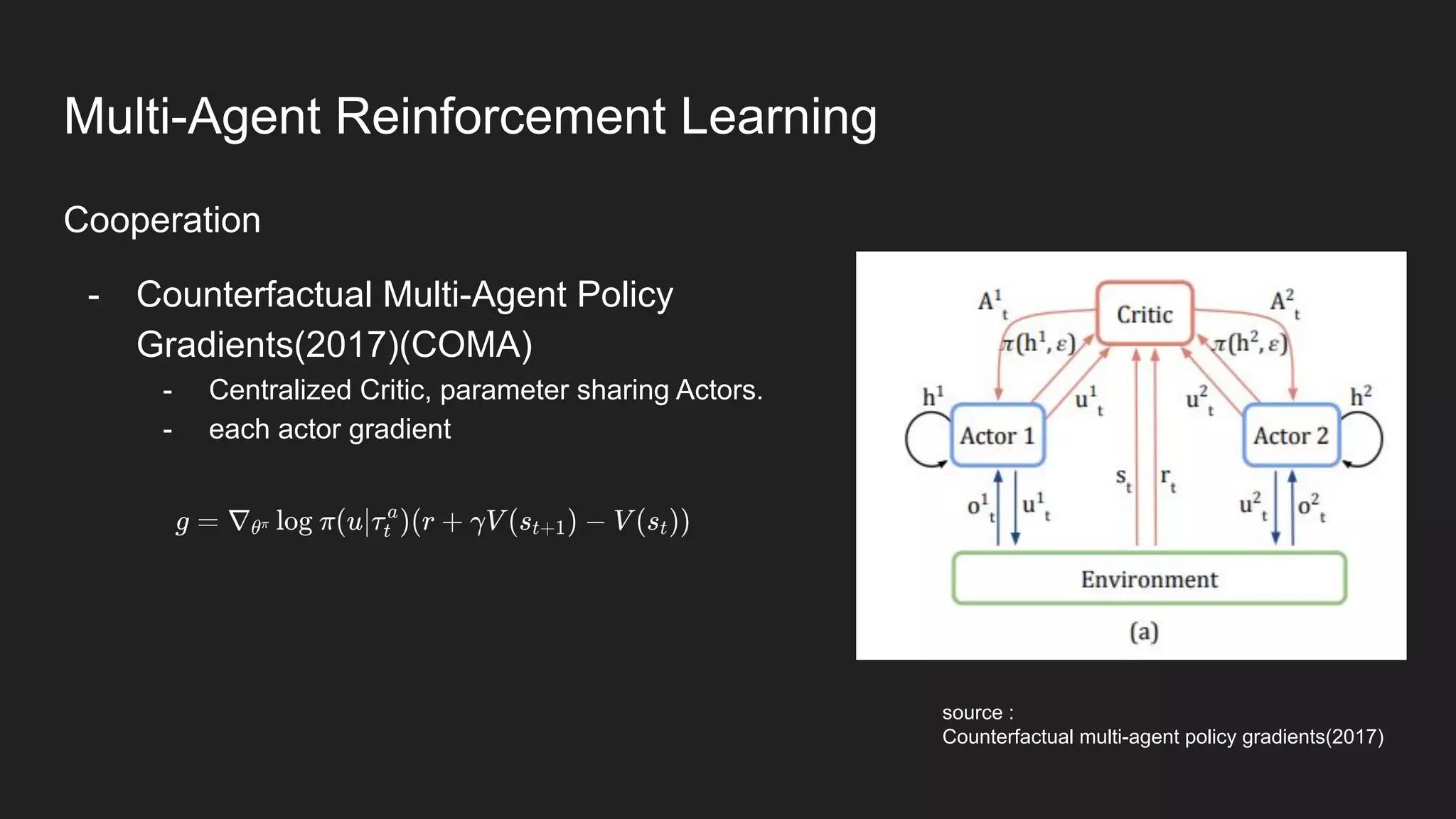
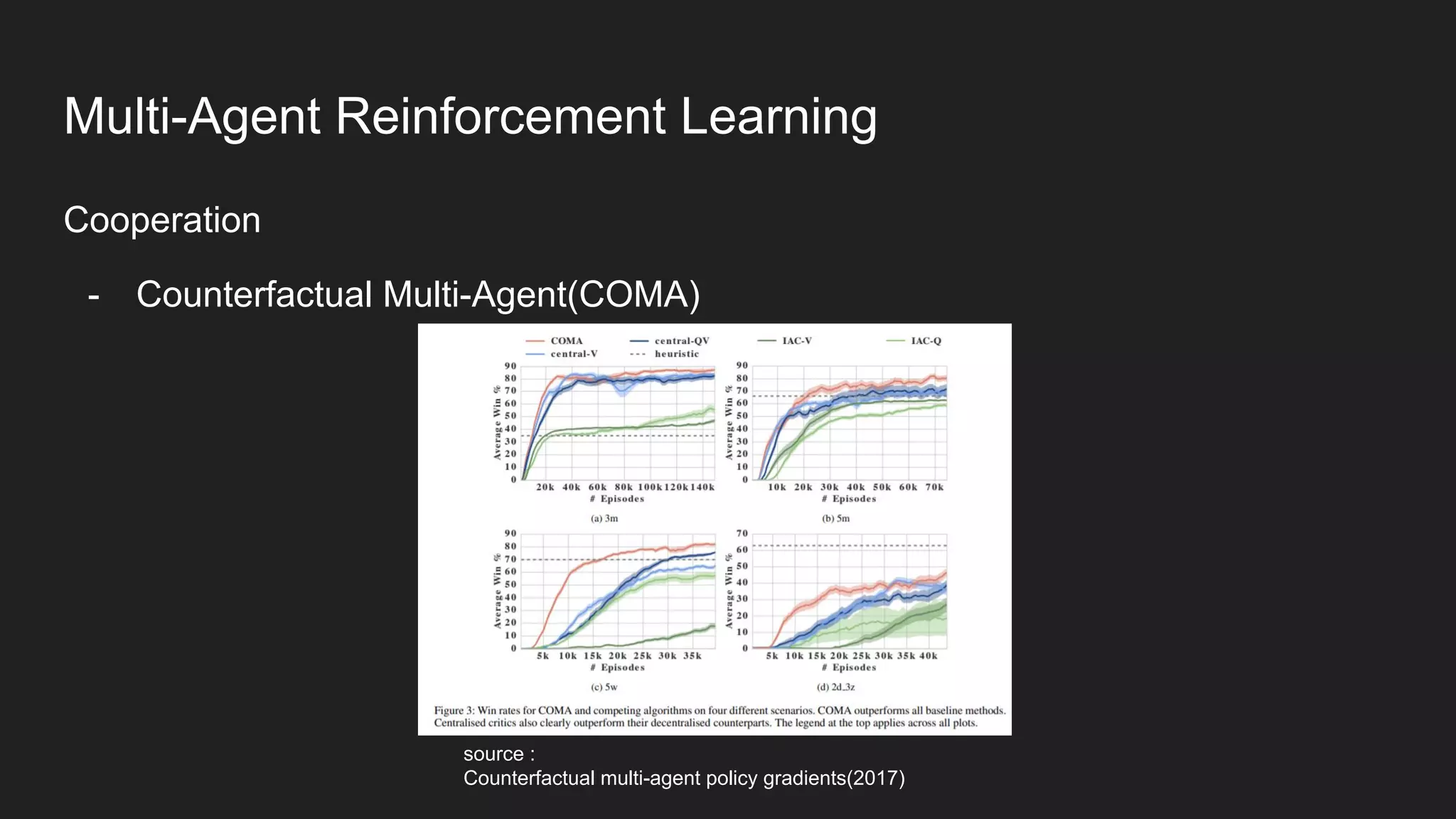
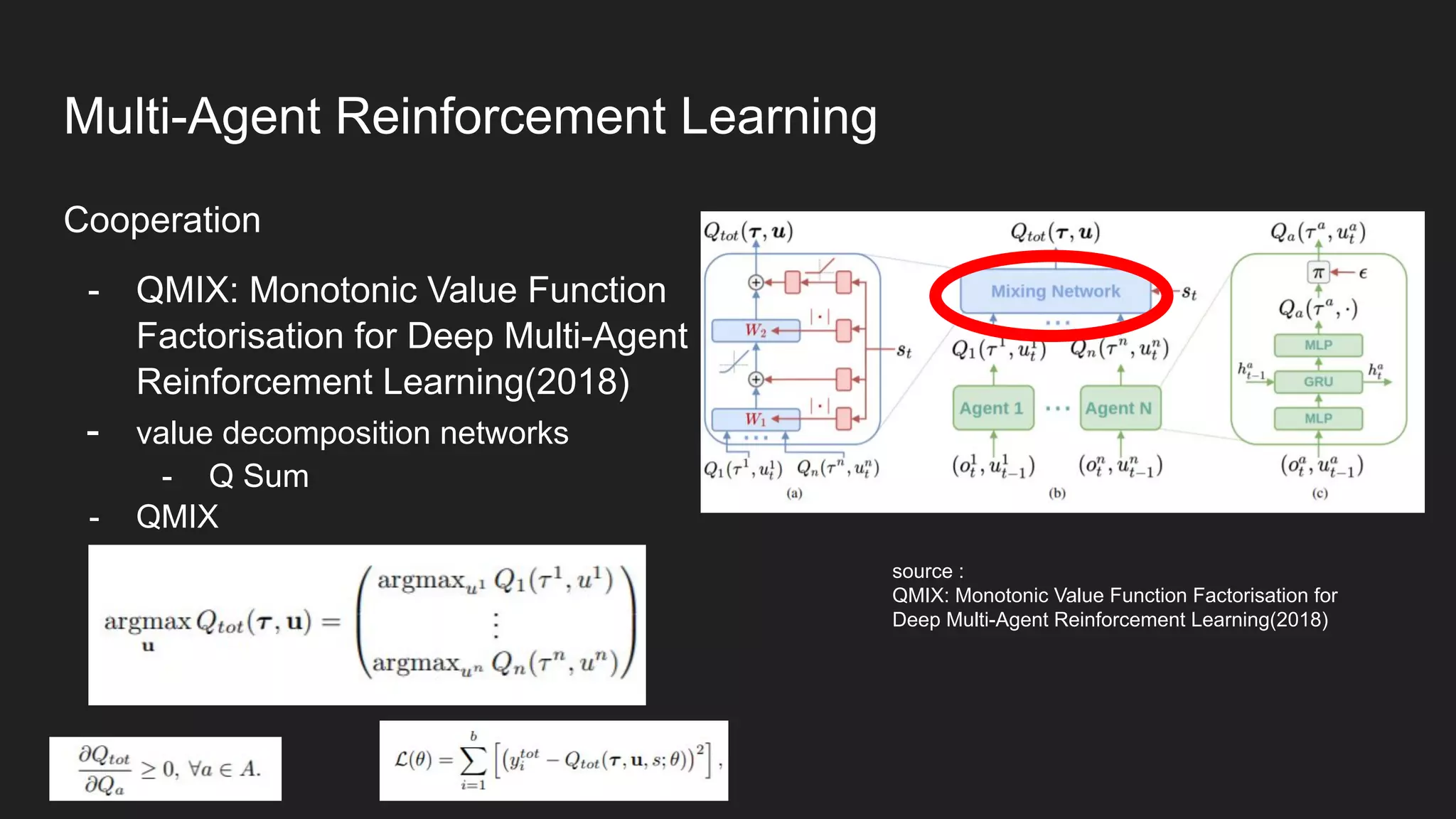
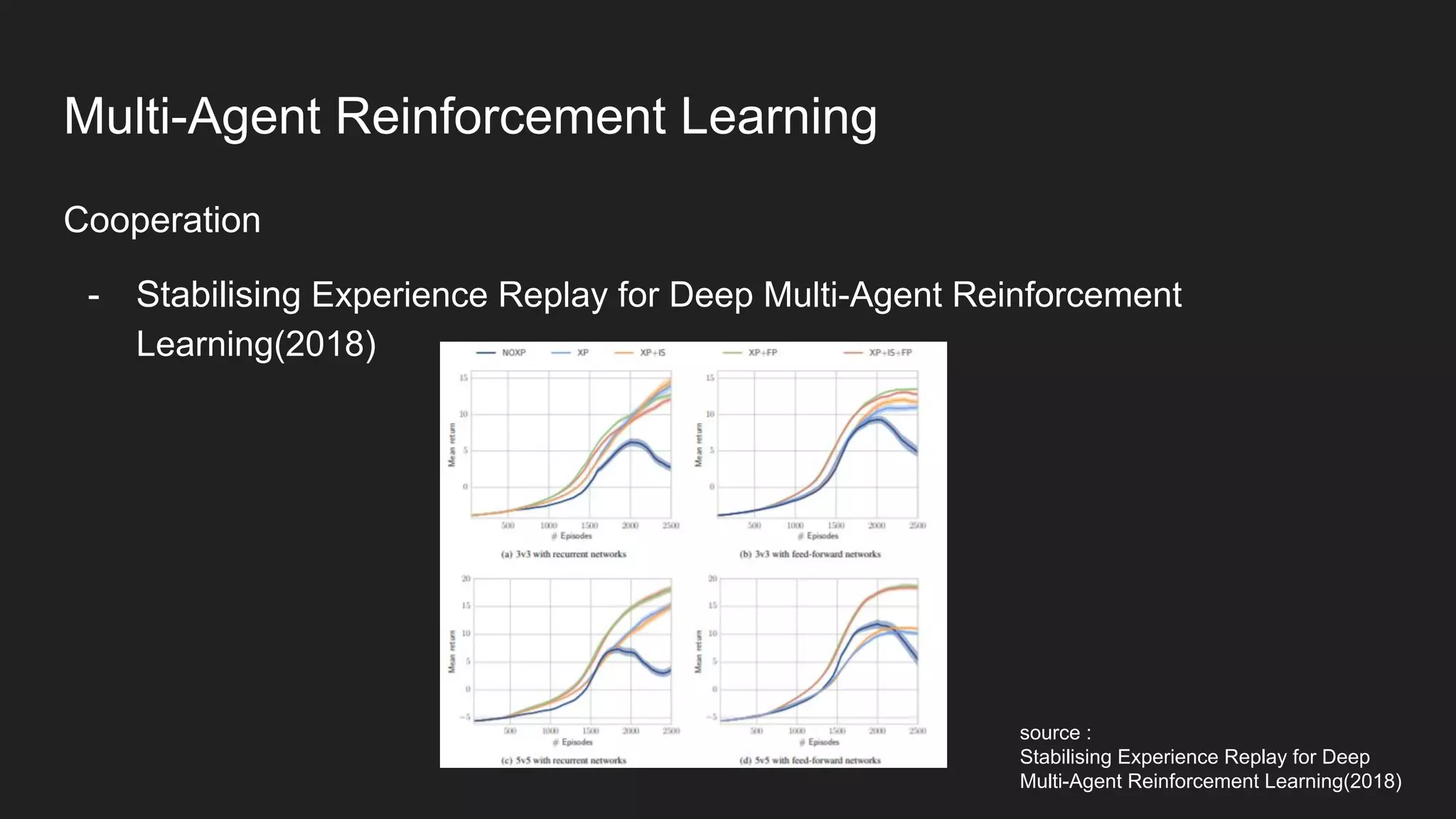
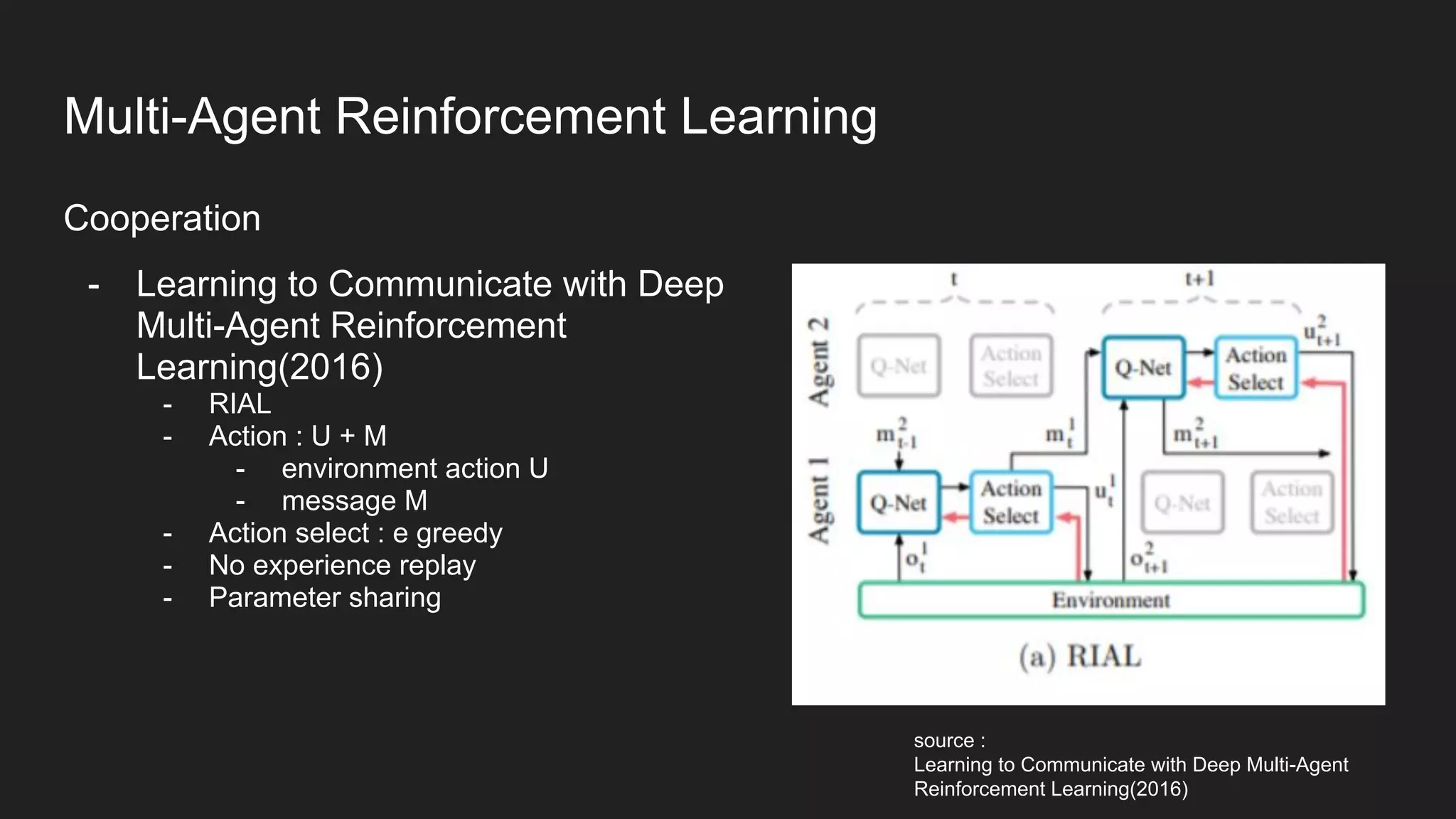
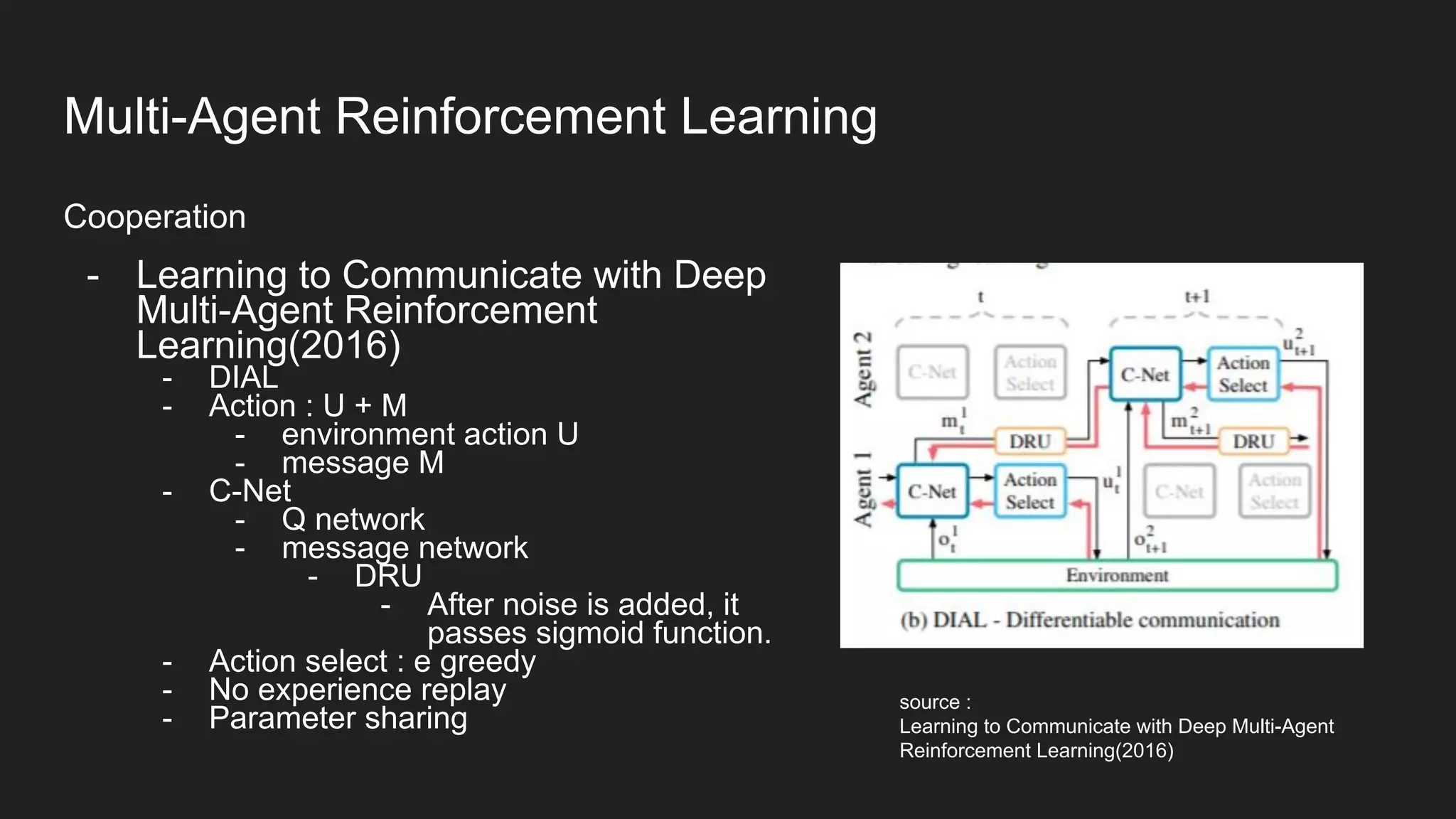
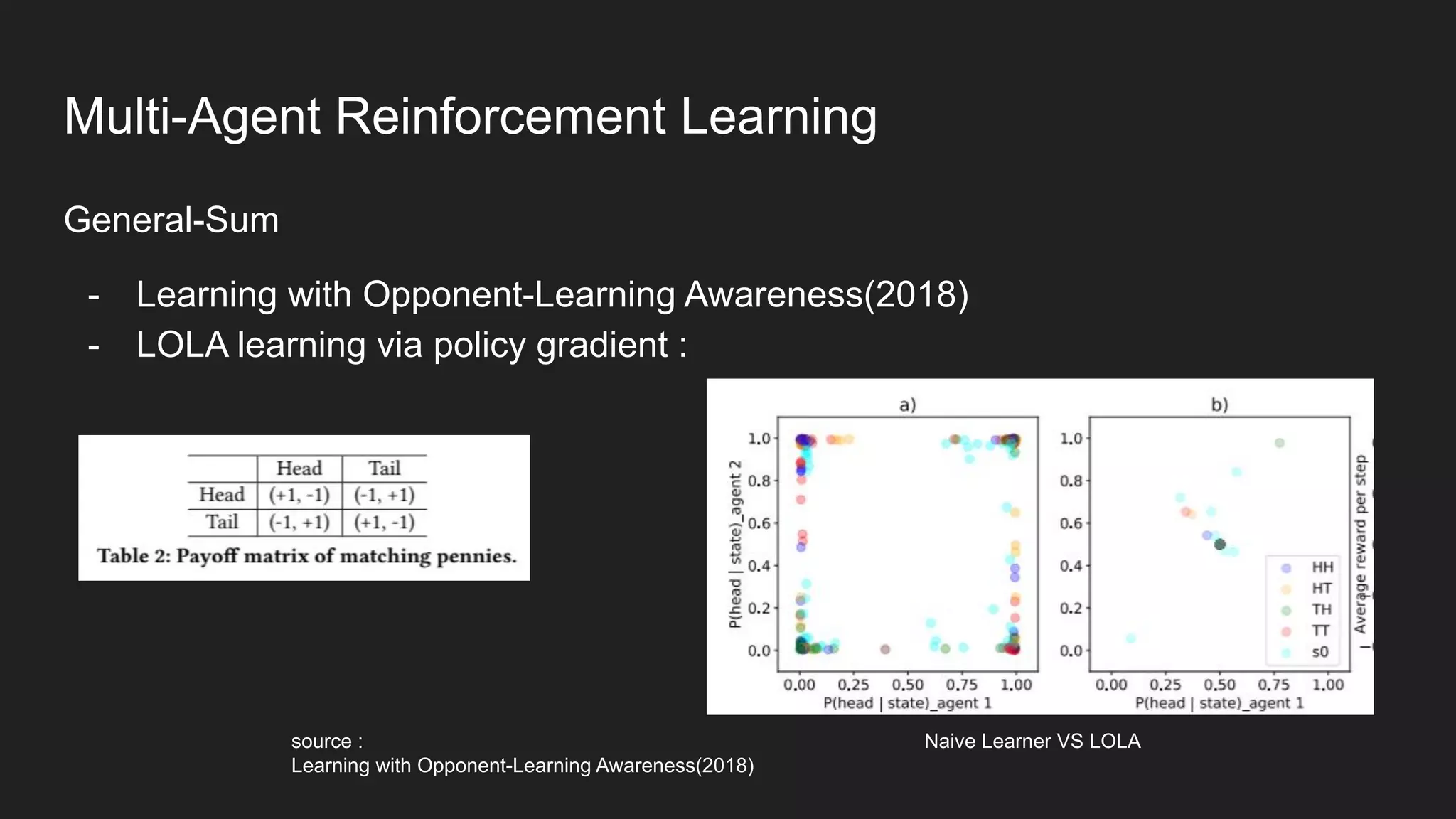
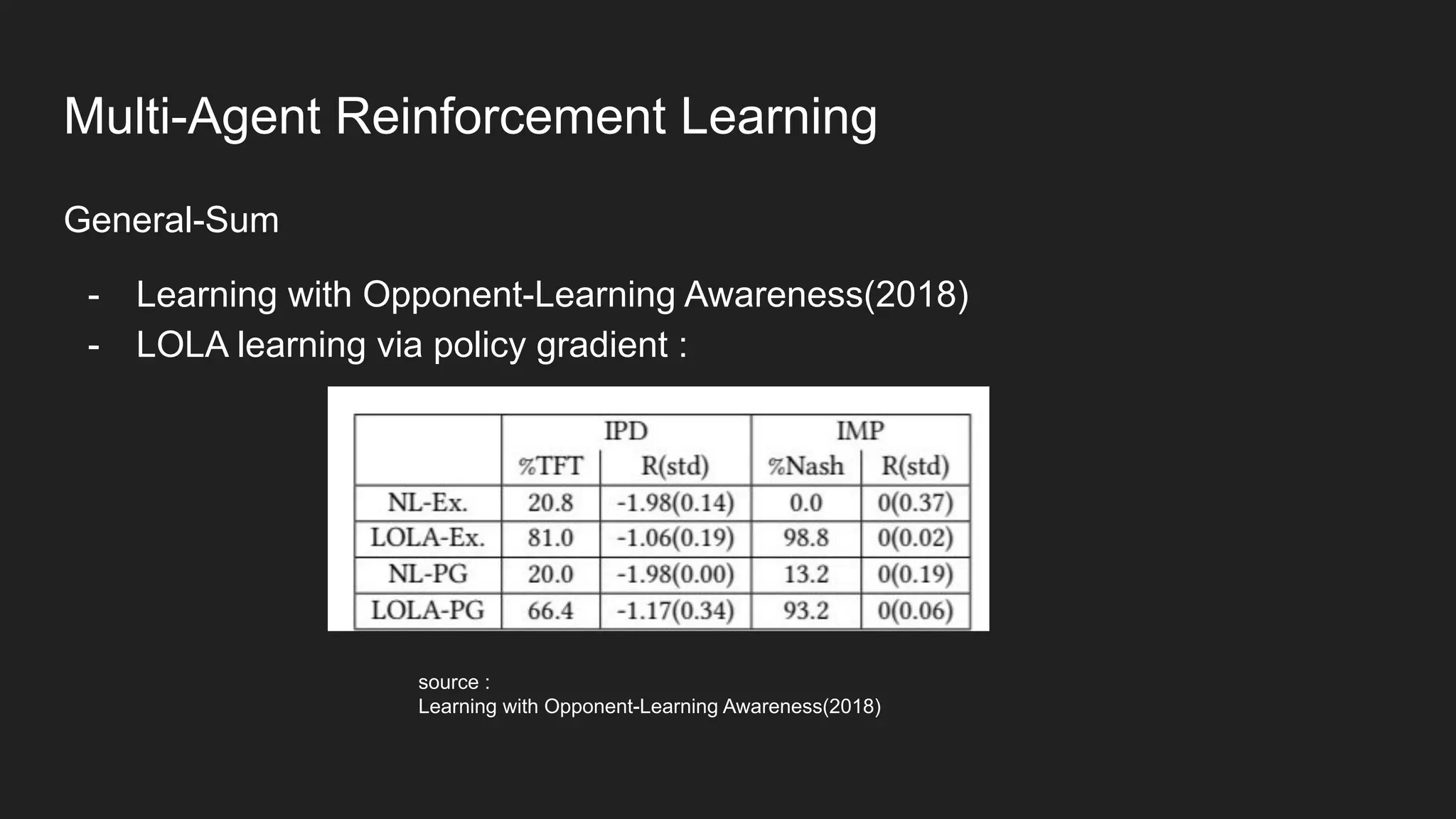
Multi-Agent Reinforcement Learning is an extension of single-agent RL to problems with multiple interacting agents. It is challenging due to non-stationary environments and credit assignment across agents. Baseline methods like Independent Q-Learning treat other agents as part of the environment. Cooperation methods use centralized critics and decentralized actors. Zero-sum methods were applied to StarCraft. General-sum methods like LOLA learn opponent models to optimize strategies. Experience replay and communication protocols help agents learn cooperative behaviors.













































![6. Wikipedia contributors. (2021, March 2). Extensive-form game. In Wikipedia, The Free
Encyclopedia. Retrieved 06:10, August 9, 2021, from
https://en.wikipedia.org/w/index.php?title=Extensive-form_game&oldid=1009744715
7. Wikipedia contributors. (2021, July 8). Common knowledge (logic). In Wikipedia, The Free
Encyclopedia. Retrieved 06:11, August 9, 2021, from
https://en.wikipedia.org/w/index.php?title=Common_knowledge_(logic)&oldid=1032661454
8. Wikipedia contributors. (2021, March 2). Repeated game. In Wikipedia, The Free Encyclopedia.
Retrieved 06:11, August 9, 2021, from
https://en.wikipedia.org/w/index.php?title=Repeated_game&oldid=1009754520
9. Foerster, J. N. (2018). Deep multi-agent reinforcement learning [PhD thesis]. University of Oxford
Reference](https://image.slidesharecdn.com/multi-agentreinforcementlearningseolhokim-210810105106/75/Multi-Agent-Reinforcement-Learning-62-2048.jpg)
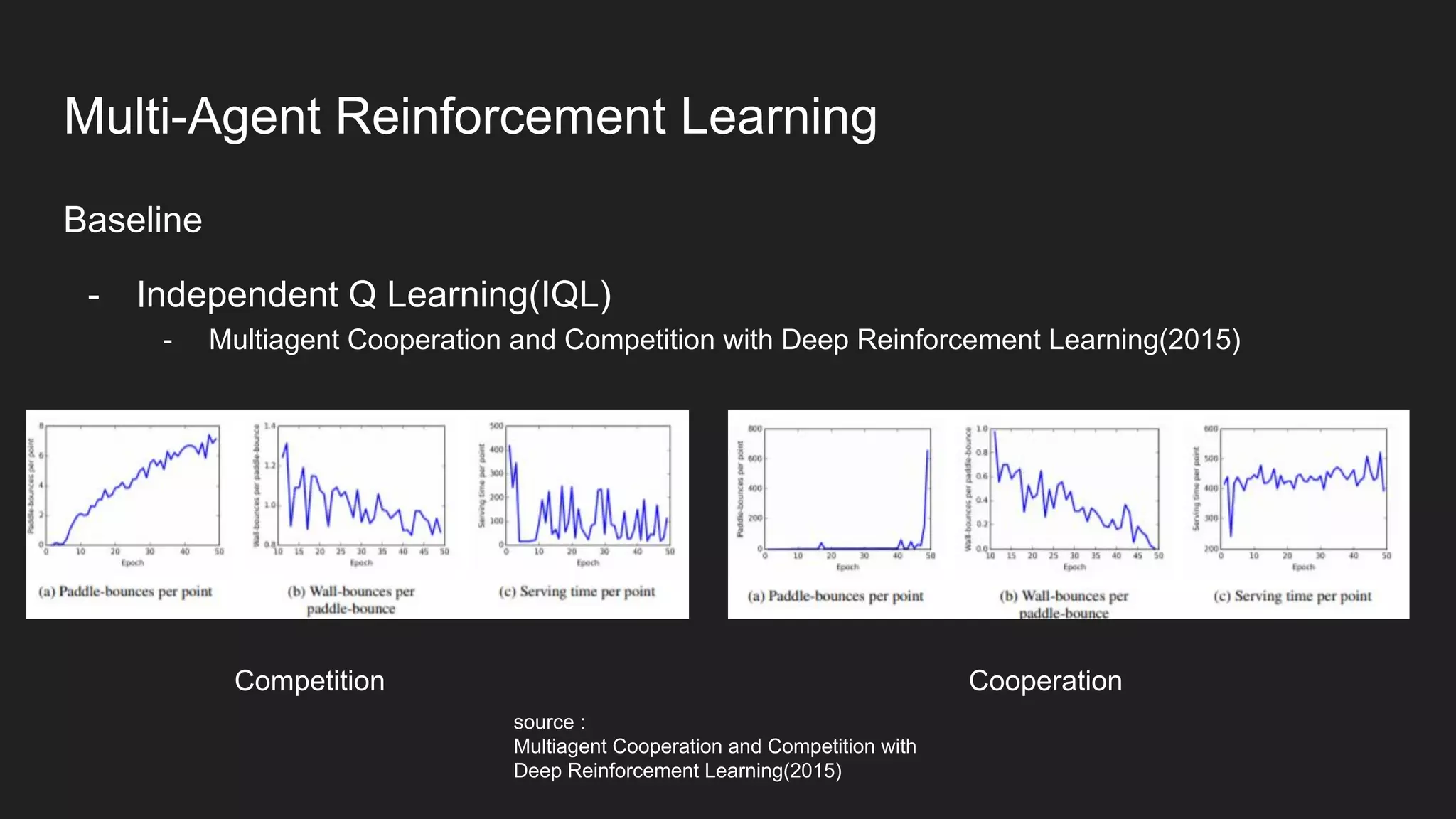
![10. Tampuu, A., Matiisen, T., Kodelja, D., Kuzovkin, I., Korjus, K., Aru, J., Aru, J., & Vicente, R. (2017).
Multiagent cooperation and competition with deep reinforcement learning. PLOS ONE, 12(4),
e0172395. https://doi.org/10.1371/journal.pone.0172395
11. Jakob Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, Shimon Whiteson,
(2018). Counterfactual Multi-Agent Policy Gradients, AAAI Conference on Artificial Intelligence
12. Rashid, T., Samvelyan, M., de Witt, C. S., Farquhar, G., Foerster, J. N., & Whiteson, S. (2018).
QMIX - monotonic value function factorisation for deep multi-agent reinforcement learning. In
International conference on machine learning.
13. Christian A. Schroeder de Witt, Jakob N. Foerster, Gregory Farquhar, Philip H. S. Torr, Wendelin
Boehmer, and Shimon Whiteson(2018). Multi-Agent Common Knowledge Reinforcement Learning.
arXiv:1810.11702 [cs] URL http://arxiv.org/abs/1810.
Reference](https://image.slidesharecdn.com/multi-agentreinforcementlearningseolhokim-210810105106/75/Multi-Agent-Reinforcement-Learning-63-2048.jpg)
![14. Foerster, J., Nardelli, N., Farquhar, G., Afouras, T., Torr, P.H.S., Kohli, P. & Whiteson, S.. (2017).
Stabilising Experience Replay for Deep Multi-Agent Reinforcement Learning. Proceedings of the 34th
International Conference on Machine Learning, in Proceedings of Machine Learning Research
70:1146-1155 Available from http://proceedings.mlr.press/v70/foerster17b.html
15. J. N. Foerster, Y. M. Assael, N. de Freitas, and S. Whiteson(2016). Learning to communicate with
deep multi-agent reinforcement learning. CoRR, abs/1605.06676,
16.Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., van den Driessche, G., Schrittwieser, J.,
Antonoglou, I., Panneershelvam, V., Lanctot, M., Dieleman, S., Grewe, D., Nham, J., Kalchbrenner, N.,
Sutskever, I., Lillicrap, T., Leach, M., Kavukcuoglu, K., Graepel, T., & Hassabis, D. (2016).
Mastering the game of go with deep neural networks and tree search. Nature, 529(7587), 484–489.
https://doi.org/10.1038/nature16961
17. J. N. Foerster et al.(2017), Learning with opponent-learning awareness. arXiv:1709.04326 [cs.AI]
Reference](https://image.slidesharecdn.com/multi-agentreinforcementlearningseolhokim-210810105106/75/Multi-Agent-Reinforcement-Learning-64-2048.jpg)
![17. Chung-san, R. (2016, December 3). ‘알파고 시대’ 우리 교육, 어떻게 나아가야 하나?
서울특별시교육청. https://now.sen.go.kr/2016/12/03.php
18. DeepMind. (2020, May 31). Agent57: Outperforming the human Atari benchmark.
https://deepmind.com/blog/article/Agent57-Outperforming-the-human-Atari-benchmark
19. AlphaStar: Mastering the Real-Time Strategy Game StarCraft II. (2019, January 24). DeepMind.
https://deepmind.com/blog/article/alphastar-mastering-real-time-strategy-game-starcraft-ii
20. Multi-Agent Hide and Seek. (2019, September 17). [Video]. YouTube.
https://www.youtube.com/watch?v=kopoLzvh5jY
21. Tayagkrischelle, T. (2014, September 13). game theorA6 [Slides]. Slideshare.
https://www.slideshare.net/tayagkrischelle/game-theora6
22. Lanctot, M. [ Laber Labs]. (2020, May 16). Multi-agent Reinforcement Learning - Laber Labs
Workshop [Video]. YouTube. https://www.youtube.com/watch?v=rbZBBTLH32o
Reference](https://image.slidesharecdn.com/multi-agentreinforcementlearningseolhokim-210810105106/75/Multi-Agent-Reinforcement-Learning-65-2048.jpg)



































































