例例:マージソート (2/2)
逐次的なマージソート
X, Y, Z
ix = 0, iy = 0, iz = 0
while (iz < n+m) {
if (comp(X[ix], Y[iy]) Z[iz++] = X[ix++]
else Z[iz++] = Y[iy++]
}
// 境界条件はcompがうまいことやってくれてることにします
これをどのように分割するのか?
11
22
input=300000000 wordCount=45788064
distinctWord=1129243 words=45788064
02528465 the
1 1564080 of
2 1219248 and
3 986168 in
4 862412 a
5 862356 to
6 507386 is
7 484451 The
8 445334 was
9 336005 for
10 334510 s
11 316207 as
12 295183 by
13 282728 with
14 281566 on
15 241960 that
16 235218 doc
17 221649 from
18 193797 at
19 189947 his
20 157175 an



![しかし我々はCUDAを書くのか
l 否!
– 素⼈人はCUDAを書いてはならない [Okuta 2015]
l cupy (chainer)
– 殆どのnumpyで書く数値計算はそのままGPU化できる
– ディープラーニングだけにつかうのは勿体無い
l modern gpu/thrust (今回のメイン)
– 離離散的なアルゴリズムをSTLで書ける
– CUDAを⼀一切切書かずにかなり汎⽤用的にアルゴリズムをかける
– コンパイルが遅いのとエラー時に意味不不明
4](https://image.slidesharecdn.com/moremoderngpu-151203045715-lva1-app6891/85/More-modern-gpu-4-320.jpg)



![代表的な並列列処理理 (Prefix-‐‑‒)Scan
l 配列列X[0…n)が与えられた時,Scanは次を求める
– X[i] := X[0] + X[1] + ... + X[i-‐‑‒1] exclusive scan
– X[i] := X[0] + X[1] + … + X[i] inclusive scan
l Scanは次のように並列列に計算できる
– 各X[i]について,X[i] += X[i-‐‑‒1]
– 各X[i]について, X[i] += X[i-‐‑‒2]
– 各X[i]について,X[i] += X[i-‐‑‒4]
– ...
l 例例:X[7]の時,
– X[7] += X[6]
– X[7] += X[5] (=X[4]+X[5])
l これはO(log n)時間で実⾏行行できる
8](https://image.slidesharecdn.com/moremoderngpu-151203045715-lva1-app6891/85/More-modern-gpu-8-320.jpg)


![例例:マージソート (2/2)
逐次的なマージソート
X, Y, Z
ix = 0, iy = 0, iz = 0
while (iz < n+m) {
if (comp(X[ix], Y[iy]) Z[iz++] = X[ix++]
else Z[iz++] = Y[iy++]
}
// 境界条件はcompがうまいことやってくれてることにします
これをどのように分割するのか?
11](https://image.slidesharecdn.com/moremoderngpu-151203045715-lva1-app6891/85/More-modern-gpu-11-320.jpg)
![マージソートの解釈
0 1 3 5 6 6 7 9 10
1
2
2
4
7
8
9
9
10
12
行にA、列にBを並べた行列を考える。
マージソートにおけるZ[iz++] = X[ix++]は右に進む、Z[iz++] = Y[iy++]は下に
進むに対応する
このパスをマージパスと呼ぶ
X[4]=6 < Y[4]=7](https://image.slidesharecdn.com/moremoderngpu-151203045715-lva1-app6891/85/More-modern-gpu-12-320.jpg)
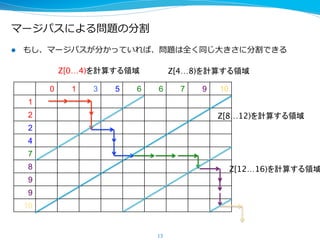

![マージパスによる問題の分割
l マージパスを使えば問題を正確に同じ⼤大きさの問題に分けられる
– マージパスを得るにはマージソートが必要(循環・・)
→マージパスとの交差点は全体を⾒見見なくても求められる
15
0 1 3 5 6 6 7 9 10
1
2
2
4
7
8
9
9
10
この線上で二分探索
X[i] < Y[8 – i]
となる最大のiを求める](https://image.slidesharecdn.com/moremoderngpu-151203045715-lva1-app6891/85/More-modern-gpu-15-320.jpg)


![GPUでMapReduce
l Map+Shuffle(Sort)+ReduceはGPUで効率率率的に実現可能
l MapReduceは最近、分散並列列処理理では⾮非効率率率的と廃れてきたが、扱える計算
クラスは⾮非常に広い
– 分散クラスタでは毎回ディスクに書き込む部分とShuffleがボトルネック
– GPUの場合、⾼高帯域GPUメモリを介して処理理できる
l Map:要素Dから可変⻑⾧長のキーKと値Vのタプルの集合を⽣生成する D-‐‑‒> [K, V]
l Shuffle:同じキーの要素をまとめる [K, V] -‐‑‒> [K, [V]]
l Reduce:値の集合を値に潰す [V] -‐‑‒> Z
l 全体としては [D] -‐‑‒> [K, Z]
18](https://image.slidesharecdn.com/moremoderngpu-151203045715-lva1-app6891/85/More-modern-gpu-18-320.jpg)












![[DL輪読会]Learning Robust Rewards with Adversarial Inverse Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/180201dllearningrobustrewardswithadversarial3-180205170610-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DLHacks 実装] DeepPose: Human Pose Estimation via Deep Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/20170821onodeepposepresentation-170928100207-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]"CyCADA: Cycle-Consistent Adversarial Domain Adaptation"&"Learning Se...](https://cdn.slidesharecdn.com/ss_thumbnails/20180803dlakuzawa-180803003349-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]V-MPO: On-Policy Maximum a Posteriori Policy Optimization for Discrete...](https://cdn.slidesharecdn.com/ss_thumbnails/20200904furuta-200904014839-thumbnail.jpg?width=640&height=640&fit=bounds)




















































