Downloaded 103 times
























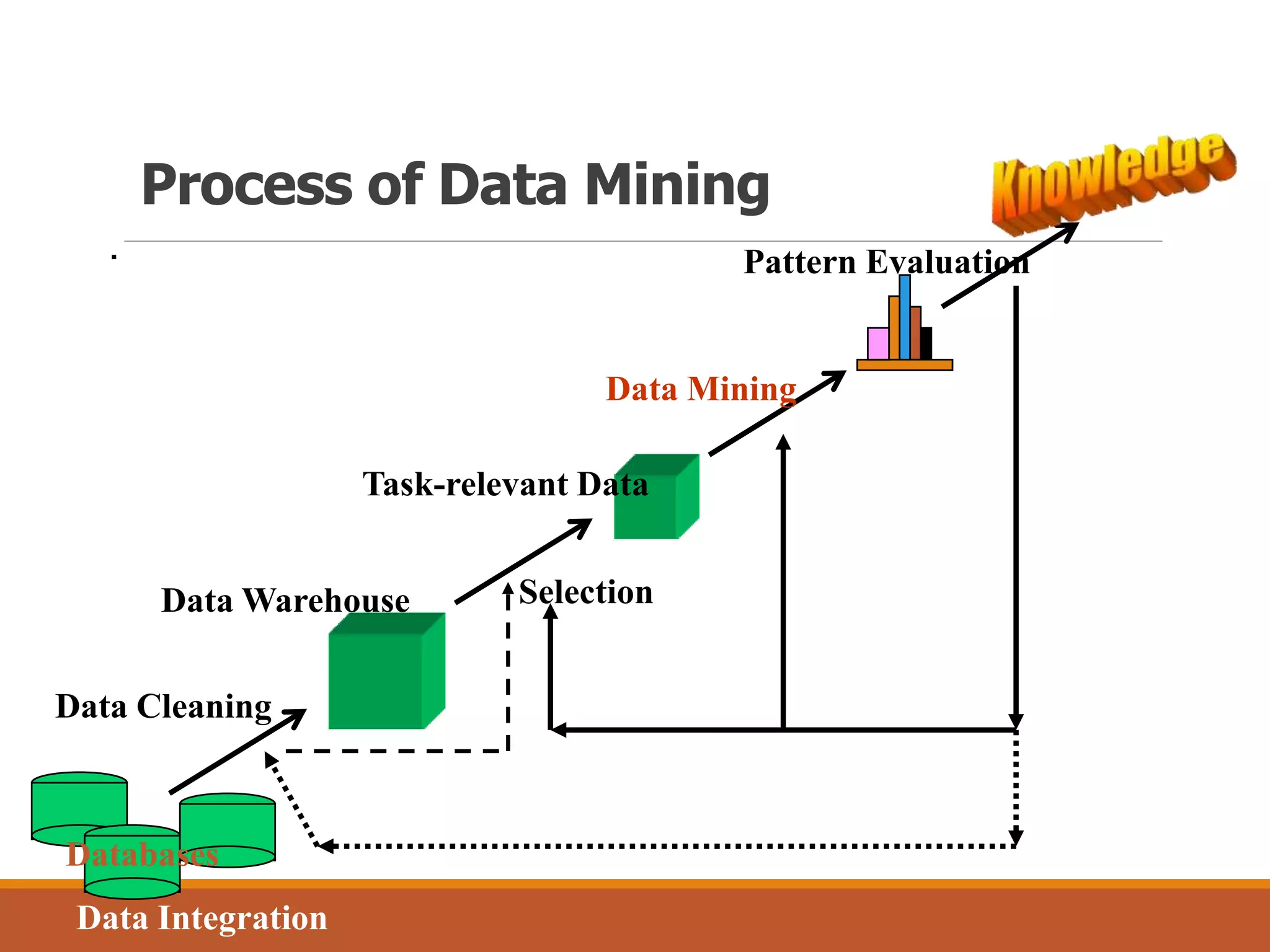












![ Most famous data mining tasks:
Classification [Predictive]
Prediction [Predictive]
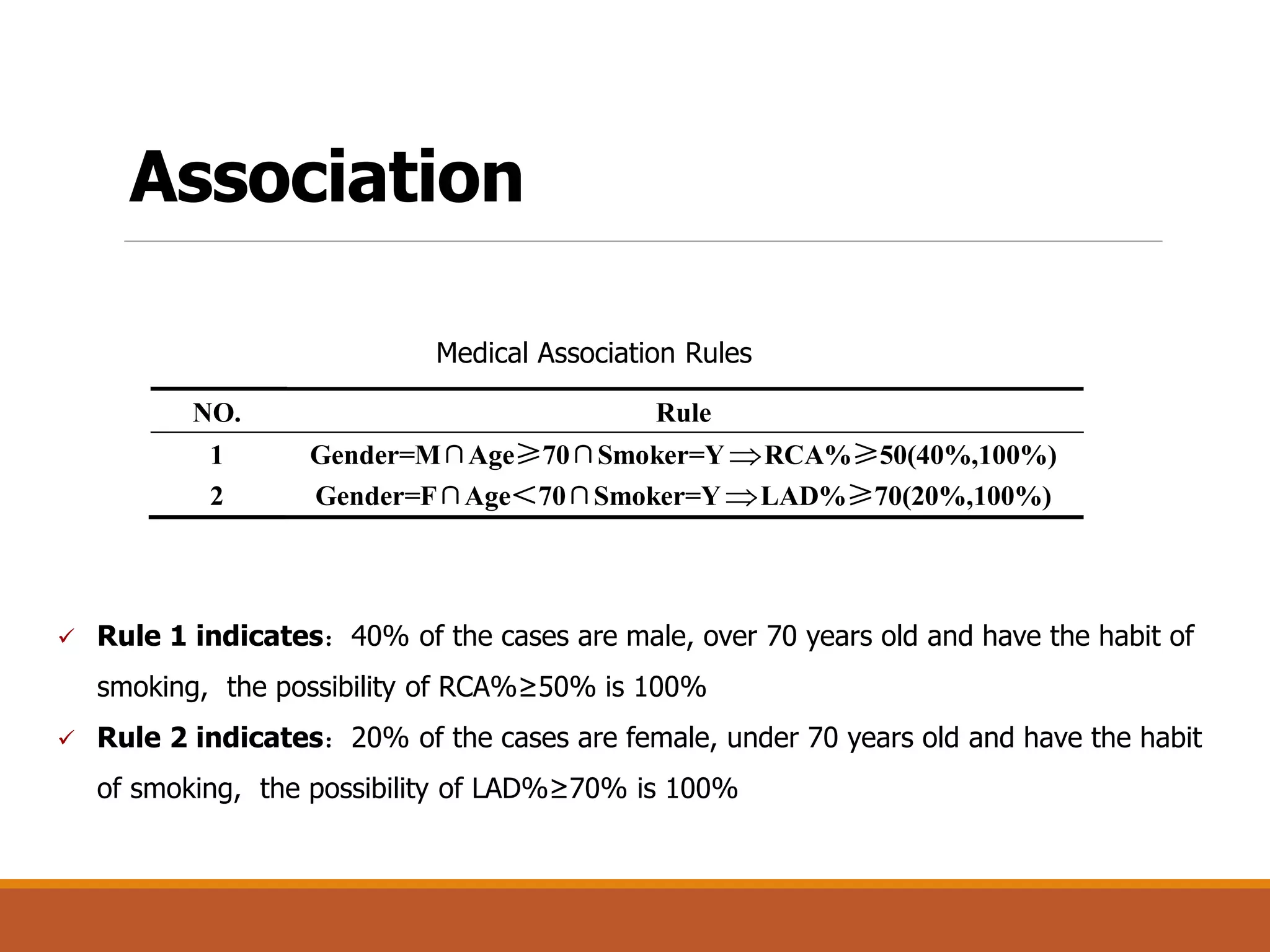
Association Rules [Descriptive]
Clustering [Descriptive]
Outlier Analysis [Descriptive]
Data Mining Tasks](https://image.slidesharecdn.com/1introduction-to-data-miningchapter1-181005051512/75/Introduction-to-data-mining-chapter-1-42-2048.jpg)

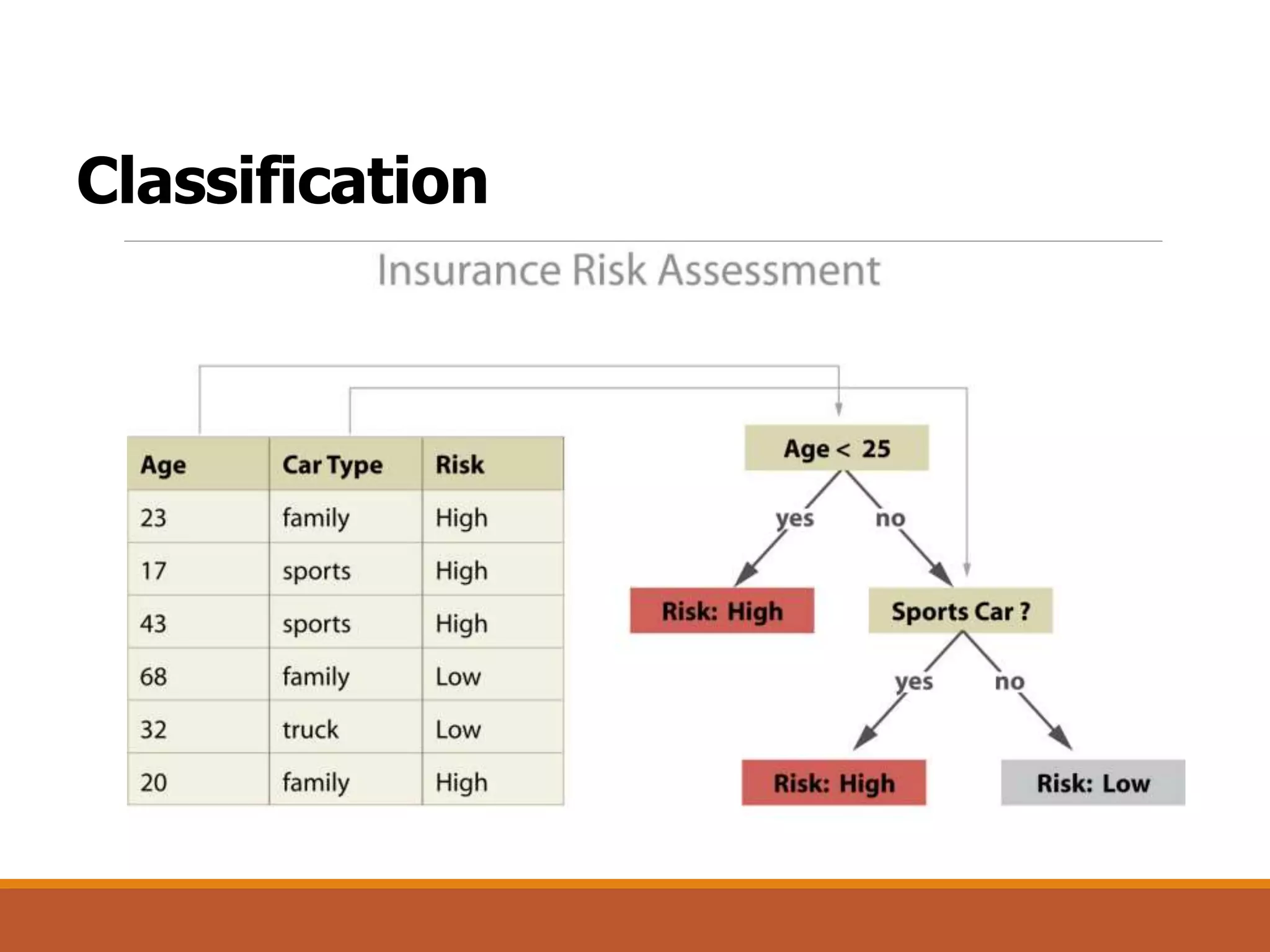
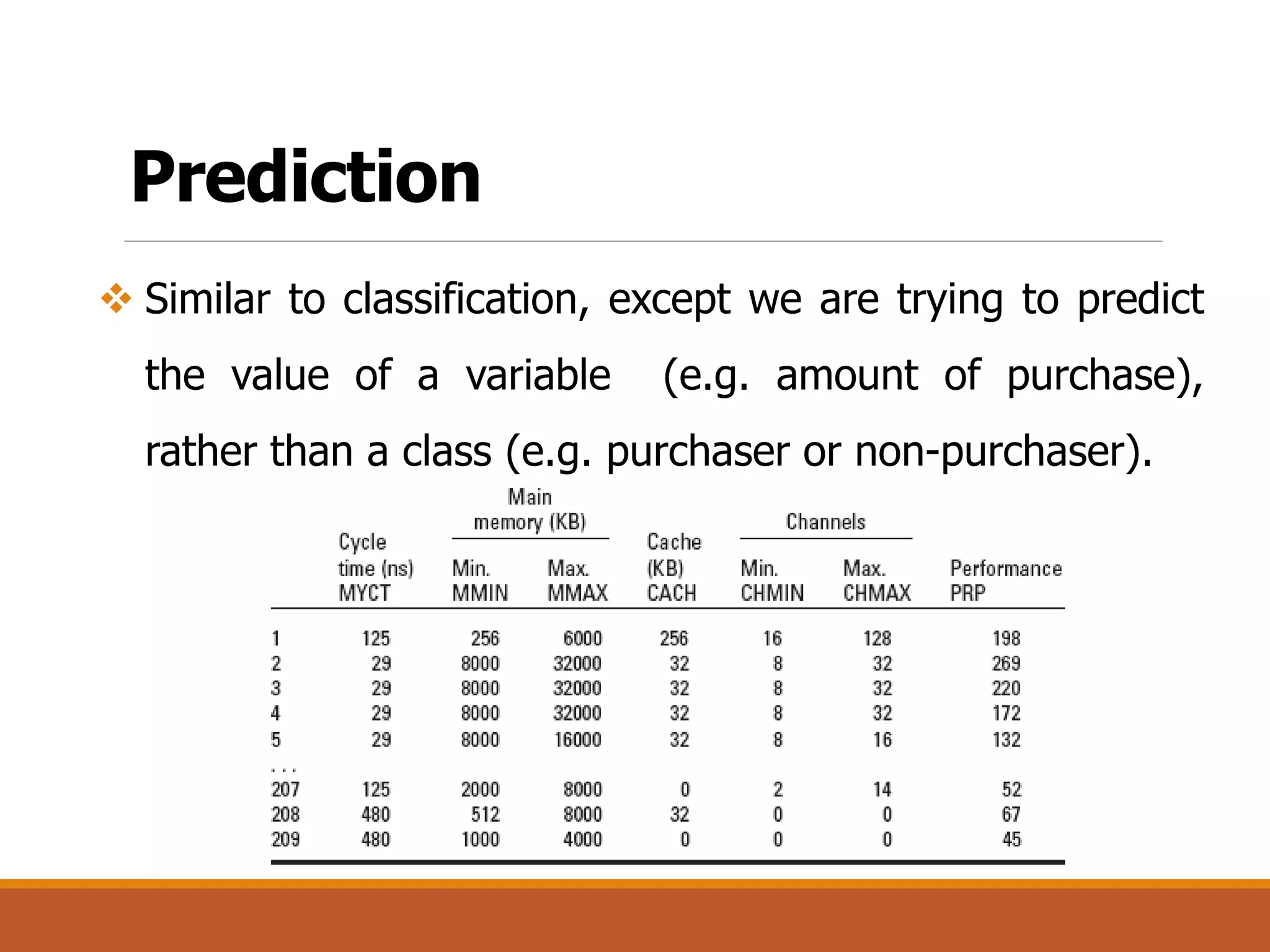

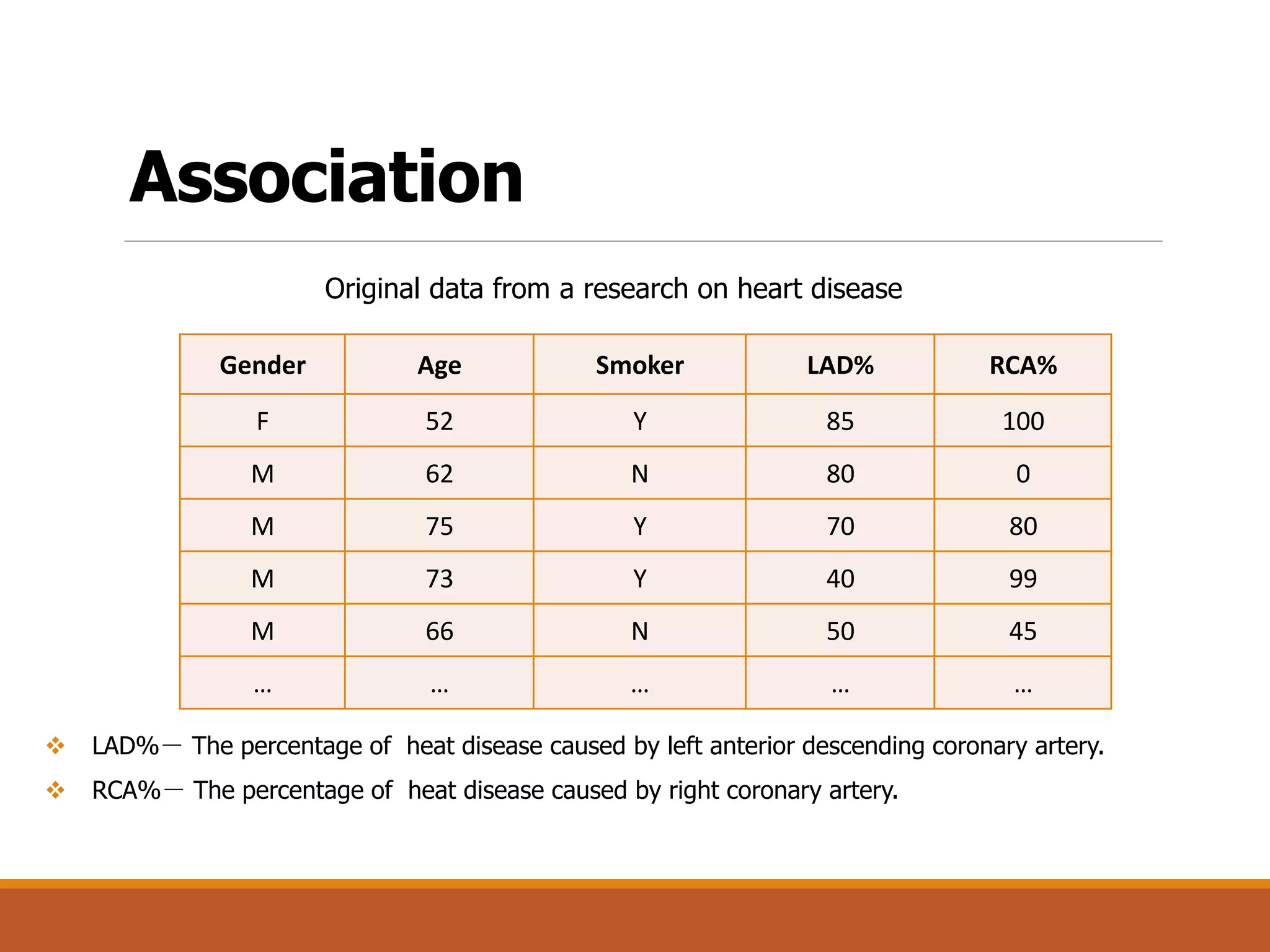













The document is an introduction to data mining, covering its definition, interdisciplinary nature, processes, tasks, challenges, and applications. It emphasizes the non-trivial process of discovering patterns in large datasets, and describes phases such as data cleaning, integration, and evaluation. Additionally, it outlines various data mining tasks including classification, prediction, association, clustering, and outlier analysis, along with key challenges faced in the field.























































































