コミュニティの偉大な貢献
• 実用化に向けてハードルが下がる
– ここ数年で、計算資源(HWリソース)×豊富なデータ×アルゴリズム進歩=
機械学習がビジネスシーンに広がってきた
– 十分な精度、コストが低く、入手しやすい、人間にできないことができる
• ユーザー会やコミュニティ、個人の貢献が偉大
User Groups and R Awareness(*1) Local R User Group Directory(*2)
*1: http://blog.revolutionanalytics.com/2016/05/user-groups-and-r-awareness.html
*2: http://blog.revolutionanalytics.com/local-r-groups.html
15
(サンプルコード) 2 of4
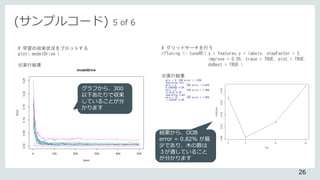
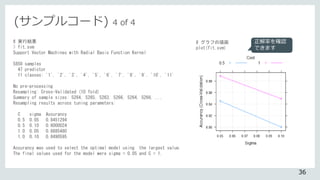
# 実行結果
> fit.rf
Random Forest
5850 samples
48 predictor
11 classes: '1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11'
No pre-processing
Resampling: Bootstrapped (25 reps)
Summary of sample sizes: 5850, 5850, 5850, 5850, 5850, 5850, ...
Resampling results across tuning parameters:
mtry Accuracy Kappa
2 0.9920029 0.9911994
17 0.9772760 0.9749927
32 0.9685406 0.9653798
48 0.9636917 0.9600440
Accuracy was used to select the optimal model using the largest value.
The final value used for the model was mtry = 2.
# グラフの描画
plot(fit.rf)
正解率を確認
できます
34
(サンプルコード) 4 of4
# 実行結果
> fit.svm
Support Vector Machines with Radial Basis Function Kernel
5850 samples
47 predictor
11 classes: '1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11'
No pre-processing
Resampling: Cross-Validated (10 fold)
Summary of sample sizes: 5264, 5265, 5263, 5266, 5264, 5266, ...
Resampling results across tuning parameters:
C sigma Accurancy
0.5 0.05 0.8451294
0.5 0.10 0.8000024
1.0 0.05 0.8885480
1.0 0.10 0.8490595
Accurancy was used to select the optimal model using the largest value.
The final values used for the model were sigma = 0.05 and C = 1.
# グラフの描画
plot(fit.svm)
正解率を確認
できます
36
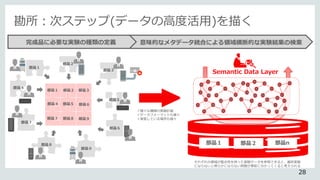
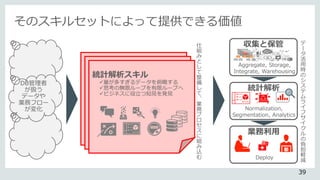
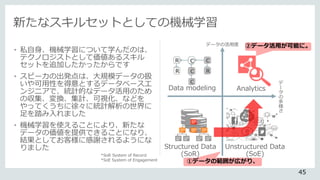
データの活用度
デ
ー
タ
の
多
様
さ
R C
C
C
C RR
②データ活用が可能に。
AnalyticsDatamodeling
Structured Data
(SoR)
Unstructured Data
(SoE)
①データの範囲が広がり、
*SoR System of Record
*SoE System of Engagement
45
• 私自身、機械学習について学んだのは、
テクノロジストとして価値あるスキル
セットを追加したかったからです
• スピーカの出発点は、大規模データの扱
いや可用性を得意とするデータベースエ
ンジニアで、統計的なデータ活用のため
の収集、変換、集計、可視化、などを
やってくうちに徐々に統計解析の世界に
足を踏み入れました
• 機械学習を使えることにより、新たな
データの価値を提供できることになり、
結果としてお客様に感謝されるようにな
りました
新たなスキルセットとしての機械学習








![# R version 3.2.5 (2016-04-14) -- "Very, Very Secure Dishes“
# サンプルではデータ加工部分は省略
# ライブラリの読み込み
library( mgm )
library( qgraph )
# データの読み込み
setwd( "作業ディレクトリを指定" )
data <- read.table( "data.txt", sep = "¥t", header= FALSE )
data <- apply( data, 2, as.integer )
dif <- read.table( "dif.txt", sep = "¥t", header= FALSE )
data_colnames <- as.matrix( dif[1,] )
type <- as.matrix( dif[2,] )
lev <- apply( dif[3,], 1, as.integer )
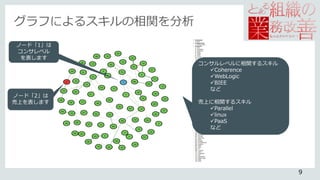
# 混合グラフモデルの実行
fit <- mgmfit( data, type, lev, d = 1 )
groups_typeV <- list( "Gaussian"=which(type=='g' ),
"Categorical"=which(type=='c' ),
"Poisson"=which(type=='p' ))
group_col <- c( "#ED3939", "#53B0CF", "#72CF53" )
# プロットする
jpeg( "SkillGraph.jpg", height=2*1700, width=2*2000, unit='px' )
Q0 <- qgraph( fit$wadj,
vsize=3.5,
esize=2,
layout="spring",
edge.color = fit$edgecolor,
color=group_col,
border.width=1.5,
border.color="black",
groups=groups_typeV,
nodeNames=data_colnames,
legend=TRUE,
legend.mode="style2",
legend.cex=1.5 )
dev.off()
(サンプルコード) 37 Step
ライブラリの詳細は、以下のリンクをご参照ください。
http://arxiv.org/pdf/1510.06871v2.pdf
10](https://image.slidesharecdn.com/20160602ocdmtokyor4mlslidesharev10-160602140809/85/Oracle-Cloud-Developers-Meetup-10-320.jpg)
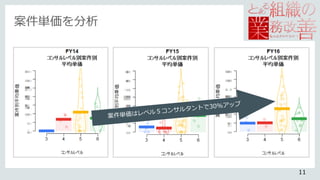
![(サンプルコード)
# プロットする
pirateplot(formula = FY ~ ConsLevel,
data = data,
xlab = "コンサルレベル",
ylab = "案件別平均単価",
main = "FYyy¥nコンサルレベル別案件別¥n平均単価",
pal = "google",
point.o = .2,
line.o = 1,
theme.o = 2,
line.lwd = 10,
point.pch = 16,
point.cex = 1.5,
jitter.val = .1,
ylim = c(0, 35)
)
axis( side = 1, labels = F )
axis( side = 2, labels = F )
26 Step
# R version 3.2.5 (2016-04-14) -- "Very, Very Secure Dishes"
# サンプルではデータ加工部分は省略
# ライブラリの読み込み
library( "devtools" )
install_github( "ndphillips/yarrr" )
library( "yarrr" )
# データの読み込み
setwd("作業ディレクトリを指定")
data <- read.table("data.txt", sep="¥t",header=T)
data <- data[order(data$ConsLevel), ]
ライブラリの詳細は、以下のリンクをご参照ください。
http://nathanieldphillips.com/2016/04/pirateplot-2-0-the-rdi-plotting-choice-of-r-pirates/
12](https://image.slidesharecdn.com/20160602ocdmtokyor4mlslidesharev10-160602140809/85/Oracle-Cloud-Developers-Meetup-12-320.jpg)





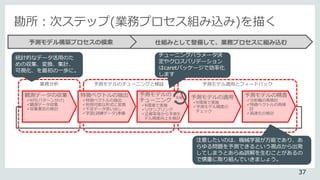
![モデルのチューニングと検証
• 予測モデルの構築では、テストデータを基に、得られた法則性が意
図したものになっているかを確認します。最良のモデルを得るため、
同じ機械学習アルゴリズムを異なる設定や複数種類の特徴ベクトル
形式で動作させたり、複数の機会学習アルゴリズムで学習したモデ
ルを比較する事を行います。本セッションではrandomForestパッ
ケージのアプローチについてご紹介します。
• ご注意
– なお、事例のデータは公開できないため、カリフォルニア大学アーバイン校のセンサーデー
タのデータセット(*1)で代替している点をご了承ください。事前にデータセットをダウンロー
ドして、zipファイルを展開します。
– https://archive.ics.uci.edu/ml/machine-learning-databases/00325/Sensorless_drive_diagnosis.txt
*1 https://archive.ics.uci.edu/ml/datasets.html
Citation Policy
Lichman, M. (2013). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml].
Irvine, CA: University of California, School of Information and Computer Science.
21](https://image.slidesharecdn.com/20160602ocdmtokyor4mlslidesharev10-160602140809/85/Oracle-Cloud-Developers-Meetup-21-320.jpg)

![# モデル作成のために、トレーニング用データセットを生成する
# 元データの10%をトレーニングデータとしてサンプリング抽出
set.seed( 100 )
smpl <- sample( nrow( drive ), 0.1 * nrow( drive ))
train <- drive[smpl, ]
# 残りをテストデータ用データセットとする
test <- drive[-smpl, ]
# データセットを特徴量とラベルに分割する
features <- train[1:48]
labels <- train[49]
# ラベルをファクターに変換する
labels <- as.factor( labels[[1]] )
# モデルを作成する
modelDrive <- randomForest( x=features, y=labels, importance=T, proximity=T )
モデルの汎化性能を向上させるために、
クロスバリデーションを実行します
(サンプルコード) 3 of 6
24](https://image.slidesharecdn.com/20160602ocdmtokyor4mlslidesharev10-160602140809/85/Oracle-Cloud-Developers-Meetup-24-320.jpg)
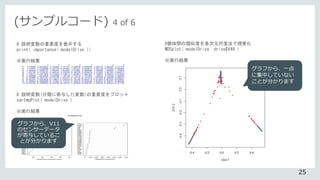
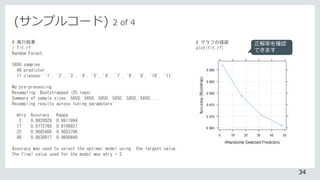
![# 木の数と特徴量の数を変えて再実行する
modelDrive <- randomForest( x = features, y = labels, mtry = 3,
ntree = 300, importance = T )
# テストデータにモデルを適用する
prdct <- predict( modelDrive, newdata = test )
table( prdct, test$V49 )
※実行結果
# 正確さの確認
correctAns <- 0
for ( i in 1:nrow( table( prdct, test$V49 )))
correctAns <- correctAns + table(prdct, test$V49)[i,i]
correctAns / nrow( test )
※実行結果
結果から、 99.5パーセント
の精度を達成しました。ちな
みに、再実行前のモデルの場
合、[1] 0.9915684でした。
(サンプルコード) 6 of 6
27](https://image.slidesharecdn.com/20160602ocdmtokyor4mlslidesharev10-160602140809/85/Oracle-Cloud-Developers-Meetup-27-320.jpg)


![モデルのチューニングと検証
• データが変わっても予測モデルの性能が大きく変わらないように、複数のアル
ゴリズムやクロスバリデーションなどのリサンプリング手法を用いた予測モデ
ルを構築する必要があります。そのようなときは、caretパッケージやmlrパッ
ケージを用いることで作業を効率化することができます。
• たとえば、以下のような作業の作業ステップを減らすことが可能です。
– グリッドサーチによってチューニングパラメータを変化させながら最適な予測モデルを構築
する
– クロスバリデーションなどのリサンプリングを変化させながら最適な予測モデルを構築する
• 本セッションではcaretパッケージを使用したアプローチについてご紹介します。
• ご注意
– なお、事例のデータは公開できないため、カリフォルニア大学アーバイン校のセンサーデータのデータセット
(*1)で代替している点をご了承ください。事前にデータセットをダウンロードして、zipファイルを展開します。
– https://archive.ics.uci.edu/ml/machine-learning-databases/00325/Sensorless_drive_diagnosis.txt
*1 https://archive.ics.uci.edu/ml/datasets.html
Citation Policy
Lichman, M. (2013). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml].
Irvine, CA: University of California, School of Information and Computer Science.
32](https://image.slidesharecdn.com/20160602ocdmtokyor4mlslidesharev10-160602140809/85/Oracle-Cloud-Developers-Meetup-32-320.jpg)
![(サンプルコード) 1 of 4
# R version 3.2.5 (2016-04-14) -- "Very, Very Secure Dishes"
# ランダムフォレスト
# ワーキングディレクトリの指定
setwd( "作業ディレクトリを指定" )
# ライブラリの読み込み
library( caret )
# データの読み込み
data <- "Sensorless_drive_diagnosis.txt"
drive <- read.table( data )
# モデル作成のために、トレーニング用データセットを生成する
# 元データの10%をトレーニングデータとしてサンプリング抽出
set.seed( 100 )
smpl <- sample( nrow( drive ), 0.1 * nrow( drive ))
train <- drive[smpl, ]
#データセットを特徴量とラベルに分割する
features <- train[1:48]
labels <- train[49]
#ラベルをファクターに変換する
labels <- as.factor( labels[[1]] )
# モデルを作成する
fit.rf <- train(x=features, y=labels, method="rf",
ntree = 100, importance = T,
tuneGrid = NULL, tuneLength = 4)
33](https://image.slidesharecdn.com/20160602ocdmtokyor4mlslidesharev10-160602140809/85/Oracle-Cloud-Developers-Meetup-33-320.jpg)
![(サンプルコード) 3 of 4
#サポートベクタマシン
# ワーキングディレクトリの指定
setwd( "作業ディレクトリを指定" )
# ライブラリの読み込み
library( caret )
# データの読み込み
data <- "Sensorless_drive_diagnosis.txt"
drive <- read.table( data )
# モデル作成のために、トレーニング用データセットを生成する
# 元データの10%をトレーニングデータとしてサンプリング抽出
set.seed( 100 )
smpl <- sample( nrow( drive ), 0.1 * nrow( drive ))
train <- drive[smpl, ]
#データセットを特徴量とラベルに分割する
features <- train[1:48]
labels <- train[49]
#ラベルをファクターに変換する
labels <- as.factor( labels[[1]] )
# 評価関数の作成
eval.summary <- function(data, lev=NULL, model=NULL){
conf <- table(data$pred, data$obs)
correctAns <- sum(diag(conf))/sum(conf)
out <- c(Accurancy=correctAns)
out
}
# モデルを作成する
fit.svm <- train(labels~., data=features, method="svmRadial",
trace=T, tuneGrid=expand.grid(.C=c(0.5, 1.0),
.sigma=c(0.05, 0.1)), trControl=trainControl
(summaryFunction=eval.summary, method="cv",
number=10)
)
35](https://image.slidesharecdn.com/20160602ocdmtokyor4mlslidesharev10-160602140809/85/Oracle-Cloud-Developers-Meetup-35-320.jpg)





![[データマイニング+WEB勉強会][R勉強会] はじめてでもわかる 統計解析・データマイニング R言語入門](https://cdn.slidesharecdn.com/ss_thumbnails/rlecturehamada100213-100216161757-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

































































