Download as PDF, PPTX




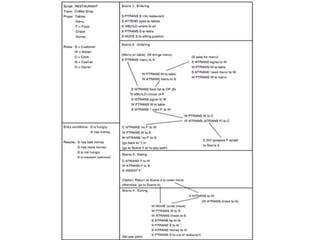


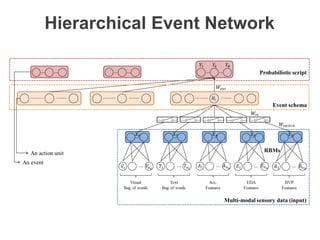
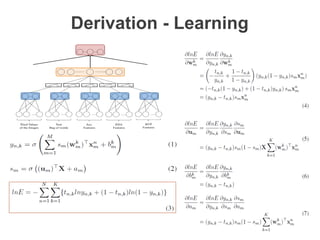

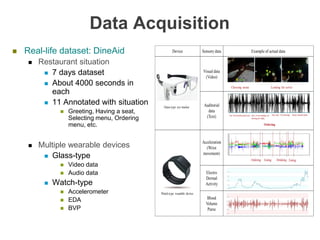
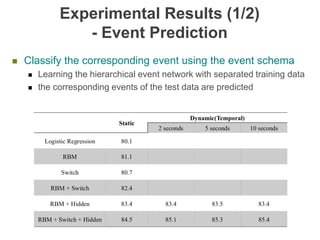
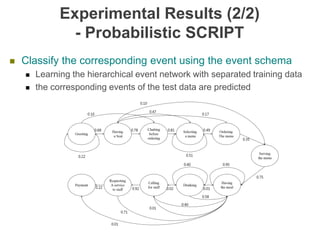

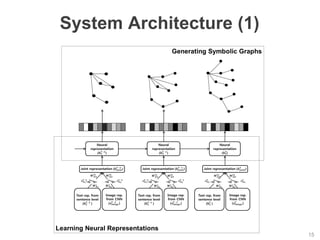
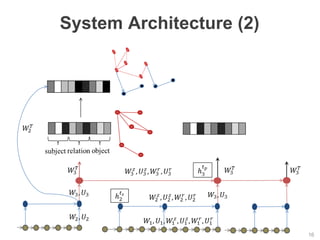
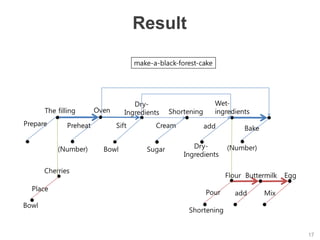

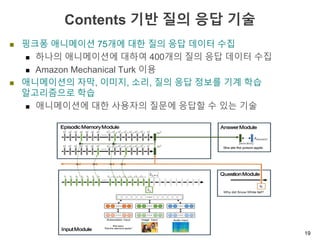
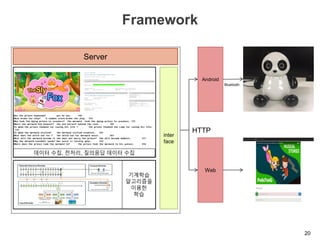
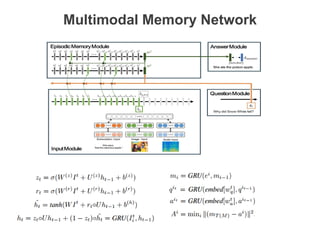
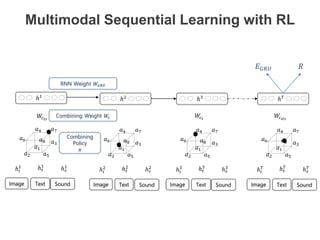



The document discusses multimodal sequential learning, focusing on automatic schema construction and deep learning methods applied to restaurant environments using wearable sensor data. It presents the development of a hierarchical event network and experiments involving event prediction and probabilistic scripts based on collected datasets. Additionally, it explores video question answering systems trained on animated content, integrating various modalities such as text, sound, and images.









































![[2017 PYCON 튜토리얼]OpenAI Gym을 이용한 강화학습 에이전트 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/random-170816031315-thumbnail.jpg?width=640&height=640&fit=bounds)





![[143]알파글래스의 개발과정으로 알아보는 ar 스마트글래스 광학 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/43ar-171016045445-thumbnail.jpg?width=640&height=640&fit=bounds)







































