Downloaded 20 times













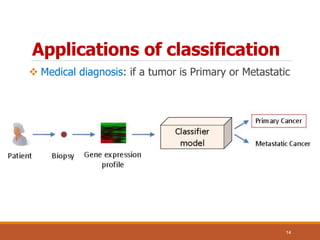































































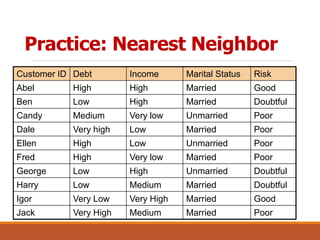



The document discusses the concept of classification in machine learning, defining it as a technique for predicting group membership for data instances and detailing its applications across various fields such as medical diagnosis and fraud detection. It explains the process of data classification, including building classifiers and evaluating their accuracy through training and test sets, while contrasting classification with prediction. Techniques such as decision trees and k-nearest neighbors are presented as common methods for implementing classification models.























































































