Download as PDF, PPTX


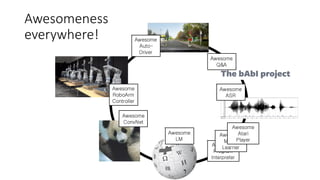
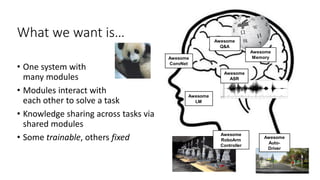
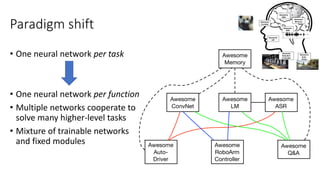
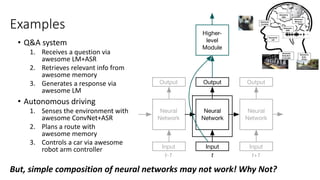






![Few more relevant research directions
• Communicating neural networks
• Neural nets talk to each other to solve a problem
• Sukhbaatar & Fergus (2015), Foerster et al. (2016), Evtimova et al. (2017), Lewis et al. (2017),
…
• Multimodal processing
• Image captioning, zero-shot retrieval, …
• Cho et al. (2015, review paper)
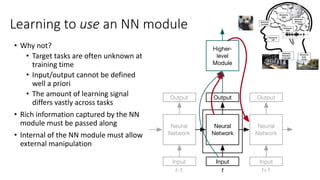
• Planning, program synthesis
• How do the modules compose with each other to solve a task?
• Neural programmer interpreter [Reed et al., 2016; Cai et al., 2017]
• Forward modelling [Henaff et al., 2017; Sutton, 1991 Dyna; optimal control…]
• Mixture of experts [Google], progressive networks [Google DeepMind]](https://image.slidesharecdn.com/deeplearningwhereareyougoing-170825080834/85/Deep-Learning-Where-Are-You-Going-31-320.jpg)

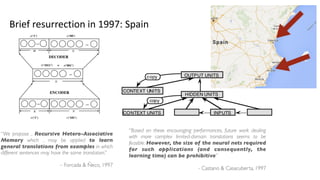
![• [Allen 1987 IEEE 1st ICNN]
• 3310 En-Es pairs constructed on 31
En, 40 Es words, max 10/11 word
sentence; 33 used as test set
• Binary encoding of words – 50
inputs, 66 outputs; 1 or 3 hidden
150-unit layers. Ave WER: 1.3
words
• [Chrisman 1992 Connection Science]
• Dual-ported RAAM architecture
[Pollack 1990 Artificial Intelligence]
applied to corpus of 216 parallel pairs
of simple En-Es sentences:
• Split 50/50 as train/test, 75% of
sentences correctly translated!](https://image.slidesharecdn.com/deeplearningwhereareyougoing-170825080834/85/Deep-Learning-Where-Are-You-Going-35-320.jpg)



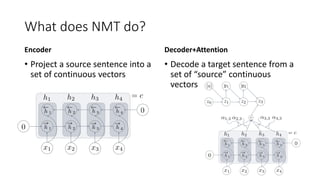
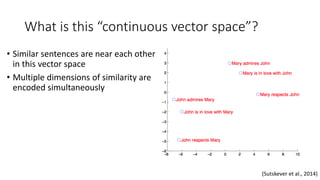

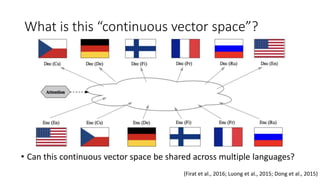
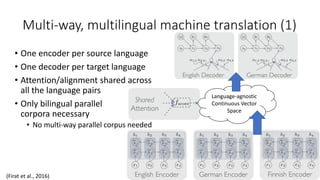










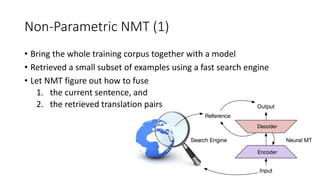
![Non-Parametric NMT (2)
• Apache Lucene: search engine
• A key-value memory network
[Gulcehre et al., 2017; Miller et al., 2016]
for storing retrieved pairs
• Similar to larger-context NMT
• [Wang et al., 2017;
Jean et al., 2017]
• Similar to NMT with external
knowledge
• [Ahn et al., 2016;
Bahdanau et al., 2017]](https://image.slidesharecdn.com/deeplearningwhereareyougoing-170825080834/85/Deep-Learning-Where-Are-You-Going-62-320.jpg)
![Other advances in neural machine translation
• Discourse-level machine translation
• [Jean et al., 2017; DCU, 2017]
• Better decoding strategies
• Learning-to-search [Wiseman & Rush, 2016]
• Reinforcement learning [MRT, 2016; Ranzato et al., 2015; Bahdanau et al., 2015]
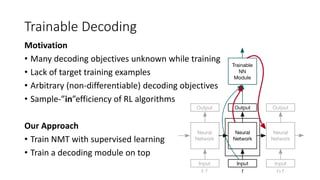
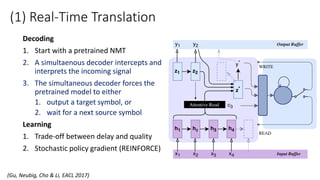
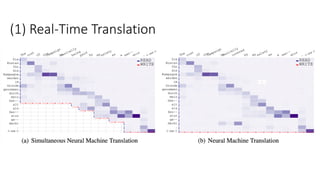
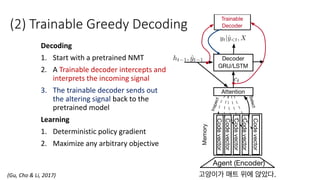
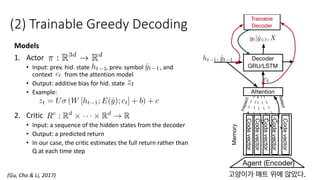
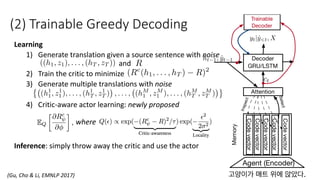
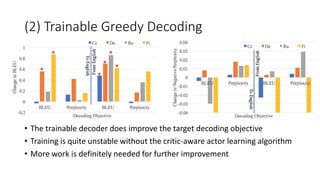
• Trainable decoding [Gu et al., 2017]
• Alternative decoding cost [Li et al., 2016; Li et al., 2017]
• Linguistics-guided neural machine translation
• Learning to parse and translate [Eriguchi et al., 2017; Rohee & Goldberg, 2017; Luong
et al., 2016]
• Syntax-aware neural machine translation [Nadejde et al., 2017]](https://image.slidesharecdn.com/deeplearningwhereareyougoing-170825080834/85/Deep-Learning-Where-Are-You-Going-64-320.jpg)

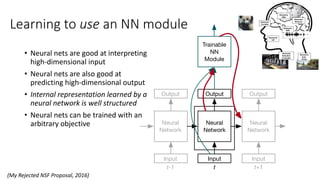
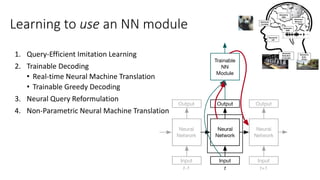
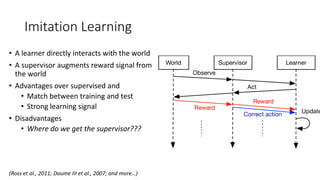
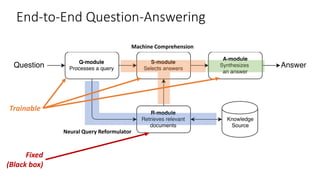
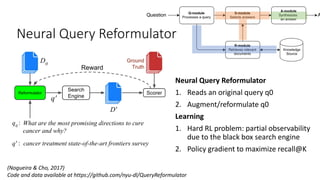
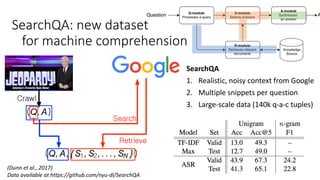
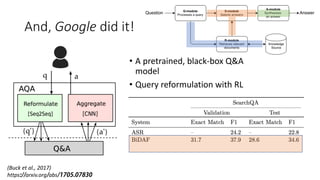
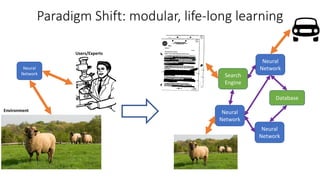
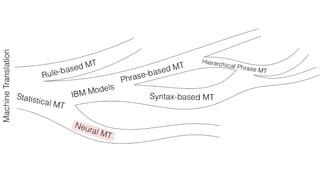
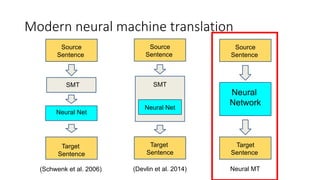
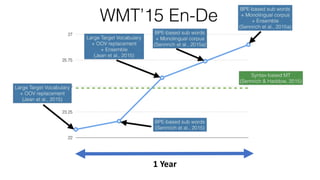
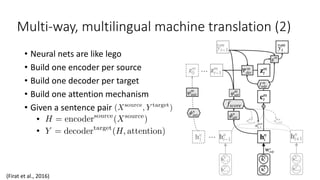
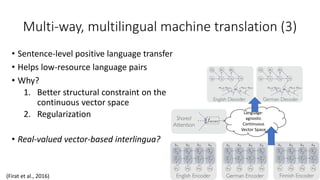
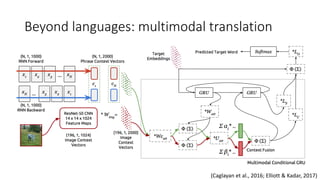
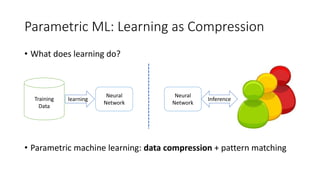
The document discusses advances in deep learning, highlighting the modular design of neural networks that allows for cooperation between different tasks and functions. It emphasizes the need for transparent yet comprehensible network architectures that facilitate learning through imitation and query-efficient methods. Additionally, it explores applications in real-time translation and question answering, proposing non-parametric machine translation as a method for enhancing consistency and accuracy in language processing.

![[GAN by Hung-yi Lee]Part 3: The recent research of my group](https://cdn.slidesharecdn.com/ss_thumbnails/part3v2-180809095433-thumbnail.jpg?width=640&height=640&fit=bounds)


![[KDD 2018 tutorial] End to-end goal-oriented question answering systems](https://cdn.slidesharecdn.com/ss_thumbnails/kdd2018tutorialend-to-endgoal-orientedquestionansweringsystems-180821081440-thumbnail.jpg?width=640&height=640&fit=bounds)


![[AAAI 2019 tutorial] End-to-end goal-oriented question answering systems](https://cdn.slidesharecdn.com/ss_thumbnails/aaai2019tutorialend-to-endgoal-orientedquestionansweringsystems-190128122117-thumbnail.jpg?width=640&height=640&fit=bounds)
































![[2017 PYCON 튜토리얼]OpenAI Gym을 이용한 강화학습 에이전트 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/random-170816031315-thumbnail.jpg?width=640&height=640&fit=bounds)





![[124]자율주행과 기계학습](https://cdn.slidesharecdn.com/ss_thumbnails/124-171016052833-thumbnail.jpg?width=640&height=640&fit=bounds)






![[246]QANet: Towards Efficient and Human-Level Reading Comprehension on SQuAD](https://cdn.slidesharecdn.com/ss_thumbnails/246qanetdeview2018-181012000849-thumbnail.jpg?width=640&height=640&fit=bounds)





















































