Recommended
PDF
PPTX
ODP
PPTX
20180903_apply_alexa_skill_award
PDF
PDF
PPTX
PDF
PDF
FIT2012招待講演「異常検知技術のビジネス応用最前線」
PDF
まだCPUで消耗してるの?Jubatusによる近傍探索のGPUを利用した高速化
PPTX
PDF
PDF
PPTX
ODP
PDF
PDF
PPTX
PDF
PDF
PPTX
PDF
PDF
PPTX
PPTX
PPTX
PDF
コンテンツマーケティングでレコメンドエンジンが必要になる背景とその活用
PPTX
PDF
PDF
More Related Content
PDF
PPTX
ODP
PPTX
20180903_apply_alexa_skill_award
PDF
PDF
PPTX
PDF
Viewers also liked
PDF
FIT2012招待講演「異常検知技術のビジネス応用最前線」
PDF
まだCPUで消耗してるの?Jubatusによる近傍探索のGPUを利用した高速化
PPTX
PDF
PDF
PPTX
ODP
PDF
PDF
PPTX
PDF
PDF
PPTX
PDF
PDF
PPTX
PPTX
PPTX
PDF
コンテンツマーケティングでレコメンドエンジンが必要になる背景とその活用
PPTX
More from JubatusOfficial
PDF
PDF
PPTX
PDF
PPTX
Jubatus使ってみた 作ってみたJubatus
PDF
データ圧縮アルゴリズムを用いたマルウェア感染通信ログの判定
PPTX
PDF
Jubatusでuserとbrandのレコメンドを試してみた話
PDF
発言小町からのプロファイリング 1. 2. 3. 入力データ
発言小町
User ID
User Name
Date
Title
Url
Topic Id
Group
Message
Votes
Responses
Face
n_response
n_favorite
発言小町からとってきたデータ
とりあえず、約10,500件
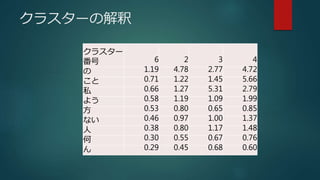
4. 5. クラスターの解釈
クラスター
番号 6 2 3 4
の 1.19 4.78 2.77 4.72
こと 0.71 1.22 1.45 5.66
私 0.66 1.27 5.31 2.79
よう 0.58 1.19 1.09 1.99
方 0.53 0.80 0.65 0.85
ない 0.46 0.97 1.00 1.37
人 0.38 0.80 1.17 1.48
何 0.30 0.55 0.67 0.76
ん 0.29 0.45 0.68 0.60
6. 7. 8. 9. 10. Use the source,
Luke!
Jubatus coreのソース読む
get_clusters綾しい
If (clusters.empty()) {
throw
JUBATUS_EXCEPTION(not_perfo
rmed());
}
なぜに空っぽ!ガンガンガン!
ドキュメントがあるわけでもな
く謎
11. ハイパーパラメー
タを洗ってみる
eps : 2.0,
min_core_point : 3
Density-Based Spatial Clustering
Applications with Noise
EpsとMinPtsの二つのハイパーパラ
メータ
とりあえず怪しくなさそう
困った