










![代表的なビッグデータ処理理基盤:Google中⼼心
GFS/MapReduce (Hadoop) 分散ファイルシステム + MapReduceフ
[Google 2004] レームワーク
分散処理理 分散ロックサーバー,
Chubby (Zookeeper)
基盤 [Google 2006] 分散システムの調整役
Spanner データセンター間の⼀一貫性制御
[Google 2012] 数百万台のマシンを制御
BigTable (HBase) スケールアウト可能な列列志向のKVS
[Google 2006]
DB/データ Dynamo ⾼高可⽤用性、スケールアウト可能な KVS
ストア [Amazon 2007]
MegaStore トランザクション機能付きKVS
[Google 2011]
Hive SQL経由で利利⽤用可能なHadoop
[Facebook 2009]
OLAP/分析 Dremel (Apache Drill) OLAP向け, 列列志向 + スタースキーマ
ツール [Google 2010]
PowerDrill OLAP向け 列列志向 + スタースキーマ +
[Google 2012] 圧縮 + オンメモリ
…OSS, サービスでは未登場](https://image.slidesharecdn.com/121207jubatuscomsysdist-130118000855-phpapp01/85/Jubatus-15-320.jpg)


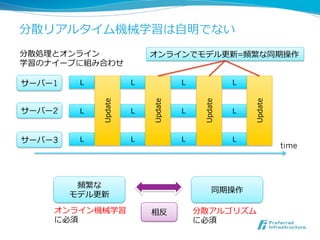
![Jubatusの先進性と差別化要因:
⼤大規模/分散並列列かつオンライン/リアルタイム
• Structured Perceptron オンライン
2011年年現在
[Collins, EMNLP 2002] (リアルタイム)
• Passive Aggressive / 存在しなかった
MIRA 2004〜~
この分野に
• online-‐‑‒learning library
[岡野原, 2008] フォーカス!
⼩小規模 ⼤大規模
単体 分散並列列
WEKA
1993-‐‑‒
SVM light Mahout
1998-‐‑‒ 2006-‐‑‒
バッチ
18](https://image.slidesharecdn.com/121207jubatuscomsysdist-130118000855-phpapp01/85/Jubatus-18-320.jpg)

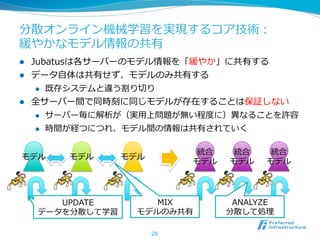
![これまでのビッグデータ処理理基盤の普及
l OSSで存在するシステムはGoogleから⾒見見れば4〜~6年年遅れている
l 実際に社内で利利⽤用されはじめてから論論⽂文が出るまで1〜~2年年
l OSS化され安定するまで3〜~4年年、普及するのに2〜~3年年
l Jubatusは今のところ実⽤用的な類似処理理基盤が存在せず
≪Hadoopの例例≫
GFS/MapReduceがGoogle社内 Hadoopの10000コアでの利利⽤用
で利利⽤用され始める 事例例 [Yahoo!]
2003 2004 2005 2006 2007 2008 2009 2010 2011
MapReduce論論⽂文が公開 他社での利利⽤用事例例加速
OSSであるHadoop 開発開始 Hadoopエコシステムができる
20](https://image.slidesharecdn.com/121207jubatuscomsysdist-130118000855-phpapp01/85/Jubatus-20-320.jpg)





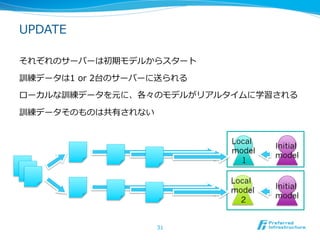
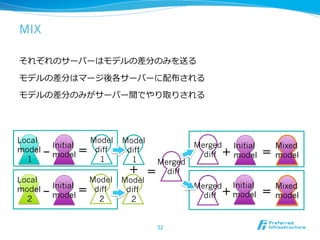
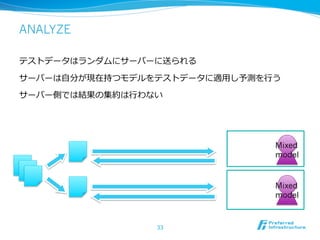

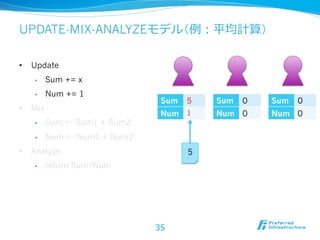
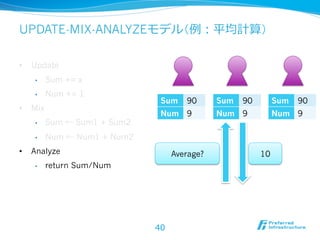
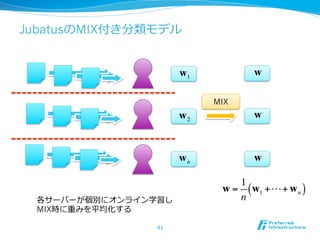
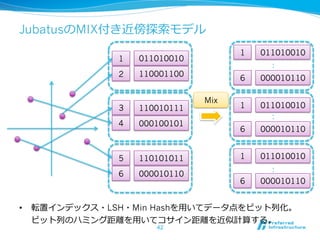

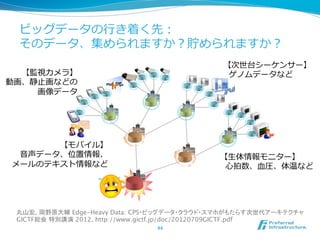

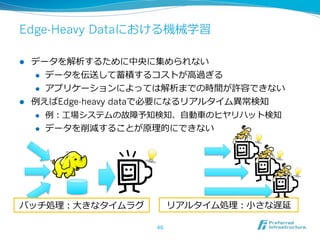
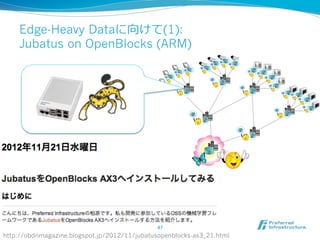
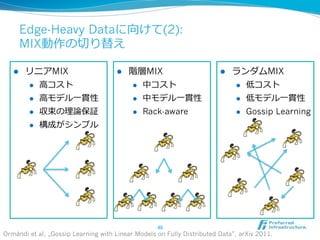
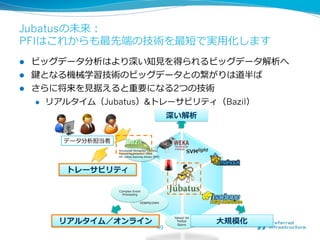


2012/12/7にComSysで招待講演した際のプレゼン資料です。2013/1時点でのJubatusに関する全部入り資料になっています。 概要:Hadoopは非常に成功した大規模データの分散処理基盤である一方、データを貯めないリアルタイム処理や、統計的な手法で知見や予測モデルを得る機械学習技術のサポートは限定的である。Jubatusは、それらHadoopに足りない「分散・リアルタイム・機械学習」を実現するためのOSSフレームワークとして2011年にリリースされた。その技術的特徵は、オンライン学習アルゴリズムを分散化し、かつ分散環境でコストの高いデータ共有を排除してコンパクトな機械学習モデルのみを緩やかに共有するMix操作を中心とした計算アーキテクチャを採用していることにある。本講演ではその動作原理を中心にJubatusの裏側を紹介する。
























































![[R勉強会][データマイニング] R言語による時系列分析](https://cdn.slidesharecdn.com/ss_thumbnails/r-100423232629-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






























