The document discusses a TensorFlow session that merges summary data and runs an agenda. Key topics from the document include TensorFlow sessions, summary data, and running agendas.
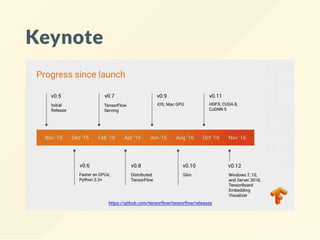
Keynote
DistBelief -> TensorFlow
제품뿐 아니라 연구 레벨에서까지 광범위하게 사용 가능
RNN 등의 복잡한 모델까지 커버 가능하다
CPU, GPU, TPU, Android, iOS, Raspberry Pi 등 다양
한 플랫폼 지원
구글 클라우드에서도 사용 가능
Python, C++, Java, Go, Haskell, R ...
텐서보드 짱짱맨
Serving Models
Online, lowlatency
Mutiple models in a single process
Mutiple versions of a model loaded over time
Compute cost varies in real-time to meet product
demand
auto-scale with CloudML, Docker & K8s
Aim for the ef ciency of mini-batching at training
time ...
29.
ML Toolkits
model =KMeansClustering(num_clusters=1000)
model.fit(
input_fn=numpy_input_fn(points, num_epochs=None),
steps=1000)
clusters = model.clusters()
assignments = model.predict_cluster_idx(
input_fn=numpy_input_fn(test_points))
ETC
XLA: TensorFlow, Compiled!
SkinCancer Image Classi cation
Sequence Models and the RNN API
TensorFlow in Medicine
Wide & Deep Learning
Magenta: Music and Art Generation
Fast, Flexible, TensorBoard, Community





















![Distributed TensorFlow
cluster = tf.train.ClusterSpec({
"worker": ["192.168.0.1:2222", ...],
"ps": ["192.168.1.1:2222", ...]})
server = tf.train.Server(
cluster,
job_name="worker",
task_index=0)
with tf.Session(server.target) as sess:
...](https://image.slidesharecdn.com/tensorflowdevsummit2017-170221130951/85/TensorFlow-Dev-Summit-2017-23-320.jpg)







![ML Toolkits
tensor ow/contrib/learn/python/learn
classifier = tf.contrib.learn.DNNClassifier(
feature_columns=feature_columns,
hidden_units=[10, 20, 10],
n_classes=3,
model_dir="/tmp/iris_model")
classifier.fit(x=training_set.data,
y=training_set.target,
steps=2000)
accuracy_score = classifier.evaluate(
x=test_set.data,
y=test_set.target)["accuracy"]](https://image.slidesharecdn.com/tensorflowdevsummit2017-170221130951/85/TensorFlow-Dev-Summit-2017-31-320.jpg)



























































































