2017年11月1日 第5回JubatusハンズオンのJubakitの説明資料 Jubakitの基本的な使い方、scikit-learn wrapperの使い方、embedded jubatusの使い方を紹介












![学習・予測を行う
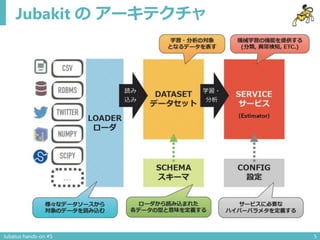
Jubatus hands-on #5 14
for _ in classifier.train(dataset_train):
pass
y_true, y_pred = [], []
for (idx, label, result) in
classifier.classify(dataset_test):
y_true.append(label)
y_pred.append(result[0][0])
通常のJubatusと同様に、train/classifyを呼ぶ](https://image.slidesharecdn.com/jubakit-171101103540-171102023731/85/Jubakit-14-320.jpg)
![学習・予測を行う
Jubatus hands-on #5 15
for _ in classifier.train(dataset_train):
pass
y_true, y_pred = [], []
for (idx, label, result) in
classifier.classify(dataset_test):
y_true.append(label)
y_pred.append(result[0][0])
学習を行う (yieldなのでfor文を回す)](https://image.slidesharecdn.com/jubakit-171101103540-171102023731/85/Jubakit-15-320.jpg)
![学習・予測を行う
Jubatus hands-on #5 16
for _ in classifier.train(dataset_train):
pass
y_true, y_pred = [], []
for (idx, label, result) in
classifier.classify(dataset_test):
y_true.append(label)
y_pred.append(result[0][0])
予測結果を取得する
確信度の最も高いラベルを取るにはresult[0][0]](https://image.slidesharecdn.com/jubakit-171101103540-171102023731/85/Jubakit-16-320.jpg)











![[第2版]Python機械学習プログラミング 第9章](https://cdn.slidesharecdn.com/ss_thumbnails/09-181212011914-thumbnail.jpg?width=640&height=640&fit=bounds)









































































