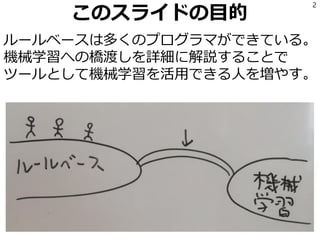
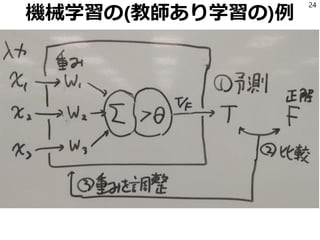
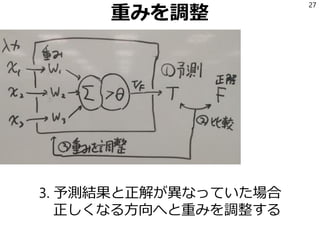
正解データを読んでLRを学習
40
file_yes = codecs.open(‘XXX.txt','r', 'utf-8')
file_no = codecs.open('not_XXX.txt', 'r', 'utf-8')
xs = []
ys = []
for line in file_yes:
line = preprocess(line)
xs.append(make_feature_vector(line))
ys.append(1)
for line in file_no:
line = preprocess(line)
xs.append(make_feature_vector(line))
ys.append(0)
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(xs, ys)
41.
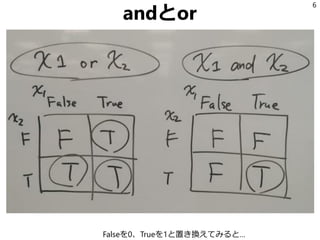
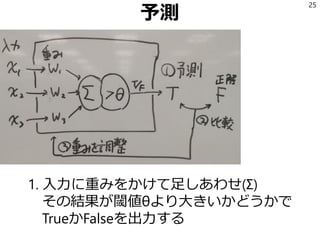
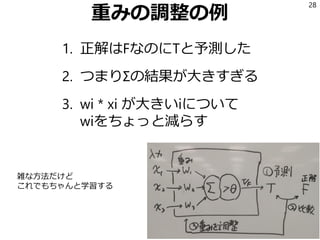
特徴ベクトルの作り方
41
from rules importrules
def make_feature_vector(s):
fv = []
for f in rules:
rs = f(s)
if rs:
fv.append(1)
else:
fv.append(0)
return fv
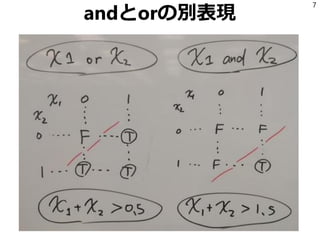
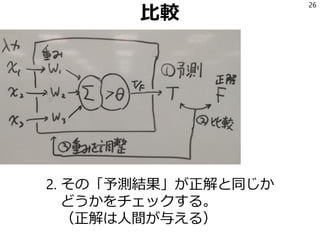
対話的に学習データを追加
44
unknown = codecs.open(‘SOMETHING.txt','r', 'utf-8')
buf = []
for line in unknown:
s = preprocess(line)
v = make_feature_vector(s)
score = model.predict_proba(v)[0][1]
buf.append((abs(0.5 - score), score, s, line))
buf.sort()
for _dum, score, s, line in buf:
print u"{:.2f}".format(score),
print line.strip()
yn = raw_input('y/n?>')
if yn == 'y':
codecs.open(‘XXX.txt', 'a', 'utf-8').write(line)
elif yn == 'n':
codecs.open('not_XXX.txt', 'a', 'utf-8').write(line)
else:
print 'passed'

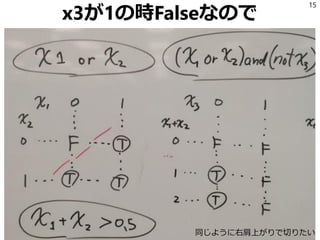
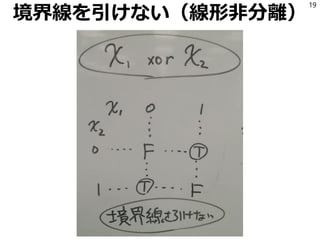
![「ルール」とは
将来的にいろいろな抽象化がされるが
今のところは「TrueかFalseを返すコード」
と思っていい。
3
if (これはルール) { … }
def foo(x):
… return True
return False
# これもルール
*.py[cod]
*$py.class
*.so
env/
.eggs/
正規表現の羅列もルール](https://image.slidesharecdn.com/random-150926113541-lva1-app6891/85/slide-3-320.jpg)


























![正解データを読んでLRを学習
40
file_yes = codecs.open(‘XXX.txt', 'r', 'utf-8')
file_no = codecs.open('not_XXX.txt', 'r', 'utf-8')
xs = []
ys = []
for line in file_yes:
line = preprocess(line)
xs.append(make_feature_vector(line))
ys.append(1)
for line in file_no:
line = preprocess(line)
xs.append(make_feature_vector(line))
ys.append(0)
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(xs, ys)](https://image.slidesharecdn.com/random-150926113541-lva1-app6891/85/slide-40-320.jpg)
![特徴ベクトルの作り方
41
from rules import rules
def make_feature_vector(s):
fv = []
for f in rules:
rs = f(s)
if rs:
fv.append(1)
else:
fv.append(0)
return fv](https://image.slidesharecdn.com/random-150926113541-lva1-app6891/85/slide-41-320.jpg)


![対話的に学習データを追加
44
unknown = codecs.open(‘SOMETHING.txt', 'r', 'utf-8')
buf = []
for line in unknown:
s = preprocess(line)
v = make_feature_vector(s)
score = model.predict_proba(v)[0][1]
buf.append((abs(0.5 - score), score, s, line))
buf.sort()
for _dum, score, s, line in buf:
print u"{:.2f}".format(score),
print line.strip()
yn = raw_input('y/n?>')
if yn == 'y':
codecs.open(‘XXX.txt', 'a', 'utf-8').write(line)
elif yn == 'n':
codecs.open('not_XXX.txt', 'a', 'utf-8').write(line)
else:
print 'passed'](https://image.slidesharecdn.com/random-150926113541-lva1-app6891/85/slide-44-320.jpg)





![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)




































![[第2版] Python機械学習プログラミング 第1章](https://cdn.slidesharecdn.com/ss_thumbnails/python-machine-learning-2nd-edition-01-180905090109-thumbnail.jpg?width=640&height=640&fit=bounds)


![[輪講] 第1章](https://cdn.slidesharecdn.com/ss_thumbnails/random-171231020415-thumbnail.jpg?width=640&height=640&fit=bounds)


























