More Related Content

PDF

PDF

PDF

PPTX

PDF

PDF

PPTX
Jubatus Casual Talks #2: 大量映像・画像のための異常値検知とクラス分類 
PDF
What's hot

PPTX
前回のCasual Talkでいただいたご要望に対する進捗状況 
PDF
2013.07.15 はじパタlt scikit-learnで始める機械学習 
PDF

PDF
分類問題 - 機械学習ライブラリ scikit-learn の活用 
PDF

PDF
Pythonによる機械学習入門 ~Deep Learningに挑戦~ 
PDF
Deep Learning Implementations: pylearn2 and torch7 (JNNS 2015) 
PDF
Tokyo.R 41 サポートベクターマシンで眼鏡っ娘分類システム構築 
PDF
Pythonによる機械学習入門〜基礎からDeep Learningまで〜 
PDF

PPTX
SensorBeeでChainerをプラグインとして使う 
PDF

PPTX
Jupyter NotebookとChainerで楽々Deep Learning 
PDF
Pythonによる機械学習入門 ~SVMからDeep Learningまで~ 
PDF
Deep Learningハンズオン勉強会「Caffeで画像分類を試してみようの会」 
PPTX

PDF
論文紹介 Identifying Implementation Bugs in Machine Learning based Image Classifi... 
PDF
Chainer の Trainer 解説と NStepLSTM について 
PDF
「深層学習」勉強会LT資料 "Chainer使ってみた" 
PDF
TensorFlowの使い方(in Japanese) Viewers also liked

PDF

PPTX

PDF

PDF
Jubatusをベースにしたオーディエンスの分析エンジンの紹介 
PDF

PDF

PDF
Jubatus Casual Talks #2 Jubatus開発者入門 
PPTX
Jubatus Casual Talks #2 : 0.5.0の新機能(クラスタリング)の紹介 
PDF

PDF

PDF
A use case of online machine learning using Jubatus 
PDF
Jubatus Casual Talks #2 異常検知入門 
PDF
機械学習チュートリアル@Jubatus Casual Talks 
PPTX
Demystifying Systems for Interactive and Real-time Analytics 
PDF
Jubatus talk at HadoopSummit 2013 
PPTX
Hadoop Turns a Corner and Sees the Future 
PDF
世界征服を目指すJubatusだからこそ期待する5つのポイント 
PDF

PPTX

ODP
Similar to Jubatus使ってみた 作ってみたJubatus

PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoNLP#9 
PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoWebmining#17 
PDF
まだCPUで消耗してるの?Jubatusによる近傍探索のGPUを利用した高速化 
PDF

PPT

PDF
More from JubatusOfficial

PPTX

PDF

PDF

PDF

PDF

PPTX

PPTX

PDF

PPTX

PPTX

PPTX

PPTX

PDF
コンテンツマーケティングでレコメンドエンジンが必要になる背景とその活用 
PDF

PDF

PDF

PDF
データ圧縮アルゴリズムを用いたマルウェア感染通信ログの判定 
PDF

PDF

PPTX
Jubatus使ってみた 作ってみたJubatus
- 1.
- 2.
概要
使ってみた
ミドルウェアとして利用するにあたり各機能を検証
今回は0.5.0で追加された機能について、精度・性能を紹介
- 近傍探索機能
- クラスタリング機能
ここはなんとかならないか
作ってみた
とある機能をJubatusをフレームワークとして利用して実装
フレームワークとしての利用法を紹介
ここはどうにかならないか
対象バージョン:Jubatus 0.5.4
本発表の内容は、0.6.0にも基本的には適用できる、はず
1
- 3.
近傍探索機能の特徴
三つの手法を利用可能
MinHash
-集合としての類似度(Jaccard index)を近似
- ただし実数値も投入可能
LSH (Locality Sensitive Hashing)
- 特徴ベクトル同士のコサイン距離を近似
Euclid LSH
- ハッシュ値に加えてベクトルのノルムを保存して距離計算する
recommenderとの違い
投入された特徴ベクトル自体は保持しないので省メモリ
2
- 4.
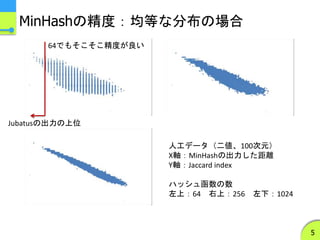
MinHashの実装の特徴1
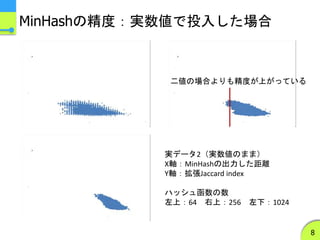
非負実数値に対して拡張されたMinHash法を利用
OndrejChum et al., "Near duplicate image detection: min-hash and tf-
idf weighting", BMVC 2008
元々のJaccard index
- intersection(Sa, Sb) / union(Sa, Sb)
まず整数に対して拡張する
- 特徴ベクトルa中の特徴fa
iが値nをとるとき、n個の異なる要素に展開し
た集合S'aを作る
- intersection(S'a, S'b) = sumi(min(fa
i, fb
i))
- union(S'a, S'b) = sumi(max(fa
i, fb
i))
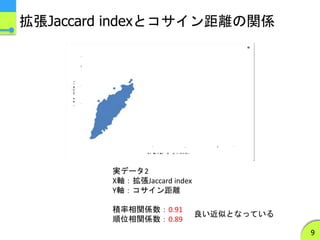
この式は実数値に対してもそのまま使える
- 本発表ではこの手法による類似度を「拡張Jaccard index」とよぶ
- コサイン距離のそこそこ良い近似になっている
拡張Jaccard indexを近似するハッシュ函数を利用
- h(fa
i) = -log x / fa
i, where x <- uniform(0, 1)
- もっともこのハッシュ函数はfa
i, fb
iが同じ値か0をとる場合の近似だが…
3
- 5.
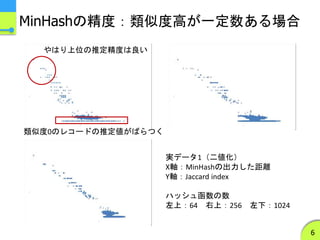
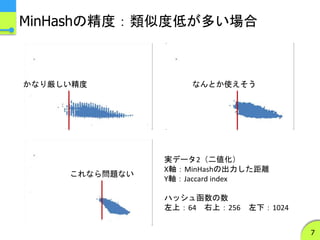
MinHashの実装の特徴2
b-bit minwisehashing
Ping Li, Arnd Christian König, "b-bit minwise hashing", WWW 2010
ハッシュ値の下位bビットのみを保持する
- Jubatusでは1ビットのみを保持している
精度が下がる分、ハッシュ函数の数を増やす
- 元よりもかなり少ない容量で同等の精度を達成できる
- Jubatusでは設定ファイルのhash_numでハッシュ函数の数を指定する
類似度が低くなる程、類似度の推定値の分散が大きくなるという
性質がある
- 1ビットの場合、ランダムでも確率0.5で一致するので…
4
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
LSHの実装の特徴
random projectionによるLSH
特徴ベクトルがランダムな超平面に対してどちら側に属するか、
によってビットベクトルを作る
- Jubatusでは設定ファイルのhash_numにより射影回数を指定する
ビットベクトル同士のハミング距離により近傍探索
特徴ベクトル同士のコサイン距離を反映した近傍探索結果となる
ことが期待される
10
- 12.
- 13.
近傍探索機能の性能
近傍探索速度
MinHash
-100万件、ハッシュ函数の数が256の場合、400ミリ秒あまり
- 特徴ベクトルの特性に関わらず一定
- ハッシュ函数の数が64の場合2倍程度高速
LSH:MinHashの1割程度高速
データ投入速度
MinHash
- 1万件、ハッシュ函数の数が256の場合、約20分
- ただし特徴ベクトルの次元数に依存
- かなり次元数の多いデータを入れて計測している
- ハッシュ函数の数が64の場合3倍程度高速
LSH:MinHashの2倍程度高速
メモリ消費量
100万件、ハッシュ函数の数が256の場合、200 MB程度
12
- 14.
クラスタリング機能の特徴
二つの手法が実装されている
k-means
GMM (Gaussian Mixture Model):ここでは扱わない
k-meansの実装の特徴
一定数のレコードが投入される毎にバッチで全レコードに対して
クラスタリングを行う
- bucket_size毎にクラスタリング
初期配置はk-means++で決定
コアセットによりレコード数を圧縮する
- bucket_size毎にcompressed_bucket_sizeに圧縮
- compressed_bucketがbucket_length個貯まったらもう一段圧縮
- 圧縮の段数が次第に増えていく仕組み
- cf. 位取り記法
- 理論的にはレコード数はO(log n)で増加するはずだが、実装の問題によ
りO(n)で増加している
13
- 15.
クラスタリング機能の性能
14
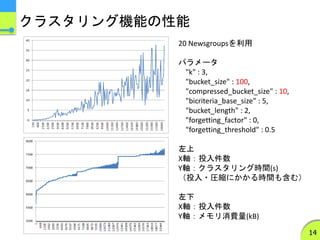
20 Newsgroupsを利用
パラメータ
"k" :3,
"bucket_size" : 100,
"compressed_bucket_size" : 10,
"bicriteria_base_size" : 5,
"bucket_length" : 2,
"forgetting_factor" : 0,
"forgetting_threshold" : 0.5
左上
X軸:投入件数
Y軸:クラスタリング時間(s)
(投入・圧縮にかかる時間も含む)
左下
X軸:投入件数
Y軸:メモリ消費量(kB)
- 16.
コアセットが線形に成長する問題
再帰的な圧縮を行う部分
圧縮後の件数として指定する値が大きいため、再帰的な圧縮が実
質的に機能しておらず、対数的な成長にならない
jubatus/core/clustering/compressive_storage.cpp
void compressive_storage::carry_up(size_t r)
15
if (!is_next_bucket_full(r)) {
/****/
} else {
wplist cr = mine_[r];
wplist crr = mine_[r + 1];
mine_[r].clear();
mine_[r + 1].clear();
concat(cr, crr);
size_t dstsize = (r == 0) ? config_.compressed_bucket_size :
2 * r * r * config_.compressed_bucket_size;
compressor_->compress(crr, config_.bicriteria_base_size,
dstsize, mine_[r + 1]);
carry_up(r + 1);
}
なぜか段数の二乗に
比例
- 17.
ミドルウェアとして利用する場合の問題点
近傍探索機能
近傍探索速度の問題
-1回の探索は1スレッドで直列実行される
- CPUのコアあたりの性能は近年頭打ち傾向
- 100万件を超えるとオンライン用途には厳しくなってくる
- 結果をキャッシュする、事前計算する等の対策は考えられるが…
- 素直にオンラインで使えるようになるのが望ましい
- 探索をマルチスレッド化し、複数コアを活かせるようにならないか
データ投入速度の問題
- レコード毎にRPCしなければならない
- バルク投入できるようにならないか
- 投入時のグローバルなロックにより実質直列実行される
- 射影計算等はスレッドローカルな計算なのでロックをとらずに実行できるはず
- 複数プロセス立ち上げて裏でmixさせるという対策はあるが…
全般
機能毎にサーバプロセスを立ち上げて個別に管理しなければなら
ない 16
- 18.
- 19.
IDLによる外部インタフェース定義
MessagePack IDLを基にした独自IDLによって定義する
RPC用メソッドを定義
- ロックの方式等
- メソッドのシグネチャ
jenerator
IDLファイルからサーバプログラムのテンプレートを自動生成
OCamlで記述されている
- どう書くとどういうコードが生成されるのかを確認する為には中を読む
ことになる
jeneratorのインストール手順
- OPAMをインストールする
- OPAMで必要なパッケージをインストールする
- $ opam install ounit
- $ opam install extlib
- jeneratorをコンパイル・インストールする
- $ omake
- $ sudo PREFIX=/usr/local omake install 18
service foo {
#@cht #@analysis #@pass
int do_something(0: string id)
}
- 20.
- 21.
モジュール構成
_serv
RPCを受け付ける
とりあえずここにロジックを書いてしまってもよい
core/driver/<service_name>.{hpp,cpp}
_servから呼ばれ、ロジックを呼び出す
serverとcoreを切り離すリファクタリングの途中?
core/<service_name>/
ここにロジックを記述することが期待されている
_storage
モデル(内部状態)を保持する
既存の_storageにそのまま使えるものがなければ実装する
既存のモジュールではここに多くのロジックが書かれている
_config
設定ファイルの定義を行う
20
- 22.
- 23.
save/load機能の実装
save/load機能とは
モデル(サーバの内部状態)をファイルに保存・ファイルから読
み込む機能
save/load機能はmix機能に相乗りしている
mix関連クラスを実装・利用する必要がある
手順
- _storageのpack(), unpack()を実装する
- _mixableを実装する
- _mixable->set_model()により_storageを_mixableに登録する
- mixable_holder->register_mixable()により_mixableをmixable_holderに登録
する
制御の流れ
- RPCでsave()が呼ばれる
- _serv->get_mixable_holder()によりmixable_holderを取得
- mixable_holder->pack(), _mixable->pack(), _storage->pack()の順に呼ばれる
22
- 24.
wafによるビルド
wscriptを書く
ビルド方法を指定する為のPythonスクリプト
メソッドとして各種の指定を記述
- configure:コンパイラオプション等を指定
- build:ソースやターゲットを指定
ビルド方法
$ ./waf configure
$ ./waf build
buildディレクトリにバイナリが出来上がる
23
bld.program(
source = __sources,
target = 'juba' + name,
includes = '.',
lib = __libraries
)
- 25.
単体試験
googletestを利用する
試験コードを記述する
waf-unittest (unittest_gtest.py)でwafから実行する
features引数で試験実施を指示する
$ ./waf build --check
24
bld.program(
features = 'gtest',
source = 'foo_storage_test.cpp',
...
TEST(foo_storage, set_get_state) {
foo_storage storage;
std::string id = ID1;
foo_state state = MAKE_STATE(1, 1.0);
storage.set_state(id, state);
foo_state state_ = storage.get_state(id);
EXPECT_EQ(state, state_);
}
- 26.










![コアセットが線形に成長する問題
再帰的な圧縮を行う部分
圧縮後の件数として指定する値が大きいため、再帰的な圧縮が実
質的に機能しておらず、対数的な成長にならない
jubatus/core/clustering/compressive_storage.cpp
void compressive_storage::carry_up(size_t r)
15
if (!is_next_bucket_full(r)) {
/****/
} else {
wplist cr = mine_[r];
wplist crr = mine_[r + 1];
mine_[r].clear();
mine_[r + 1].clear();
concat(cr, crr);
size_t dstsize = (r == 0) ? config_.compressed_bucket_size :
2 * r * r * config_.compressed_bucket_size;
compressor_->compress(crr, config_.bicriteria_base_size,
dstsize, mine_[r + 1]);
carry_up(r + 1);
}
なぜか段数の二乗に
比例](https://image.slidesharecdn.com/jubatuscasualtalks-140706193215-phpapp01/85/Jubatus-Jubatus-16-320.jpg)









