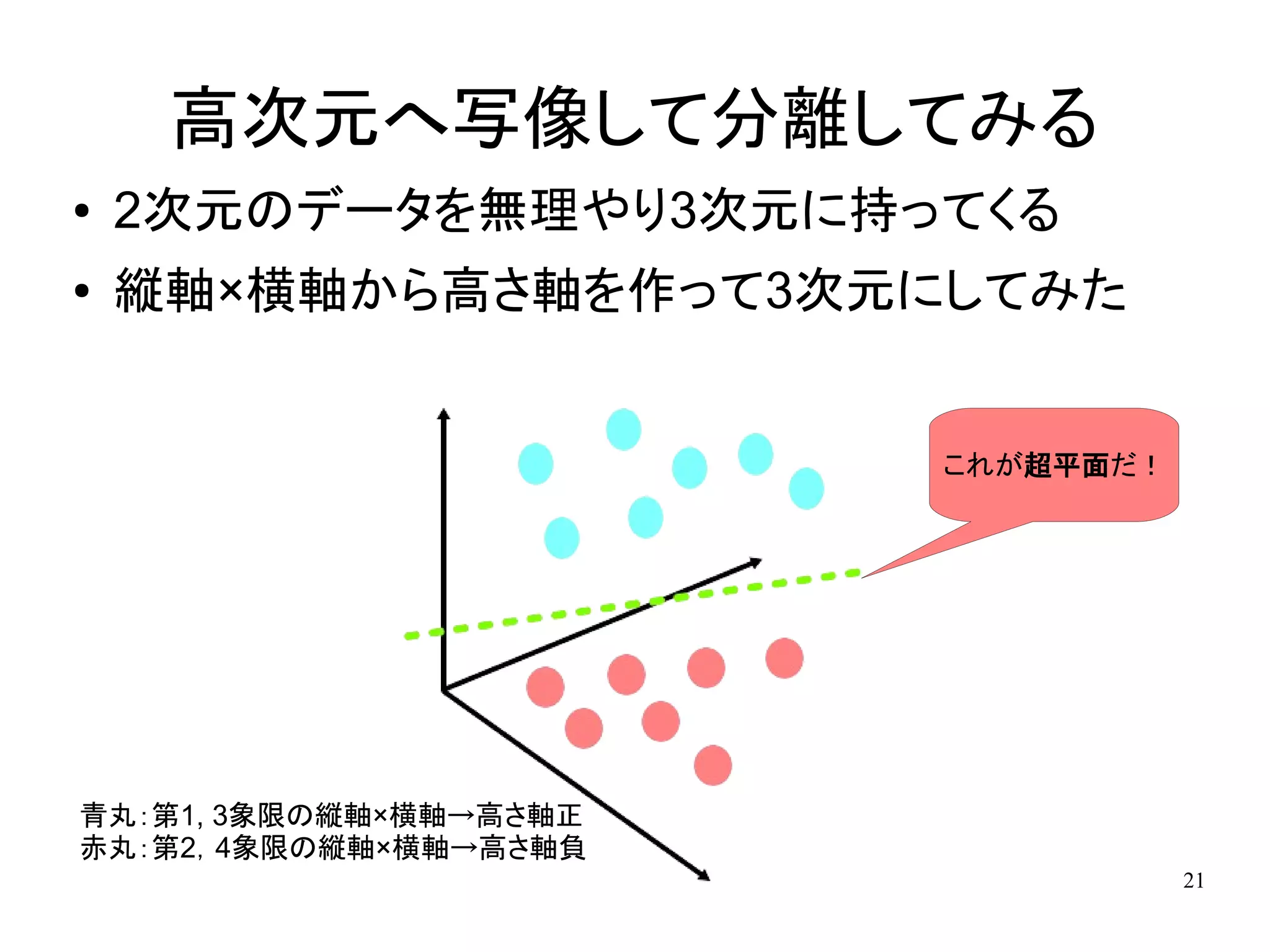
高次元へ写像して分離してみる ●
2次元のデータを無理やり3次元に持ってくる ● 縦軸×横軸から高さ軸を作って3次元にしてみた これが超平面だ! 青丸:第1, 3象限の縦軸×横軸→高さ軸正 赤丸:第2,4象限の縦軸×横軸→高さ軸負 21
22.
SVMすごい!!!! ●
高次元に写像すれば、線形分離不可能なものも分 類出来る! ● かっこいい! ● つおい!!! ● すごい!!! ● 使ってみるしかない!!!! ● じゃあ数式見て実装しよう!!! 22
23.
数式難しすぎて 人間が死ぬ
ハードマージンのSVMは簡単だけど、 カーネルトリックの世界に踏み込むと結構厳しい 23
24.
SakuSaku-SVM作ったよ! ●
GUIテキストマイニング用ツール ● 前処理とSVMが実行可能 ● SVMエンジンはliblinear(高速な線形分類器) ● 分かち書きはtinySegmenter ● WndowsXP、.NET Framework3.0以上で動作 ● http://www24.atpages.jp/antibayesian/app/の SSSVM.zipをDL 24
25.
SS-SVM前処理で生成されるファイル ●
テキストの統計処理 ● 2gram:学習データのバイグラム ● WordSet:学習データに含まれる単語 ● WordCount:学習データの単語頻度(昇順 ● SVM用ファイル ● SVM_train:SVM学習用 ● SVM_test:SVMテスト用 25
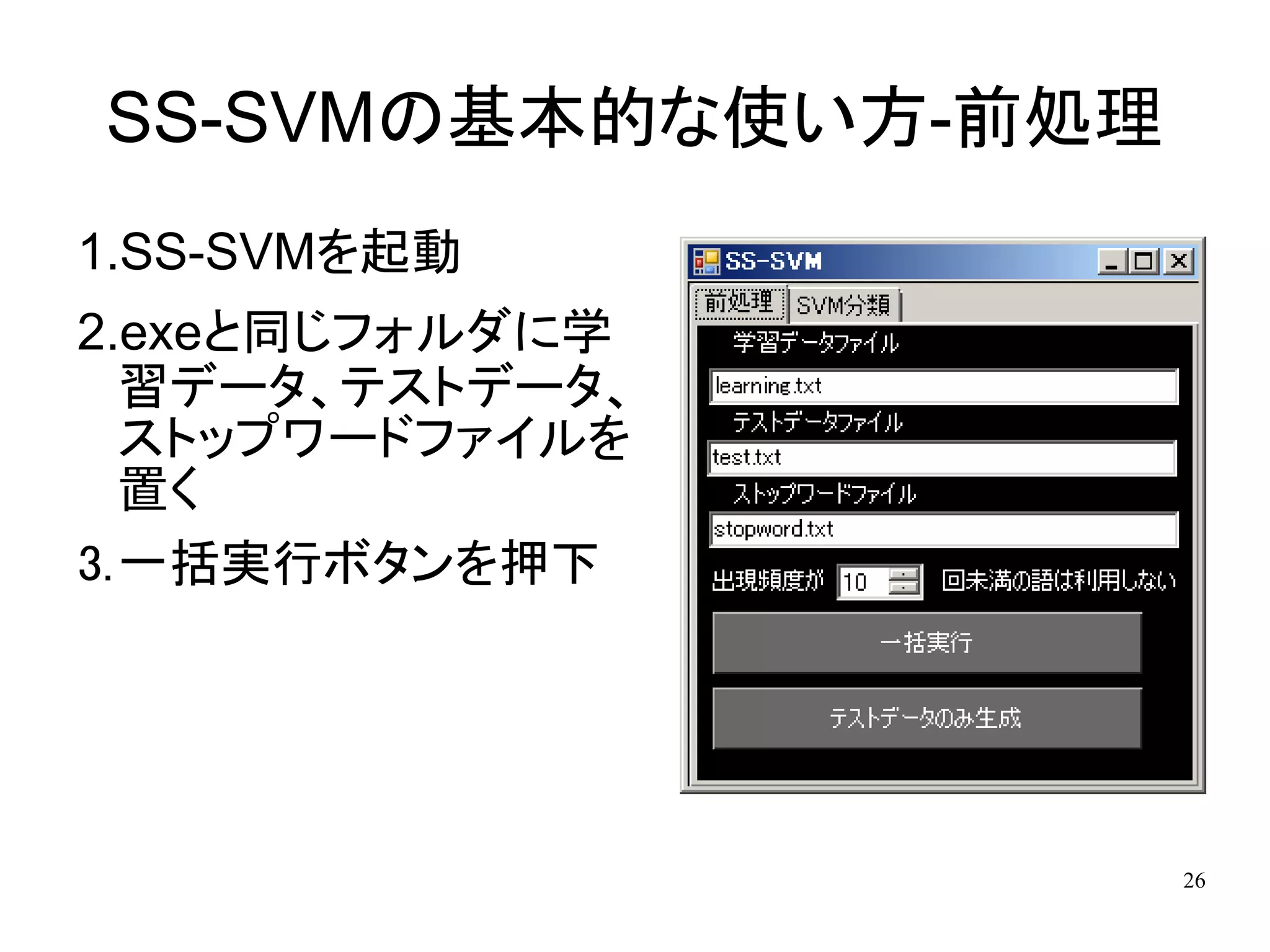
26.
SS-SVMの基本的な使い方-前処理 1.SS-SVMを起動 2.exeと同じフォルダに学 習データ、テストデータ、
ストップワードファイルを 置く 3.一括実行ボタンを押下 26
27.
SS-SVMの基本的な使い方-SVM 4.クロスバリデーションボタン押 下。CrossValidation.txtからモ
デルの説明力を見る(これが 低すぎたら前処理やり直し) 5.モデル生成ボタン押下 6.分類実行ボタン押 下。Output.txtで分類結 果、Accuracy.txtで分類精度 を確認 27
28.
SVMの結果の見方 ●
Accuracy.txt ● 仮置きのタグとSVM分類で付与したタグのマッチング 率。今回は仮置きタグが正しいとみなせる状況であるた め、精度と考えて差し支えない ● Output.txt ● 各行のtweetが正負どちらに判定されたか、タグで表わ される。n行目に1と出力されていた場合、n行目の tweetは1クラス(今回の例ではfav tweet)に分類された という意味 28
29.
やってみた結果 ●
調整したら86%の精度でfav, nonfav分類出来た ● nonfav側に分類されがちな感じ – なぜかを考えてみよう! ● favなのにnonfavと分類されたtweetは、他所への リンク物が多い。そりゃ分類難しいわ… ● nonfavなのにfavに分類されたtweet、結構面白い – ゴルゴ 「俺の後ろから押すなよ絶対に押すなよ」 – 母『暑くてスルメになりそう』…スルメ?w ● 割とイケル気がしてきた 29
30.
工夫して精度を上げよう! 1.やりたいこととデータがマッチしてるか考え直す 2.学習データ数を増やす ➢
2000件→6万件にすると、精度が77→82%に 3.出現頻度下限を調整する 4.ストップワードファイル(除去単語リスト)を修正する 30
31.
まとめ ●
tweetからスパム判定とか色んなことが出来る ● やりたいことに応じて、何が正負例データに該当す るかよく考えなくてはならない ● SVMという高次元・非線形分離にも対応したパワ フルな分類器がある ● SS-SVMを使うと、テキストの前処理からSVM実行 までマウスクリックだけで出来る ● 簡単にSVM出来るんだから、もうやるっきゃない! 31
Download