Downloaded 841 times















![Data Mining Functionalities
Multidimensional concept description: Characterization and
discrimination
Generalize, summarize, and contrast data characteristics, e.g.,
dry vs. wet regions
Frequent patterns, association, correlation vs. causality
Diaper Beer [0.5%, 75%] (Correlation or causality?)
Classification and prediction
Construct models (functions) that describe and distinguish
classes or concepts for future prediction
E.g., classify countries based on (climate), or classify cars
based on (gas mileage)
Predict some unknown or missing numerical values
September 14, 2014 Data Mining: Concepts and Techniques 19](https://image.slidesharecdn.com/chap1-140913205945-phpapp01/85/introduction-to-data-mining-tutorial-19-320.jpg)
































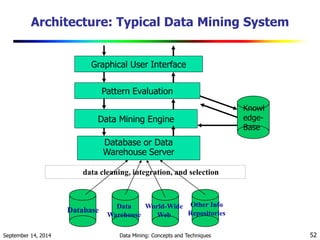

The document provides an overview of data mining and its significance, outlining its evolution, functionalities, and methodologies across various disciplines. It details the course structures related to data mining, highlighting major algorithms, popular issues in the field, and the transformative impact of data mining on business intelligence and decision-making. The introduction emphasizes the necessity of data mining in an era of exponential data growth and the challenges it presents in knowledge extraction from diverse data types.


































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)








