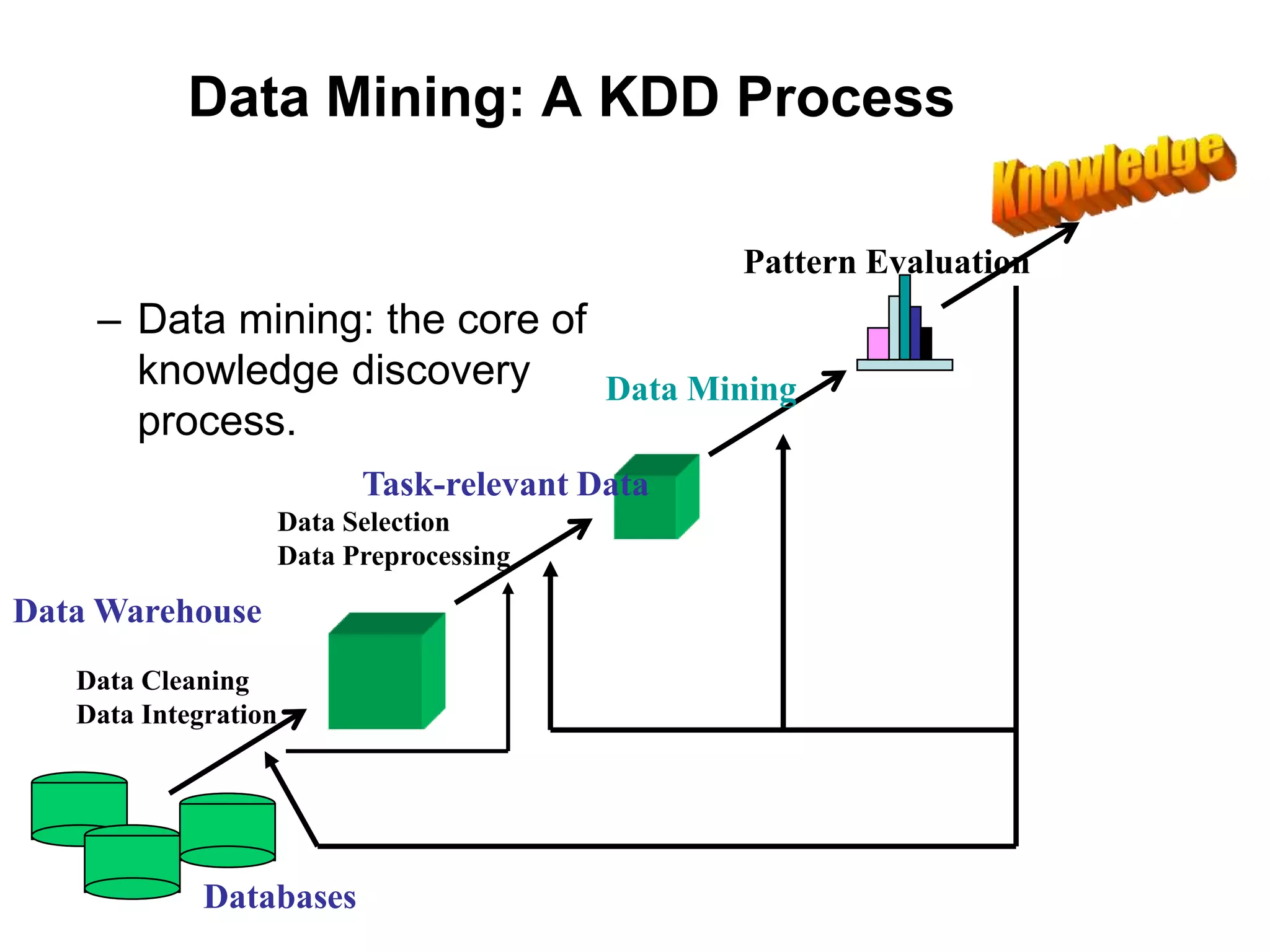
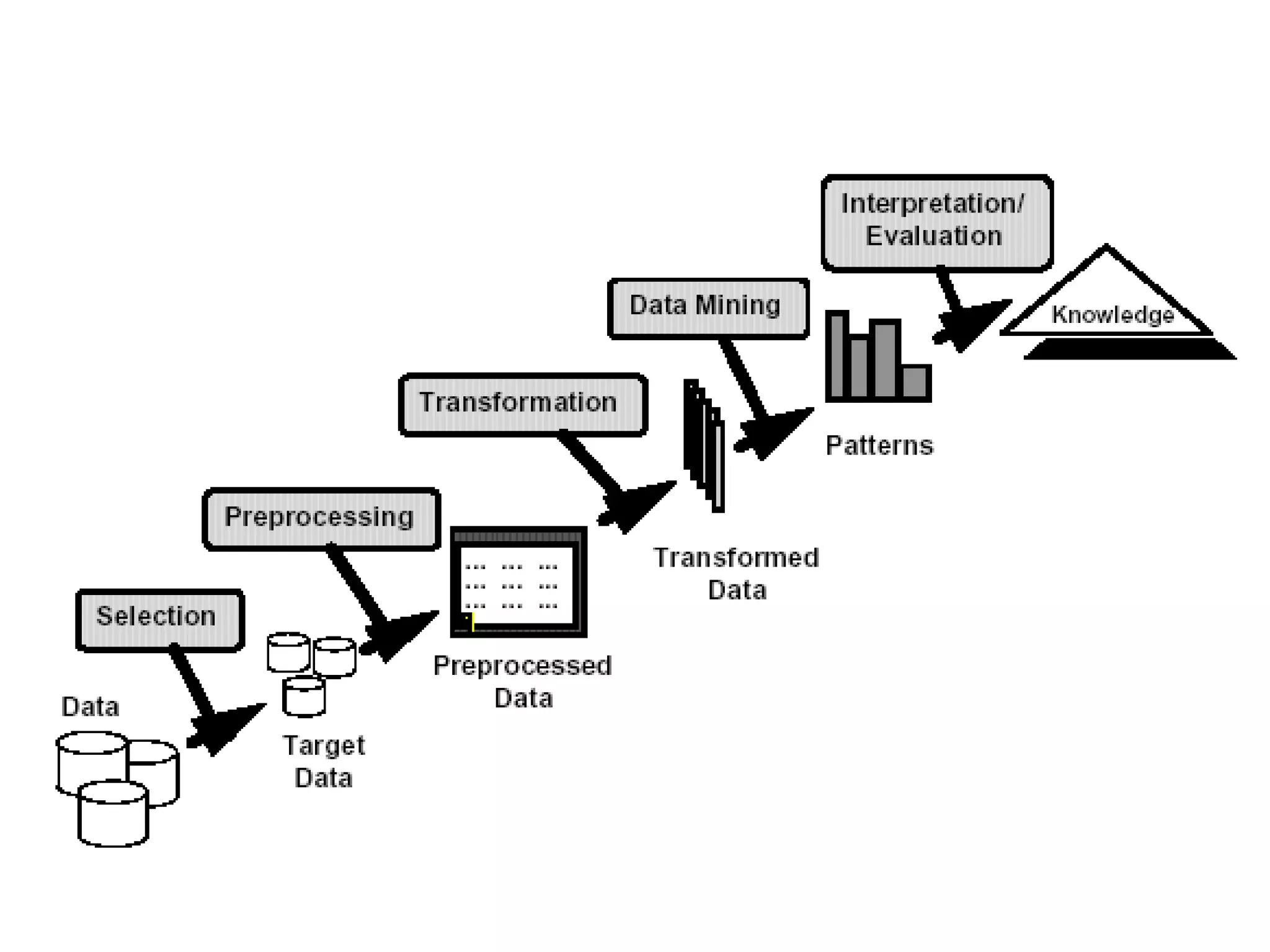
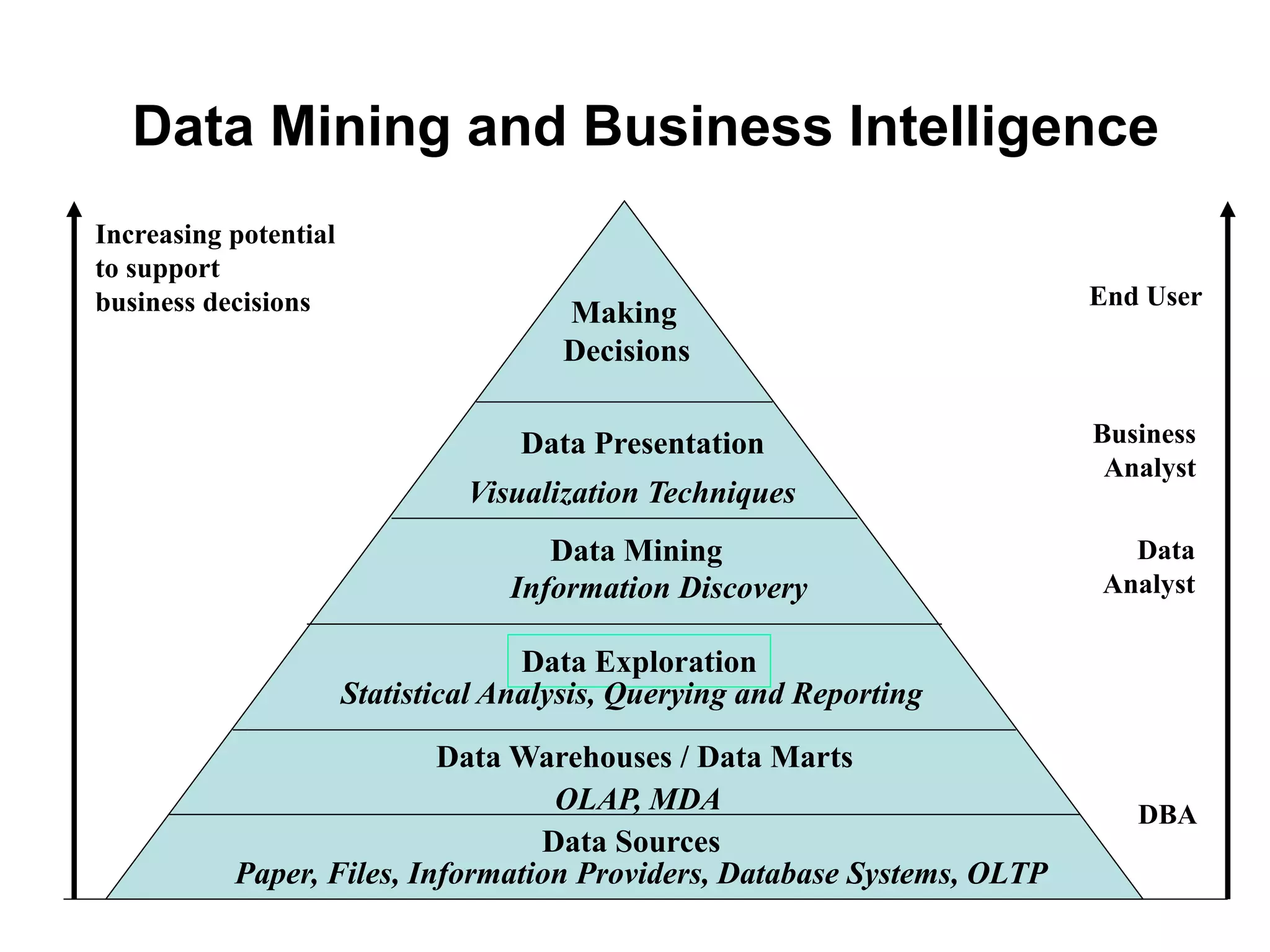
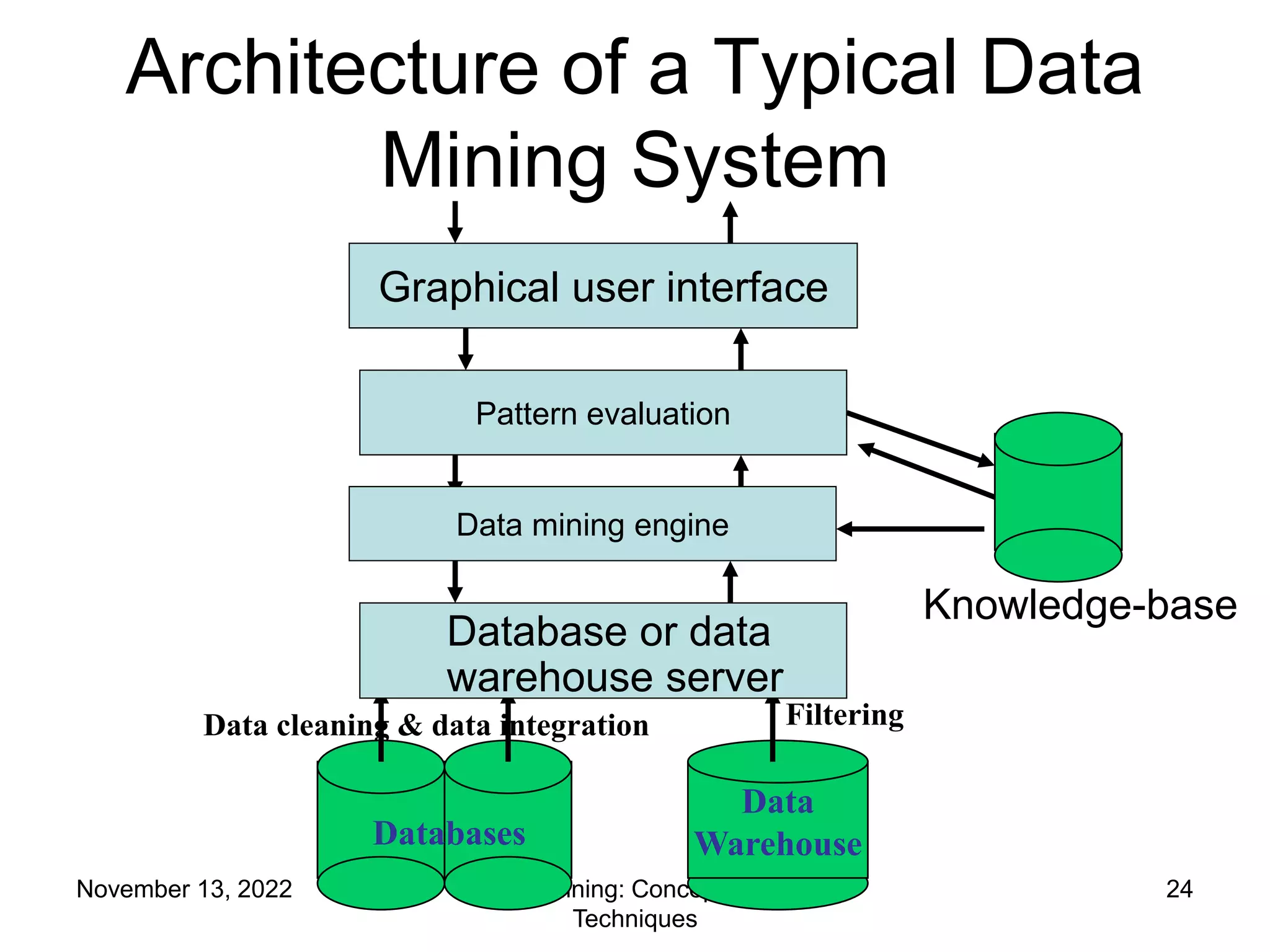
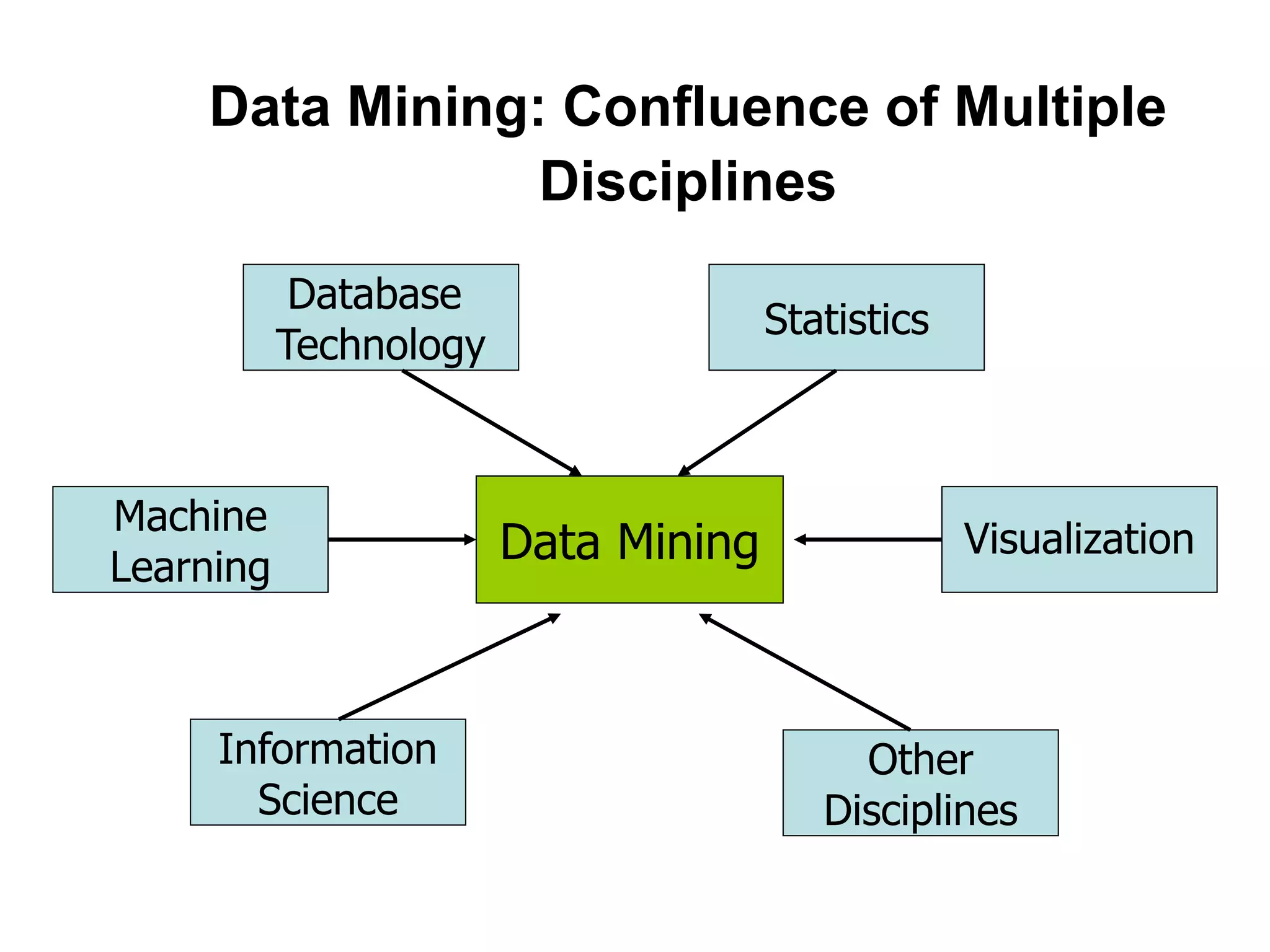
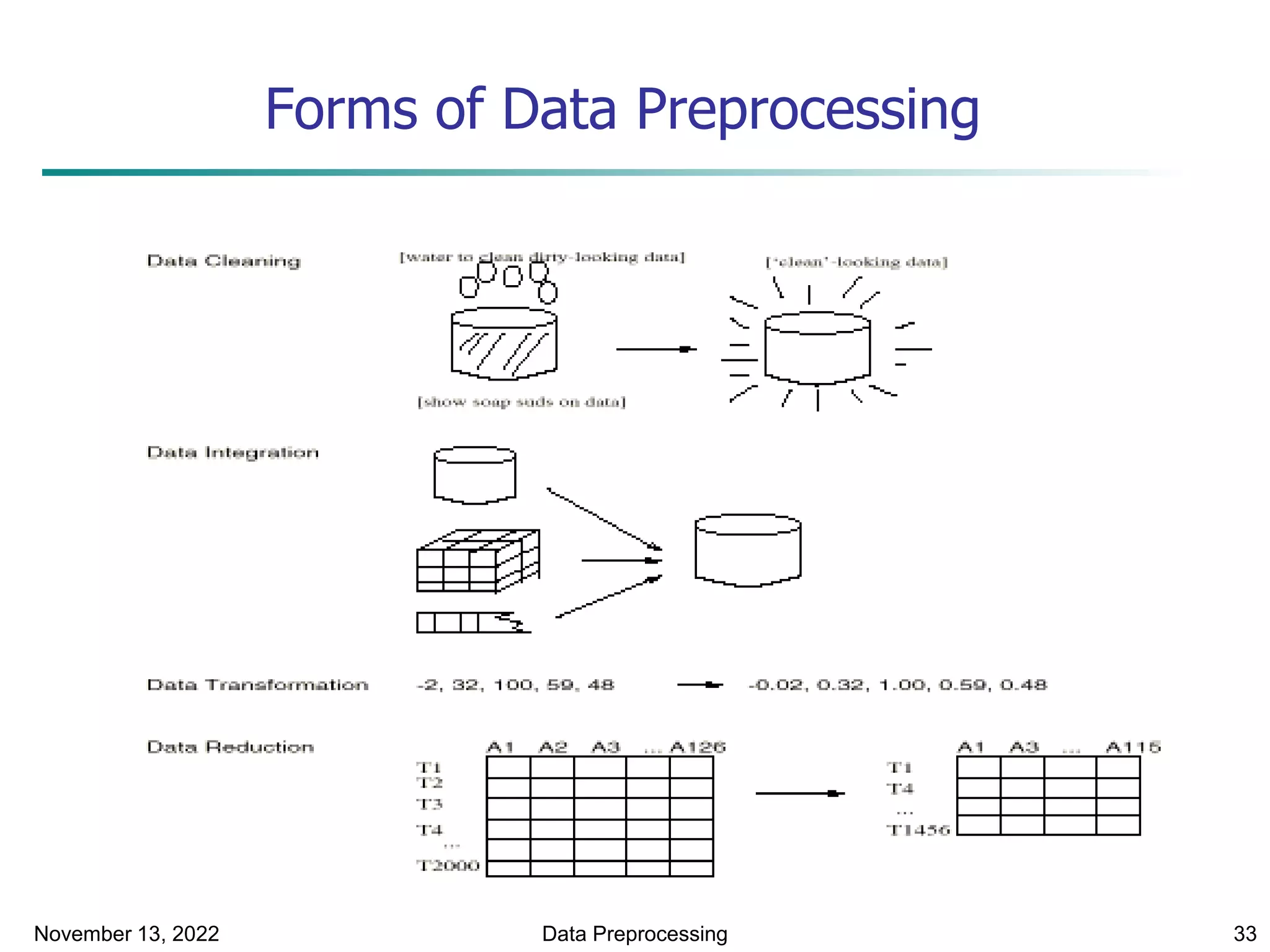
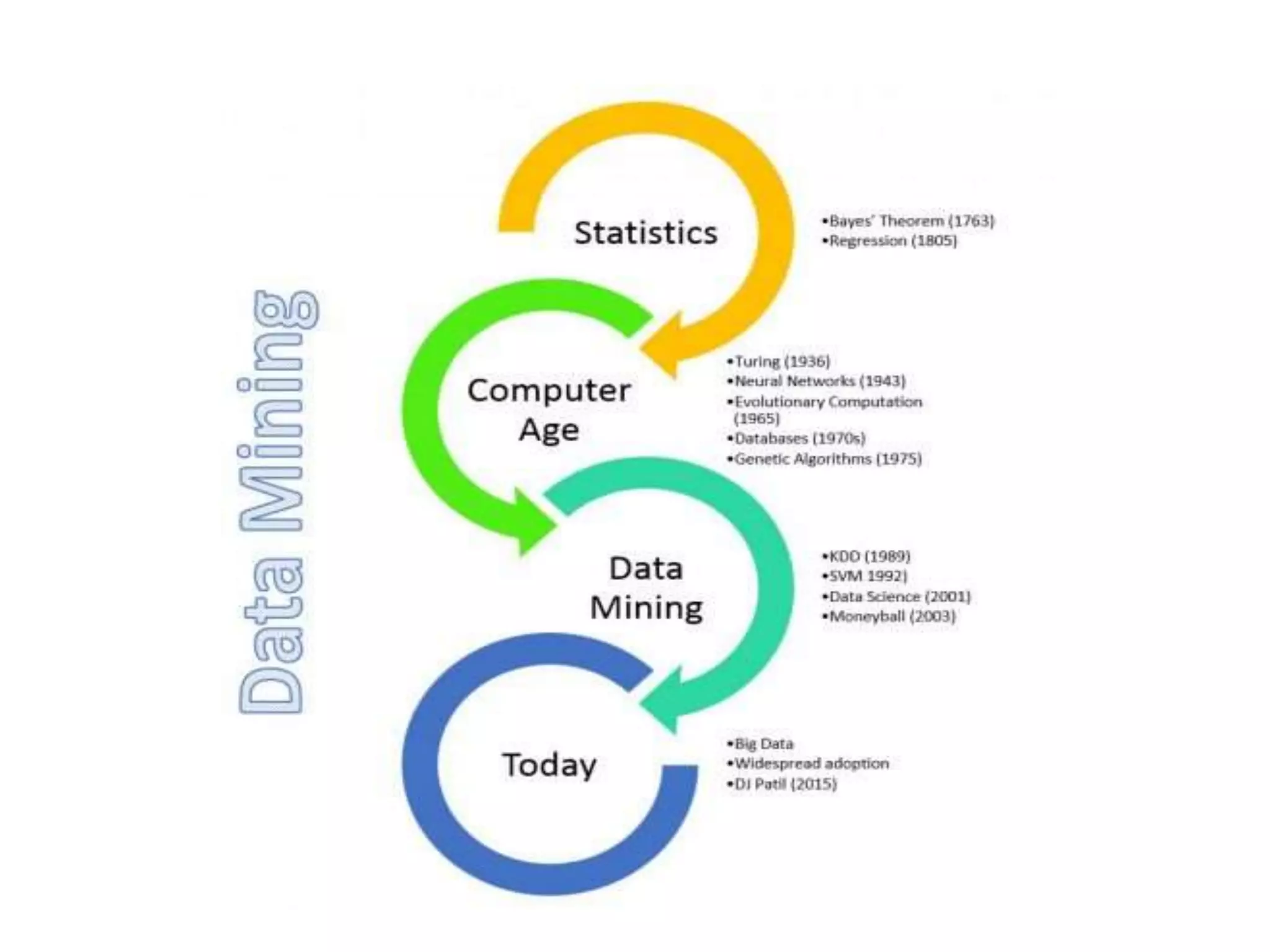
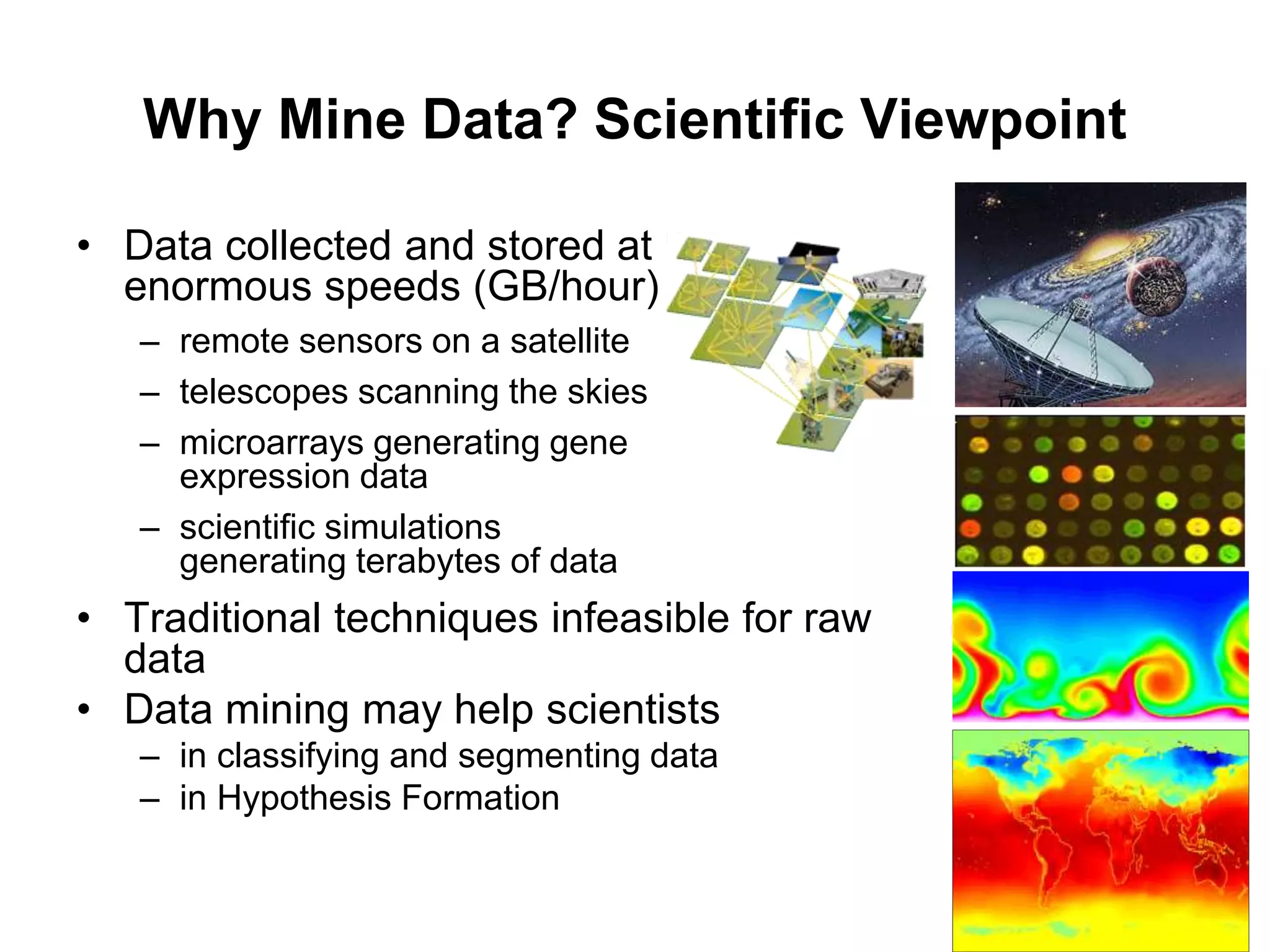
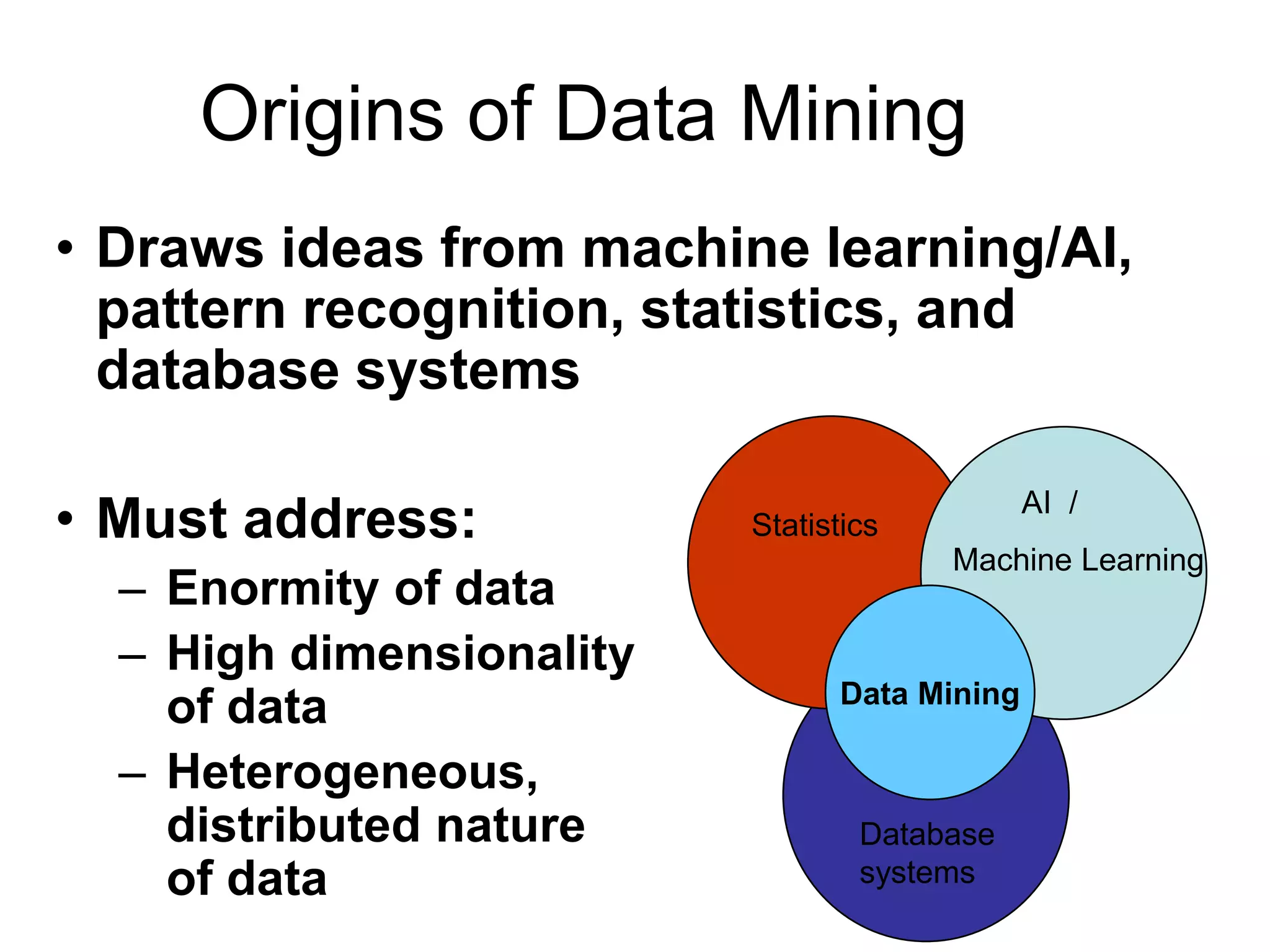
This document provides an introduction to data mining. It discusses the history of data mining, which began with early methods like Bayes' Theorem and regression analysis in the 1700s and 1800s. The document then covers why organizations mine data from both commercial and scientific viewpoints. It defines data mining as the extraction of useful patterns from large datasets and explains how it differs from traditional data analysis. Several common data mining tasks like classification, clustering, and association rule mining are also introduced. Finally, the document outlines the typical steps involved in a knowledge discovery process.







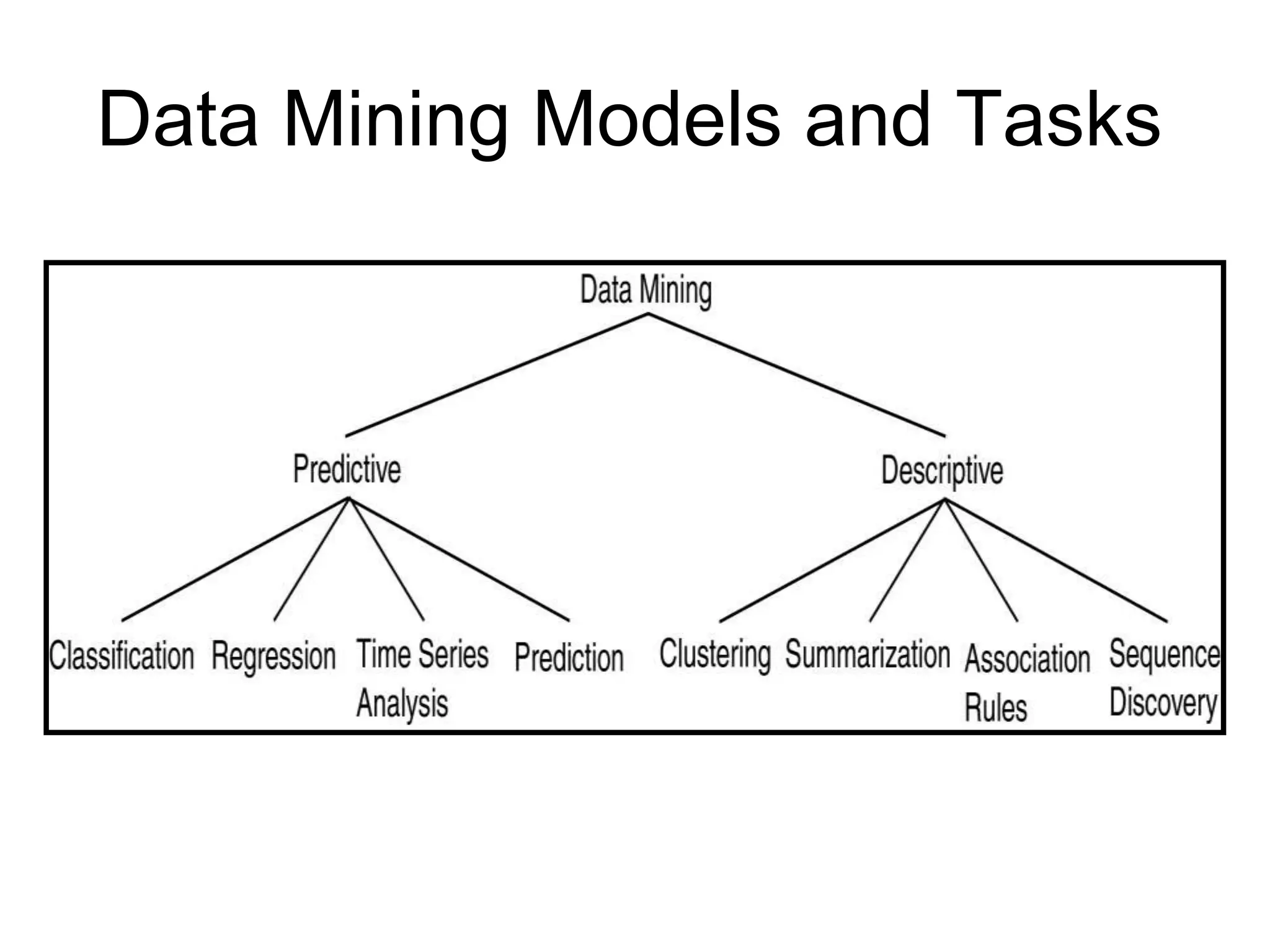


![Data Mining Tasks
• Prediction Tasks
– Use some variables to predict unknown or future values of other
variables
• Description Tasks
– Find human-interpretable patterns that describe the data.
Common data mining tasks
– Classification [Predictive]
– Clustering [Descriptive]
– Association Rule Discovery [Descriptive]
– Sequential Pattern Discovery [Descriptive]
– Regression [Predictive]
– Deviation Detection [Predictive]](https://image.slidesharecdn.com/datamining-unit-ippt1-221113051328-0c425c31/75/Data-Mining-Unit-I-PPT-1-ppt-14-2048.jpg)