Downloaded 70 times



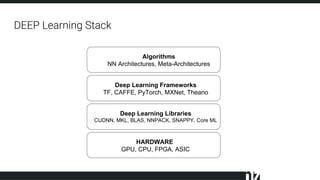
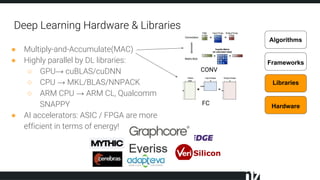



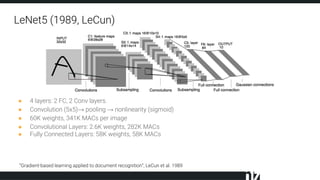




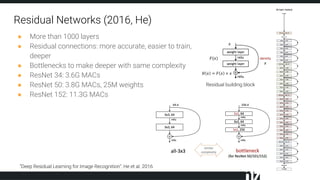
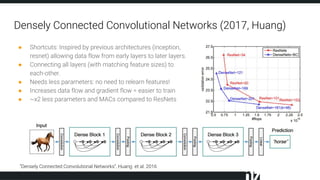

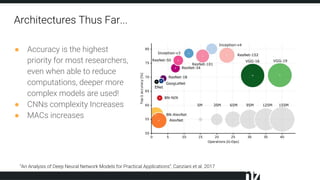

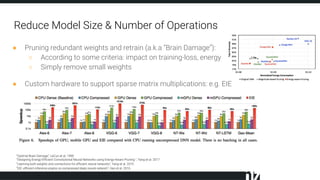

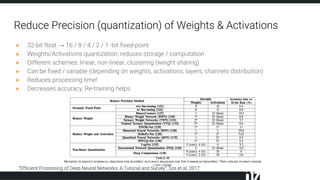





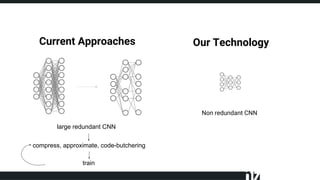

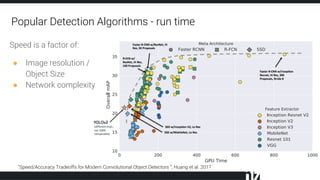
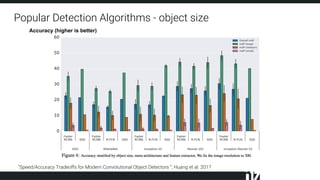
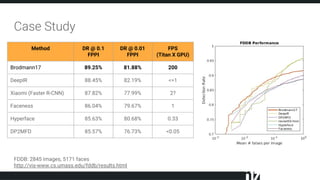


The document discusses efficient techniques for deep learning on edge devices. It begins by noting that deep neural networks have high computational complexity which makes inference inefficient for edge devices without powerful GPUs. It then outlines the deep learning stack from hardware to libraries to frameworks to algorithms. The document focuses on how algorithms define model complexity and discusses the evolution of CNN architectures from LeNet5 to ResNet which generally increased in complexity. It covers techniques for reducing model size and operations like pruning, quantization, and knowledge distillation. The challenges of real-life applications on edge devices are discussed.














![[PR12] PR-063: Peephole predicting network performance before training](https://cdn.slidesharecdn.com/ss_thumbnails/peepholepredictingnetworkperformance-180130162632-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PR12] PR-050: Convolutional LSTM Network: A Machine Learning Approach for Pr...](https://cdn.slidesharecdn.com/ss_thumbnails/pr12-convlstm-171126135417-thumbnail.jpg?width=640&height=640&fit=bounds)




























































