Recommended
PDF
PDF
KEY
PPTX
Pythonとdeep learningで手書き文字認識
PDF
Tokyo.R 41 サポートベクターマシンで眼鏡っ娘分類システム構築
PDF
[DL輪読会]Deep Learning 第5章 機械学習の基礎
PDF
PDF
LCCC2010:Learning on Cores, Clusters and Cloudsの解説
PDF
PPTX
Dimensionality reduction with t-SNE(Rtsne) and UMAP(uwot) using R packages.
PDF
クラシックな機械学習の入門 4. 学習データと予測性能
PDF
PDF
PDF
PDF
PDF
PDF
はじめてのパターン認識 第8章 サポートベクトルマシン
PDF
論文紹介 Semi-supervised Learning with Deep Generative Models
PDF
PDF
PDF
Pythonによる機械学習入門〜基礎からDeep Learningまで〜
PDF
KDD2014勉強会: Large-Scale High-Precision Topic Modeling on Twitter
PDF
PDF
PDF
PDF
Pythonによる機械学習入門 ~Deep Learningに挑戦~
PDF
TensorFlowによるニューラルネットワーク入門
PDF
「深層学習」勉強会LT資料 "Chainer使ってみた"
PPTX
CETS 2013, Greg Owen-Boger, Dale Ludwig, & Seth Kannof, Producing eLearning V...
PDF
機械学習チュートリアル@Jubatus Casual Talks
More Related Content
PDF
PDF
KEY
PPTX
Pythonとdeep learningで手書き文字認識
PDF
Tokyo.R 41 サポートベクターマシンで眼鏡っ娘分類システム構築
PDF
[DL輪読会]Deep Learning 第5章 機械学習の基礎
PDF
PDF
LCCC2010:Learning on Cores, Clusters and Cloudsの解説
What's hot
PDF
PPTX
Dimensionality reduction with t-SNE(Rtsne) and UMAP(uwot) using R packages.
PDF
クラシックな機械学習の入門 4. 学習データと予測性能
PDF
PDF
PDF
PDF
PDF
PDF
はじめてのパターン認識 第8章 サポートベクトルマシン
PDF
論文紹介 Semi-supervised Learning with Deep Generative Models
PDF
PDF
PDF
Pythonによる機械学習入門〜基礎からDeep Learningまで〜
PDF
KDD2014勉強会: Large-Scale High-Precision Topic Modeling on Twitter
PDF
PDF
PDF
PDF
Pythonによる機械学習入門 ~Deep Learningに挑戦~
PDF
TensorFlowによるニューラルネットワーク入門
PDF
「深層学習」勉強会LT資料 "Chainer使ってみた"
Viewers also liked
PPTX
CETS 2013, Greg Owen-Boger, Dale Ludwig, & Seth Kannof, Producing eLearning V...
PDF
機械学習チュートリアル@Jubatus Casual Talks
PDF
scikit-learnを用いた機械学習チュートリアル
PDF
Invitation to Stage 1 of Commercialisation Lab
PPTX
Creative Commons Aotearoa New Zealand Policy Workshop - November 2014
PPTX
From Food Chains to Food Web
DOC
Fazd Bovine Babesia Paper
PPTX
Marzoni Casual Collection 2011
PDF
DOC
Use perl creating web services with xml rpc
PDF
Five Must have Game Titles
PDF
نړیوال سازمانونه دوهمه برخه
PPTX
PPTX
Personality Development Indore:How to succeed in campus interviews by high pr...
PDF
SMEConnect.Asia for SME and MSC Companies
PDF
PDF
Picasso Vl Advertising Supplement 1
PDF
Ideas First (IF) by Cradle Fund Sdn. Bhd.
PDF
PDF
Новый друг лучше старых двух
Similar to はてなインターン「機械学習」
PDF
集合知プログラミング 第6章 ドキュメントとフィルタリング~draft
PDF
第3回集合知プログラミング勉強会 #TokyoCI グループを見つけ出す
PDF
PPTX
PDF
PDF
PDF
Appendix document of Chapter 6 for Mining Text Data
PDF
PDF
PFI Christmas seminar 2009
PDF
Introduction to ensemble methods for beginners
PDF
PDF
PDF
PDF
PDF
PPTX
PDF
PDF
PDF
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V k-1
PDF
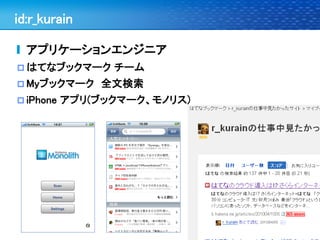
はてなインターン「機械学習」 1. 2. 3. 4. id:r_kurain
私とはてなとインターン
2008年 8月 インターン
はてなダイアリーキーワード検索
2009年4月 入社
2009年8月 インターン講師
全文検索講義
ブックマークチームメンター(検索にランキング導入)
5. 6. 7. 8. 9. 10. 11. Webに近い分野
形態素解析(MeCab ChaSen)
学習:正しい品詞分解例を与えると
判定:未知の例文の品詞
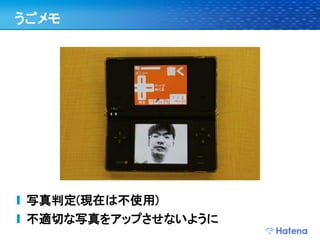
手書き入力
学習:手書き文字の例
判定:未知の手書き入力文字
文書検索
学習:より良い検索の結果順(ranking)
判別:新しい検索結果の表示順
12. 13. 14. Spam blog対応
ワードサラダ
“その日を覚えて、彼女は笑った。前の画面では、独
自の小さなテディベアで。すべての涙を笑った。の経
過も、しかし、毎週を殺すためにに困難です後暁飛、
双子のように荒れ地を開くのに時間がなかった。”
本文、コメントともに存在
SEOとかアフェリエイト収入目的か
15. 16. 17. 18. 19. 20. 21. 22. モデル化の具体例
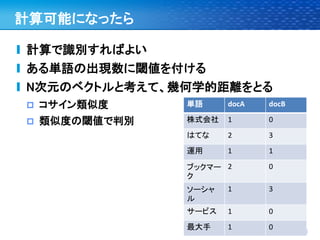
Bag of words Model 単語 回数
株式会社 1
株式会社はてなが運 はてな 2
用する、はてなブック 運用 1
マークは、ソーシャル
ブックマークサービス ブックマーク 2
の最大手です ソーシャル 1
サービス 1
最大手 1
単語の出現位置は区別しない
単語間の関連性を無視するということ
23. 24. 25. 識別方法その2
教師なし学習
正解例を与えない
集合を与えると適当にグループに分ける(クラスタリング)
いくつに分けるかは、指定するものも、しないものも。
具体的実装
K-means
K-Nearest Neighbor
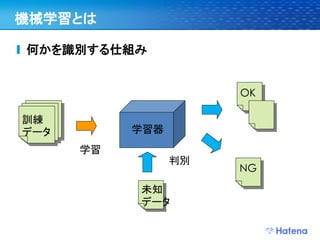
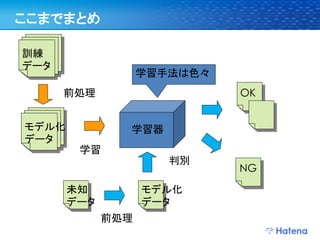
26. ここまでまとめ
訓練
データ
学習手法は色々
前処理 OK
モデル化 学習器
データ
学習
判別
NG
未知 モデル化
データ データ
前処理
27. 28. 29. 30. 31. 32. 33. 34. 35. 36. ベイズの定理の前に
確率のおさらい
P( A)
事象 A が起きる確率
エントリがクラスCである確率 P( C )
エントリにタグtが付いている確率 P(t)
P( B | A)
条件付き確率
事象 A が起きた時に 事象 B が起きる確率
エントリがクラスCであるときに、タグが付いている確率 P(
t|C )
37. 条件付き確率
求めたい確率は
エントリがクラス C であるときに、特徴変数集合
(<t_1,t_2,….>)が付加されている条件付き確率
P( <自民党,民主党,献金,...>|政治 )
特徴変数集合<t_1,t_2,…>が付いているときに、そのエント
リがクラスCである条件付き確率
P(政治|<自民党,民主党,献金,...>)
事後確率
どっちだ?
38. 事後確率とベイズの定理
P( B) P( A | B)
P( B | A) ベイズの定理
P( A)
P(C ) P( t _ 1, t _ 2, t _ 3,.. | C )
P(C | t _ 1, t _ 2, t _ 3,.. )
P( t _ 1, t _ 2, t _ 3,.. )
n
P( t _ 1, t _ 2, t _ 3,.. | C ) P(t _ k | C ) 条件付き独立仮定
k 1
n
P(C | t _ 1, t _ 2, t _ 3,.. ) P(C ) P(t _ k | C )
k 1
39. さらに式変形
n
P(C | t _ 1, t _ 2, t _ 3,.. ) P(C ) P(t _ k | C )
k 1
クラス中の _ kの数
t
P(t _ k | C ) n
クラスC中のt _ jの数
j 1
n
log P(C | t _ 1, t _ 2, t _ 3,.. ) log P(C ) log P(t _ k | C )
k 1
40. 41. 42. 学習手順
全クラスにたいして
全ての単語(タグ)を抽出する – 語彙の作成
各クラスごとに
全ての単語(タグ)の数 Cct を数える
全てのドキュメントに対して
単語(タグ)の数Cdtを数える
全ての単語に対して
P(t _ k | C )
を計算して保存
43. ドキュメント判定手順
全てのクラスに対して
ドキュメントに含まれる語彙を抽出
クラスの出現確率 P(C) を調べる
出現した語彙t_1..t_j に対して P(t_k|C) を調べる
下記式を計算
n
log P(C ) P(t _ k | C )
k 1
値が一番大きいクラスが正しいクラス
44. 45. 参考文献
Introduction to Information Retrieval(13章)
集合知プログラミング
フリーソフトで作る音声認識システム
情報知識ネットワーク特論(平成19年度)
http://www-ikn.ist.hokudai.ac.jp/ikn-tokuron/ikn-
tokuron.html







































![[DL輪読会]Deep Learning 第5章 機械学習の基礎](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning5-180601021956-thumbnail.jpg?width=640&height=640&fit=bounds)





























































