More Related Content

PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoNLP#9 
PDF

PDF
乱択データ構造の最新事情 -MinHash と HyperLogLog の最近の進歩- 
PDF

PDF

PDF
Python 機械学習プログラミング データ分析演習編 
PDF
Jubatusにおける大規模分散オンライン機械学習 
PDF
TensorFlowによるニューラルネットワーク入門 What's hot

PDF

PDF
Development and Experiment of Deep Learning with Caffe and maf 
PDF
最近のDeep Learning (NLP) 界隈におけるAttention事情 
PDF
LCCC2010:Learning on Cores, Clusters and Cloudsの解説 
PDF

PDF
Pythonによる機械学習入門〜基礎からDeep Learningまで〜 
PDF
機械学習チュートリアル@Jubatus Casual Talks 
PDF
Jubatus: 分散協調をキーとした大規模リアルタイム機械学習プラットフォーム 
PDF

PPTX
Pythonとdeep learningで手書き文字認識 
PDF
分類問題 - 機械学習ライブラリ scikit-learn の活用 
PDF

PPTX

PDF

PDF

PDF
「深層学習」勉強会LT資料 "Chainer使ってみた" 
PDF

PDF

PDF

PDF
Randomforestで高次元の変数重要度を見る #japanr LT Similar to Jubatusのリアルタイム分散レコメンデーション@TokyoWebmining#17

PDF
MapReduceによる大規模データを利用した機械学習 
PDF
Jubatusの紹介@第6回さくさくテキストマイニング 
PDF

PDF

PDF

PDF
Session4:「先進ビッグデータ応用を支える機械学習に求められる新技術」/比戸将平 
PDF

PDF

PPTX
Approximate Scalable Bounded Space Sketch for Large Data NLP 
PDF

PDF
PFI Christmas seminar 2009 
PPTX
0610 TECH & BRIDGE MEETING 
PDF

PDF
20160220 MSのビッグデータ分析基盤 - データマイニング+WEB@東京 
PDF
レコメンドアルゴリズムの基本と周辺知識と実装方法 
PPTX
Nttr study 20130206_share 
PDF

PDF

PPTX
PythonとRによるデータ分析環境の構築と機械学習によるデータ認識 第3版 
PPTX
More from Yuya Unno

PDF

PDF

PDF
ベンチャー企業で言葉を扱うロボットの研究開発をする 
PDF

PDF

PDF

PDF

PDF
最先端NLP勉強会�“Learning Language Games through Interaction”�Sida I. Wang, Percy L... 
PDF

PDF
Chainerのテスト環境とDockerでのCUDAの利用 
PDF

PDF

PDF
NIP2015読み会「End-To-End Memory Networks」 
PDF

PDF

PDF

PDF

PDF

PDF

PDF
Jubatusのリアルタイム分散レコメンデーション@TokyoWebmining#17
- 1.
Jubatusのリアルタイム分散
レコメンデーション
2012/05/20@TokyoWebmining
株式会社Preferred Infrastructure
海野 裕也 (@unnonouno)
- 2.
⾃自⼰己紹介
l 海野 裕也 (@unnonouno)
l unno/no/uno
l ㈱Preferred Infrastructure 研究開発部
l 検索索・レコメンドエンジンSedueの開発など
l 専⾨門
l ⾃自然⾔言語処理理
l テキストマイニング
l Jubatusチームリーダー
- 3.
今⽇日のお話
l Jubatusの紹介
l 分散レコメンデーションについて
#TokyoNLPではなした内容とだいたい同じですm(_ _)m
- 4.
- 5.
Big Data !
l データはこれからも増加し続ける
l 多いことより増えていくということが重要
l データ量量の変化に対応できるスケーラブルなシステムが求めら
れる
l データの種類は多様化
l 定形データのみならず、⾮非定形データも増加
l テキスト、⾏行行動履履歴、⾳音声、映像、信号
l ⽣生成される分野も多様化
l PC、モバイル、センサー、⾞車車、⼯工場、EC、病院
5
- 6.
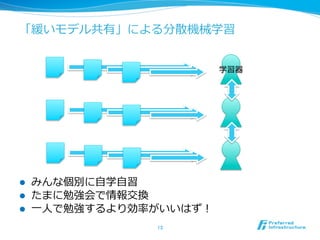
データを活⽤用する
STEP 1. ⼤大量量のデータを捨てずに蓄積できるようになってきた
STEP2. データを分析することで、現状の把握、理理解ができる
STEP 3. 状況を理理解し、現状の改善、予測ができる
l 世の中的には、蓄積から把握、理理解に向かった段階
この本が実際 この⼈人は30代
本の購買情報 に売れている 男性なので、
を全て記録で のは意外にも この本を買う
きるように 30代のおっさ のではない
なった! ん達だ! か?
蓄積 理理解 予測
より深い解析へ
6
- 7.
Jubatus
l NTT PF研とPreferred Infrastructureによる共同開発
10/27よりOSSで公開 http://jubat.us/
リアルタイム
ストリーム 分散並列列 深い解析
7
- 8.
Jubatusの技術的な特徴
分散かつオンラインの機械学習基盤
l オンライン学習をさらに分散化させる
l そのための通信プロトコル、計算モデル、死活監視、学
習アルゴリズムなどの⾜足回りを提供する
- 9.
分散かつオンラインの機械学習
l 処理理が速い!
l 処理理の完了了を待つ時間が少ない
l 5分前のTV番組の影響を反映した広告推薦ができる
l 5分前の交通量量から渋滞をさけた経路路を提案できる
l ⼤大規模!
l 処理理が間に合わなくなったらスケールアウト
l ⽇日本全国からデータが集まる状態でも動かしたい
l 機械学習の深い分析!
l 単純なカウント以上の精度度を
9
- 10.
他の技術との⽐比較
l ⼤大規模バッチ(Hadoop & Mahout)
l 並列列分散+機械学習
l リアルタイム性を確保するのは難しい
l オンライン学習ライブラリ
l リアルタイム+機械学習
l 並列列分散化させるのはかなり⼤大変
l ストリーム処理理基盤、CEP
l 並列列分散+リアルタイム
l 分散機械学習は難しい
- 11.
今までにない技術、これからの技術
l 欲張り
l 今までのトレンドを全部取り込む
l 制約が多く、実験も実装も難しい
l これからの技術
l 今すぐ実⽤用的になる部分、そうでない部分を含む
l 最初の1⼈人になるなら今!
l 新しい研究分野
l 研究テーマとしても⾯面⽩白い
l 乗っかるなら今!
- 12.
- 13.
- 14.
3種類の処理理に分解
l UPDATE
l データを受け取ってモデルを更更新(学習)する
l ANALYZE
l データを受け取って解析結果を返す
l MIX
l 内部モデルを混ぜ合わせる
l cf. MAP / REDUCE
l 分散機械学習を3操作だけでどこまで記述できる
か?
14
- 15.
3つの処理理の例例:統計処理理の場合
l 平均値を計算する⽅方法を考えよう
l 内部状態は今までの合計(sum)とデータの個数(count)
l UPDATE
l sum += x
l count += 1
l ANALYZE
l return (sum / count)
l MIX
l sum = sum1 + sum2
l count = count1 + count2
15
- 16.
世の中の機械学習ライブラリの敷居はまだ⾼高い
l libsvmフォーマット
l +1 1:1 3:1 8:1
l 何よこれ? ←普通の⼈人の反応
l ⽣生データを扱えない
l ハイパーパラメータ
l 「Cはいくつにしましたか?」
l Cってなんだよ・・・ ←普通の⼈人の反応
l 複雑な設定
l 研究者向き、エンジニアが広く使えない
16
- 17.
RDBやHadoopから学ぶべきこと
l わからない
l リレーショナル理理論論
l クエリオプティマイザ
l トランザクション処理理
l 分散計算モデル
l わかる
l SQL
l Map/Reduce
l 「あとは裏裏でよろしくやってくれるんでしょ?」
17
- 18.
Jubatus裏裏の⽬目標
全ての⼈人に機械学習を!
l わからない
l オンライン凸最適化
l 事後確率率率最⼤大化
l MCMC、変分ベイズ
l 特徴抽出、カーネルトリック
l わかる
l ⾃自動分類、推薦
l 「あとはよろしくやってくれるんでしょ?」
18
- 19.
⽣生データを突っ込めば動くようにしたい
l Jubatusの⼊入⼒力力はキー・バリュー
l 最初は任意のJSONだった
l twitter APIの⽣生出⼒力力を⼊入⼒力力できるようにしたかった
l あとは勝⼿手に適当に処理理してくれる
l ⾔言語判定して
l 各キーが何を表すのか⾃自動で推定して
l 勝⼿手に適切切な特徴抽出を選ばせる
l というようなことができるようになるかも
l 特徴抽出エンジンのプラグイン化
l 様々な特徴関数をダウンロードして⾃自由に組み合わせたい
19
- 20.
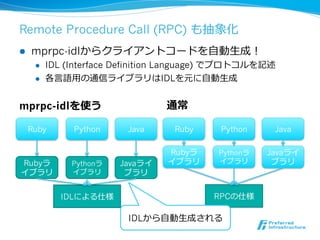
Remote Procedure Call(RPC) も抽象化
l mprpc-idlからクライアントコードを⾃自動⽣生成!
l IDL (Interface Definition Language) でプロトコルを記述
l 各⾔言語⽤用の通信ライブラリはIDLを元に⾃自動⽣生成
mprpc-idlを使う 通常
Ruby Python Java Ruby Python Java
Rubyラ Pythonラ Javaライ
Rubyラ Pythonラ Javaライ イブラリ イブラリ ブラリ
イブラリ イブラリ ブラリ
IDLによる仕様 RPCの仕様
IDLから⾃自動⽣生成される
- 21.
- 22.
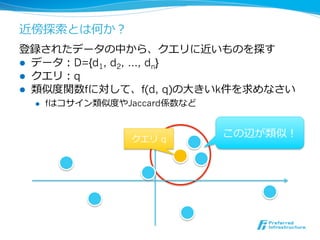
レコメンデーションとは何か?
l 記事や商品のおすすめ機能
l この記事に類似した記事はこの記事です
l この商品を買った⼈人はこの商品も買っています
l 技術的には「近傍探索索」を使っている
- 23.
- 24.
何も考えずに近傍探索索しよう
l 全データに対して類似度度を計算して上位を返せばOK
input: x
for d in all data:
score[d] = sim(x, d)
sort score
return top-K elements of score
- 25.
近傍探索索の技術的課題
l 実⾏行行時間
l 単純な実装だと、データ点のサイズに⽐比例例した時間がかかる
l 消費メモリ
l すべてのオリジナルデータを保持するとデータが膨⼤大になる
上記2点と精度度とのトレードオフ
- 26.
準備:よくある類似度度尺度度
l コサイン類似度度
l 2つのベクトルの余弦
l cos(θ(x, y)) = xTy / |x||y|
l Jaccard係数
l 2つの集合の積集合と和集合のサイズの⽐比
l Jacc(X, Y) = |X∩Y|/|X∪Y|
l ビットベクトル間の距離離と思うことができる
- 27.
近傍探索索アルゴリズム
l 転置インデックス
l Locality Sensitive Hashing (simhash)
l minhash
l アンカーグラフ
- 28.
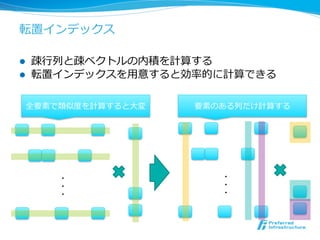
転置インデックス
l 疎⾏行行列列と疎ベクトルの内積を計算する
l 転置インデックスを⽤用意すると効率率率的に計算できる
全要素で類似度度を計算すると⼤大変 要素のある列列だけ計算する
・ ・
・ ・
・ ・
- 29.
Locality Sensitive Hashing(LSH)
l ランダムなベクトル r を作る
l このときベクトルx, yに対してxTrとyTrの正負が⼀一致する
確率率率はおよそ cos(θ(x, y))
l ランダムベクトルをk個に増やして正負の⼀一致率率率を数え
れば、だいたいコサイン距離離になる
l ベクトルxに対して、ランダムベクトル{r1, …, rk}との内
積の正負を計算 H(x) = {sign(xTr1), …, sign(xTrk)}
l signは正なら1、負なら0を返す関数
l H(x)だけ保存すればよいので1データ当たりkビット
- 30.
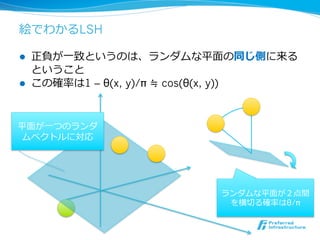
絵でわかるLSH
l 正負が⼀一致というのは、ランダムな平⾯面の同じ側に来る
ということ
l この確率率率は1 – θ(x, y)/π ≒ cos(θ(x, y))
平⾯面が⼀一つのランダ
ムベクトルに対応
ランダムな平⾯面が2点間
を横切切る確率率率はθ/π
- 31.
Jaccard係数
l 集合の類似度度を図る関数
l 値を0, 1しか取らないベクトルだと思えばOK
l Jacc(X, Y) = |X∩Y| / |X∪Y|
例例
l X = {1, 2, 4, 6, 7}
l Y = {1, 3, 5, 6}
l X∩Y = {1, 6}
l X∪Y = {1, 2, 3, 4, 5, 6, 7}
l Jacc(X, Y) = 2/7
- 32.
minhash
l X = { x1, x2, …, xn }
l Xは集合なので、感覚的には⾮非ゼロ要素のインデックスのこと
l H(X) = { h(x1), …, h(xn) }
l m(X) = argmin(H(X))
l m(X) = m(Y)となる確率率率はJacc(X, Y)に⼀一致
l ハッシュ関数を複数⽤用意したとき、m(X)=m(Y)となる回数を数
えるとJacc(X, Y)に収束する
l m(X)の最下位ビットだけ保持すると、衝突の危険が⾼高
まる代わりにハッシュ関数を増やせる [Li+10a, Li+10b]
- 33.
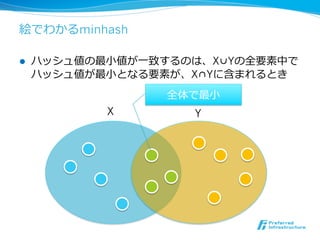
絵でわかるminhash
l ハッシュ値の最⼩小値が⼀一致するのは、X∪Yの全要素中で
ハッシュ値が最⼩小となる要素が、X∩Yに含まれるとき
全体で最⼩小
X Y
- 34.
重み付きJaccard係数
l 各集合の要素のidfのような重みをつける
l wJacc(X, Y) = Σ i∈X∩Y wi / Σ i∈X∪Y wi
l wiが常に1なら先と同じ
例例
l X = {1, 2, 4, 6, 7}
l Y = {1, 3, 5, 6}
l w = (2, 3, 1, 4, 5, 2, 3)
l X∩Y = {1, 6}
l X∪Y = {1, 2, 3, 4, 5, 6, 7}
l wJacc(X, Y) = (2+2)/(2+3+1+4+5+2+3)=4/20
- 35.
重み付きJaccard版minhash [Chum+08]
l X = { x1, x2, …, xn }
l H(X) = {h(x1)/w1, …, h(xn)/wn}
l 論論⽂文中では-log(h(x))としている
l 差分はwiで割っているところ
l 感覚的にはwiが⼤大きければ、ハッシュ値が⼩小さくなりやすいの
で、選ばれる確率率率が⼤大きくなる
l m(X) = argmin(H(X))
l m(X) = m(Y)となる確率率率はwJacc(X, Y)に⼀一致
- 36.
アンカーグラフ [Liu+11]
l 予めアンカーを定めておく
l 各データは近いアンカーだけ覚える
l アンカーはハブ空港のようなもの
l まず類似アンカーを探して、その周辺だけ探せばOK
アンカー
- 37.
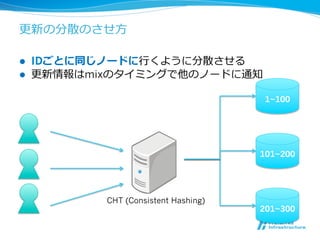
- 38.
更更新の分散のさせ⽅方
l IDごとに同じノードに⾏行行くように分散させる
l 更更新情報はmixのタイミングで他のノードに通知
1~100
101~200
CHT (Consistent Hashing)
201~300
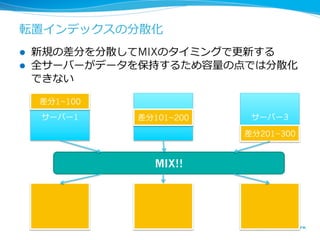
- 39.
転置インデックスの分散化
l 新規の差分を分散してMIXのタイミングで更更新する
l 全サーバーがデータを保持するため容量量の点では分散化
できない
差分1~100
サーバー1 サバー2
差分101~200 サーバー3
差分201~300
MIX!!
- 40.
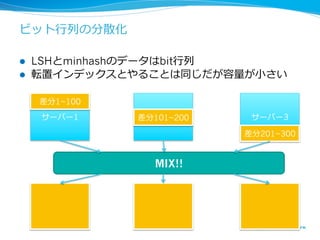
ビット⾏行行列列の分散化
l LSHとminhashのデータはbit⾏行行列列
l 転置インデックスとやることは同じだが容量量が⼩小さい
差分1~100
サーバー1 サバー2
差分101~200 サーバー3
差分201~300
MIX!!
- 41.
アンカーグラフの分散化?
l 類似アンカーの情報しか残ってないため、データの⼀一部
を更更新するのが困難
l オリジナルデータを持っておけばよい?
l 実装・デバッグはかなり激しい
l うまく⾏行行っているのかどうかわかりにくい
- 42.
現在の実装
l 転置インデックスとLSHが公開されている
l minhashは特許問題で調整中
l アンカーグラフはうまく分散させるに⾄至らず
- 43.
- 44.
まとめ
l Jubatusは総合格闘技
l MIX操作による緩い同期計算モデル
l ⾮非構造データを扱うための特徴抽出
l IDLからのクライアントコード⾃自動⽣生成
l レコメンドの4⼿手法
l 転置インデックス
l Locality Sensitive Hashing (simhash)
l minhash
l アンカーグラフ
l 現在は前者2つを公開
- 45.
参考⽂文献
l [Chum+08] OndrejChum, James Philbin, Andrew Zisserman.
Near Duplicate Image Detection: min-Hash and tf-idf
Weighting.
BMVC 2008.
l [Li+10a] Ping Li, Arnd Christian Konig.
b-Bit Minwise Hashing.
WWW 2008.
l [Li+10b] Ping Li, Arnd Christian Konig, Wenhao Gui.
b-Bit Minwise Hashing for Estimating Three-Way Similarities.
NIPS 2008.
l [Liu+11] Wei Liu, Jun Wang, Sanjiv Kumar, Shin-Fu Chang.
Hashing with Graphs.
ICML 2011.





















![何も考えずに近傍探索索しよう
l 全データに対して類似度度を計算して上位を返せばOK
input: x
for d in all data:
score[d] = sim(x, d)
sort score
return top-K elements of score](https://image.slidesharecdn.com/20120520jubatustokyowebmining-120519220425-phpapp02/85/Jubatus-TokyoWebmining-17-24-320.jpg)





![minhash
l X = { x1, x2, …, xn }
l Xは集合なので、感覚的には⾮非ゼロ要素のインデックスのこと
l H(X) = { h(x1), …, h(xn) }
l m(X) = argmin(H(X))
l m(X) = m(Y)となる確率率率はJacc(X, Y)に⼀一致
l ハッシュ関数を複数⽤用意したとき、m(X)=m(Y)となる回数を数
えるとJacc(X, Y)に収束する
l m(X)の最下位ビットだけ保持すると、衝突の危険が⾼高
まる代わりにハッシュ関数を増やせる [Li+10a, Li+10b]](https://image.slidesharecdn.com/20120520jubatustokyowebmining-120519220425-phpapp02/85/Jubatus-TokyoWebmining-17-32-320.jpg)

![重み付きJaccard版minhash [Chum+08]
l X = { x1, x2, …, xn }
l H(X) = {h(x1)/w1, …, h(xn)/wn}
l 論論⽂文中では-log(h(x))としている
l 差分はwiで割っているところ
l 感覚的にはwiが⼤大きければ、ハッシュ値が⼩小さくなりやすいの
で、選ばれる確率率率が⼤大きくなる
l m(X) = argmin(H(X))
l m(X) = m(Y)となる確率率率はwJacc(X, Y)に⼀一致](https://image.slidesharecdn.com/20120520jubatustokyowebmining-120519220425-phpapp02/85/Jubatus-TokyoWebmining-17-35-320.jpg)
![アンカーグラフ [Liu+11]
l 予めアンカーを定めておく
l 各データは近いアンカーだけ覚える
l アンカーはハブ空港のようなもの
l まず類似アンカーを探して、その周辺だけ探せばOK
アンカー](https://image.slidesharecdn.com/20120520jubatustokyowebmining-120519220425-phpapp02/85/Jubatus-TokyoWebmining-17-36-320.jpg)




![参考⽂文献
l [Chum+08] Ondrej Chum, James Philbin, Andrew Zisserman.
Near Duplicate Image Detection: min-Hash and tf-idf
Weighting.
BMVC 2008.
l [Li+10a] Ping Li, Arnd Christian Konig.
b-Bit Minwise Hashing.
WWW 2008.
l [Li+10b] Ping Li, Arnd Christian Konig, Wenhao Gui.
b-Bit Minwise Hashing for Estimating Three-Way Similarities.
NIPS 2008.
l [Liu+11] Wei Liu, Jun Wang, Sanjiv Kumar, Shin-Fu Chang.
Hashing with Graphs.
ICML 2011.](https://image.slidesharecdn.com/20120520jubatustokyowebmining-120519220425-phpapp02/85/Jubatus-TokyoWebmining-17-45-320.jpg)