Download as PDF, PPTX







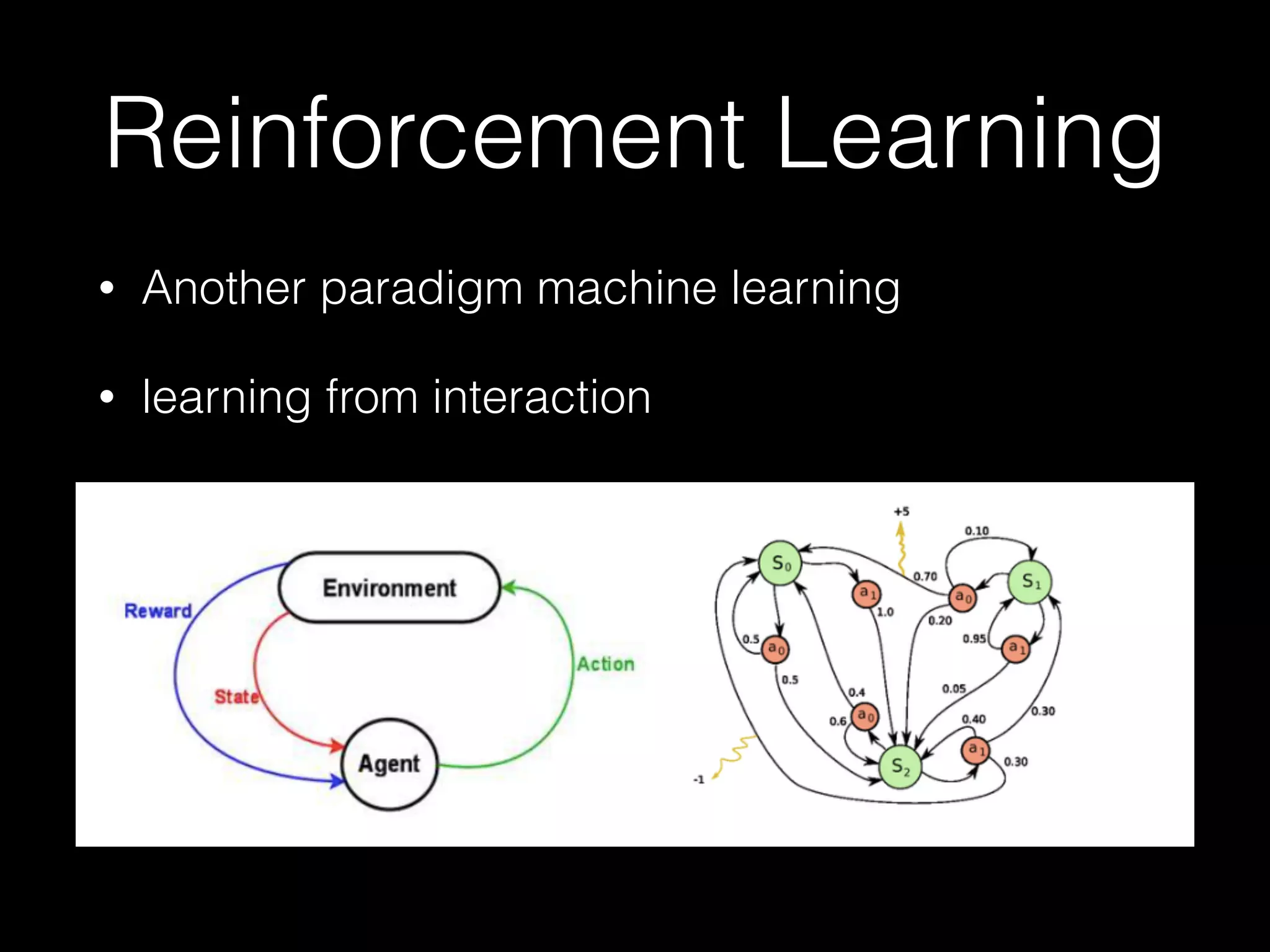
![Reinforcement Learning
• Reinforcement learning is an area of machine learning
inspired by behaviorist psychology, concerned with how
software agents ought to take actions in an environment
so as to maximize some notion of cumulative reward. [the
definition from wikipedia]](https://image.slidesharecdn.com/3zlnjhqaqbxjykyra0rg-signature-75e9a9fb01497dbef5ae930bc81a6f5b2e18a0bcd6c93361bf8f76cefb13a96d-poli-160430143340/75/Shanghai-deep-learning-meetup-4-8-2048.jpg)

























![Go Deeper Reinforcement
Learning
• Deep Q-Network [Volodymyr Mnih]](https://image.slidesharecdn.com/3zlnjhqaqbxjykyra0rg-signature-75e9a9fb01497dbef5ae930bc81a6f5b2e18a0bcd6c93361bf8f76cefb13a96d-poli-160430143340/75/Shanghai-deep-learning-meetup-4-35-2048.jpg)

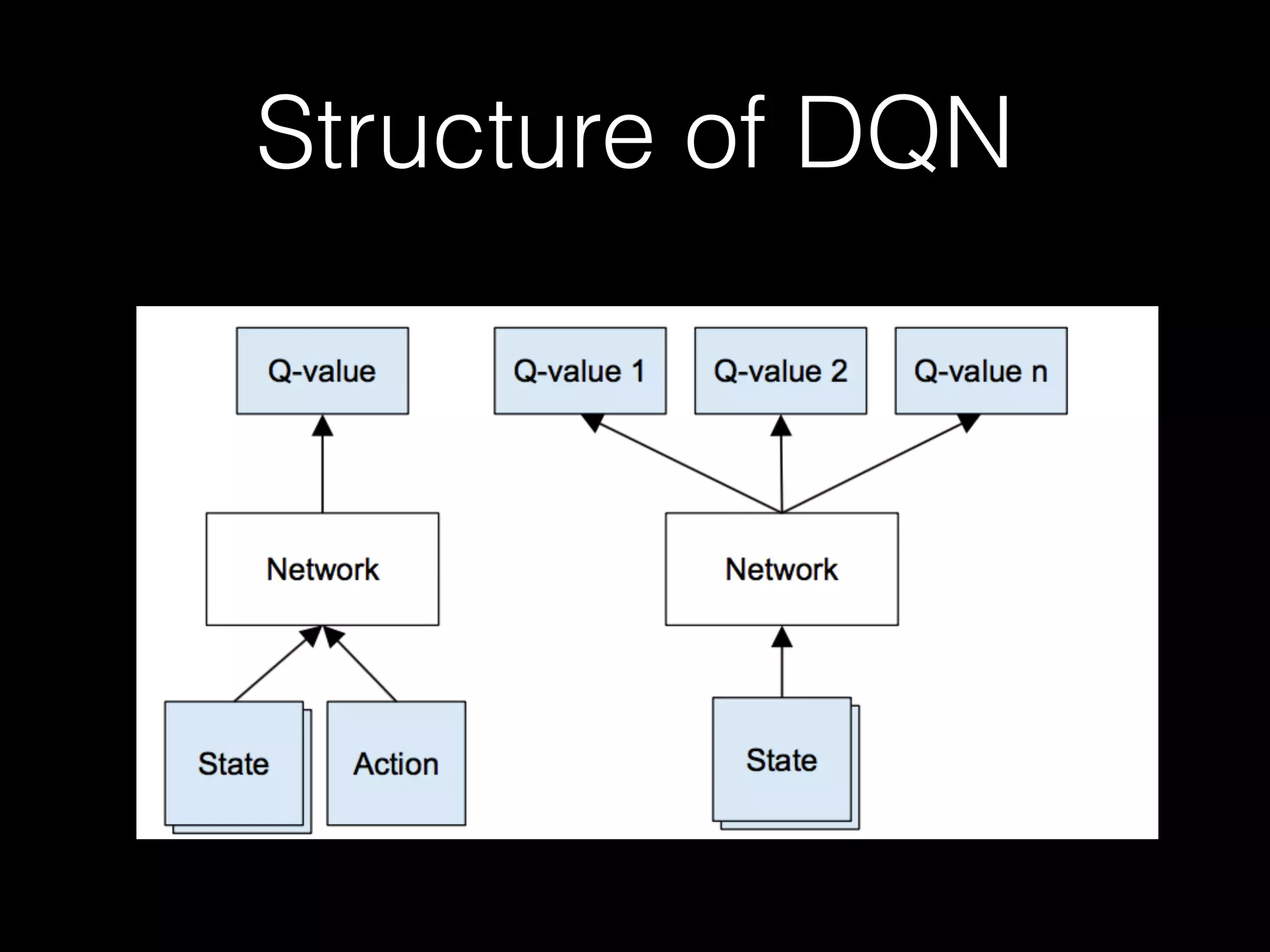
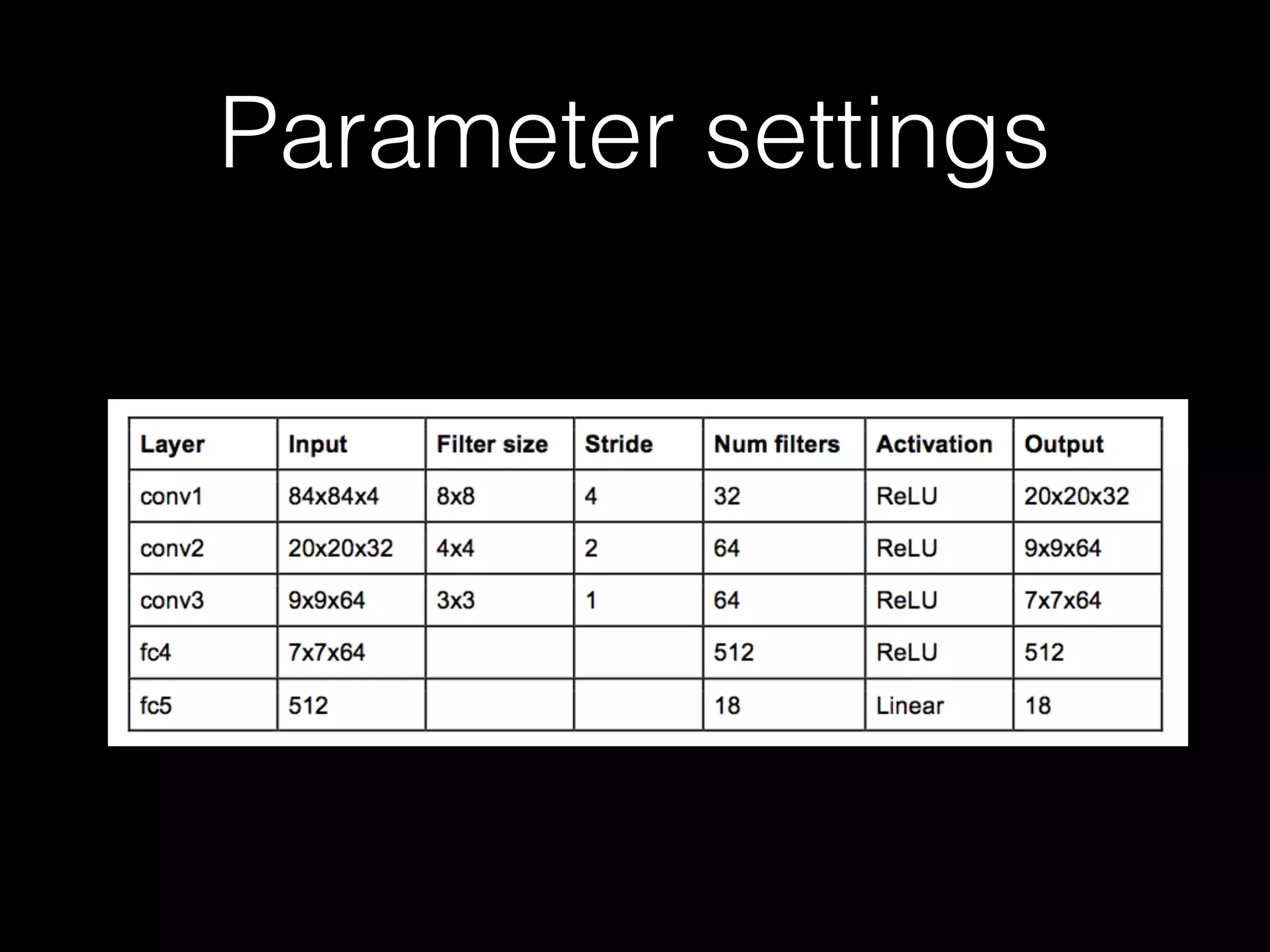






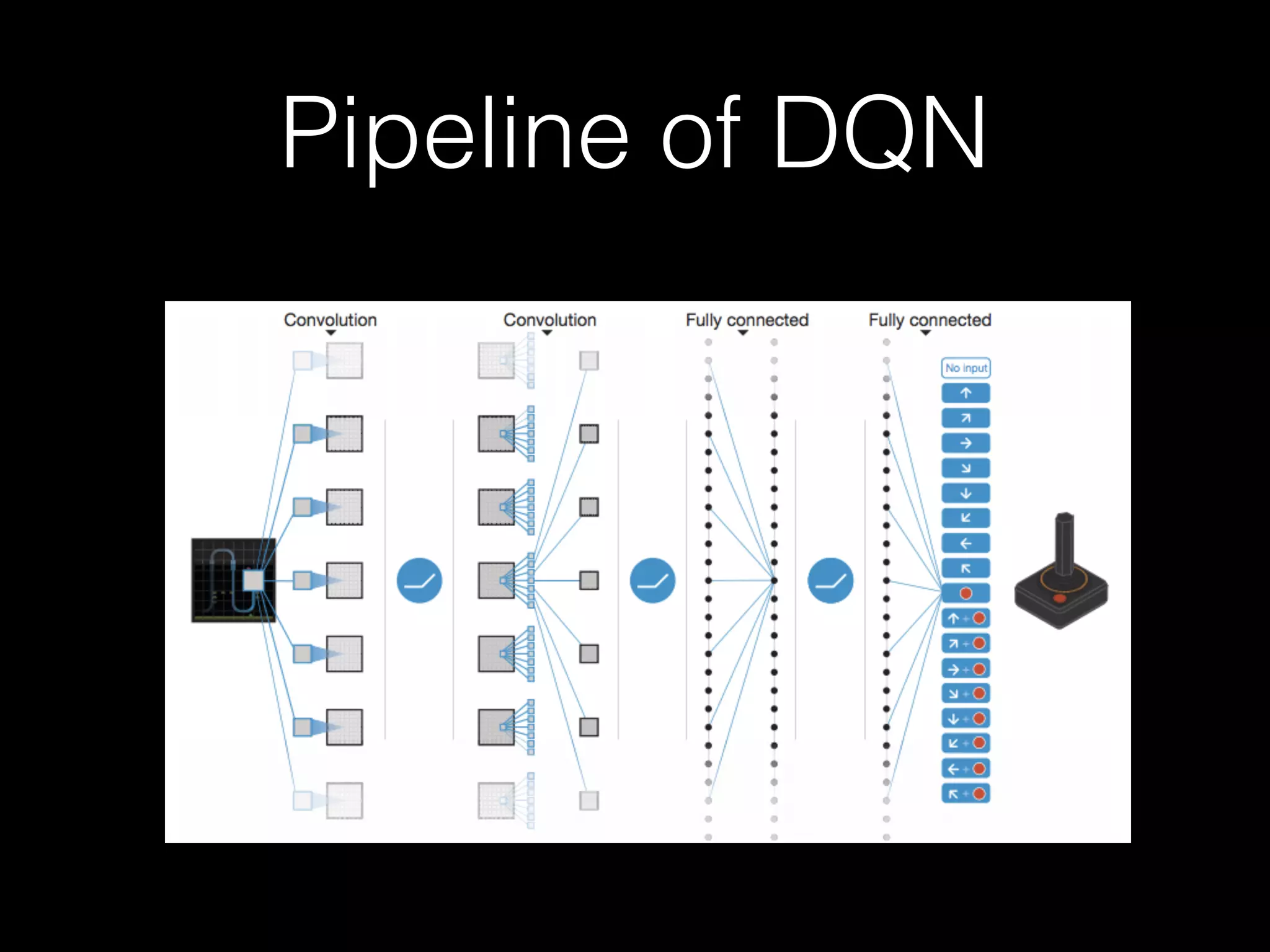
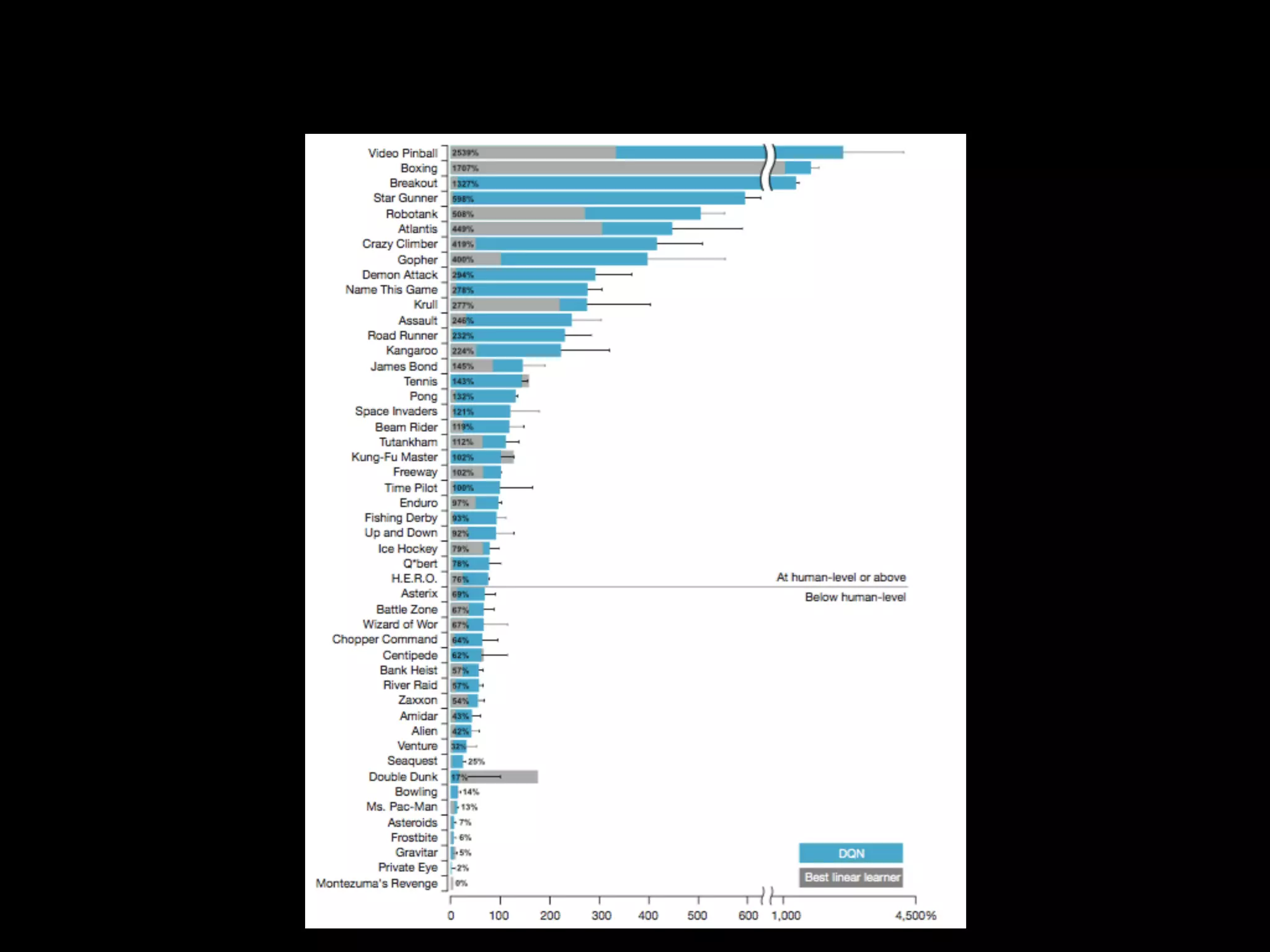
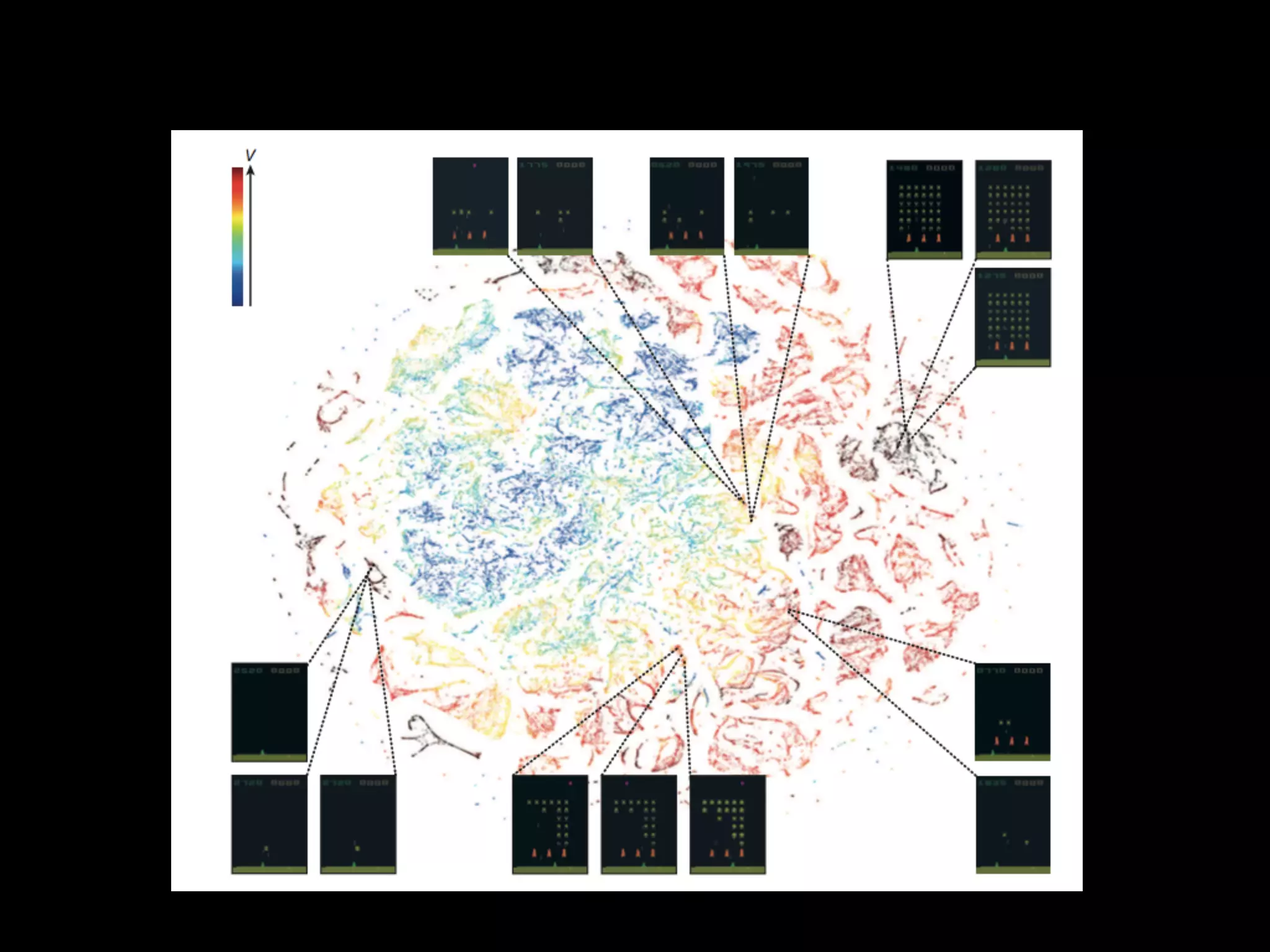
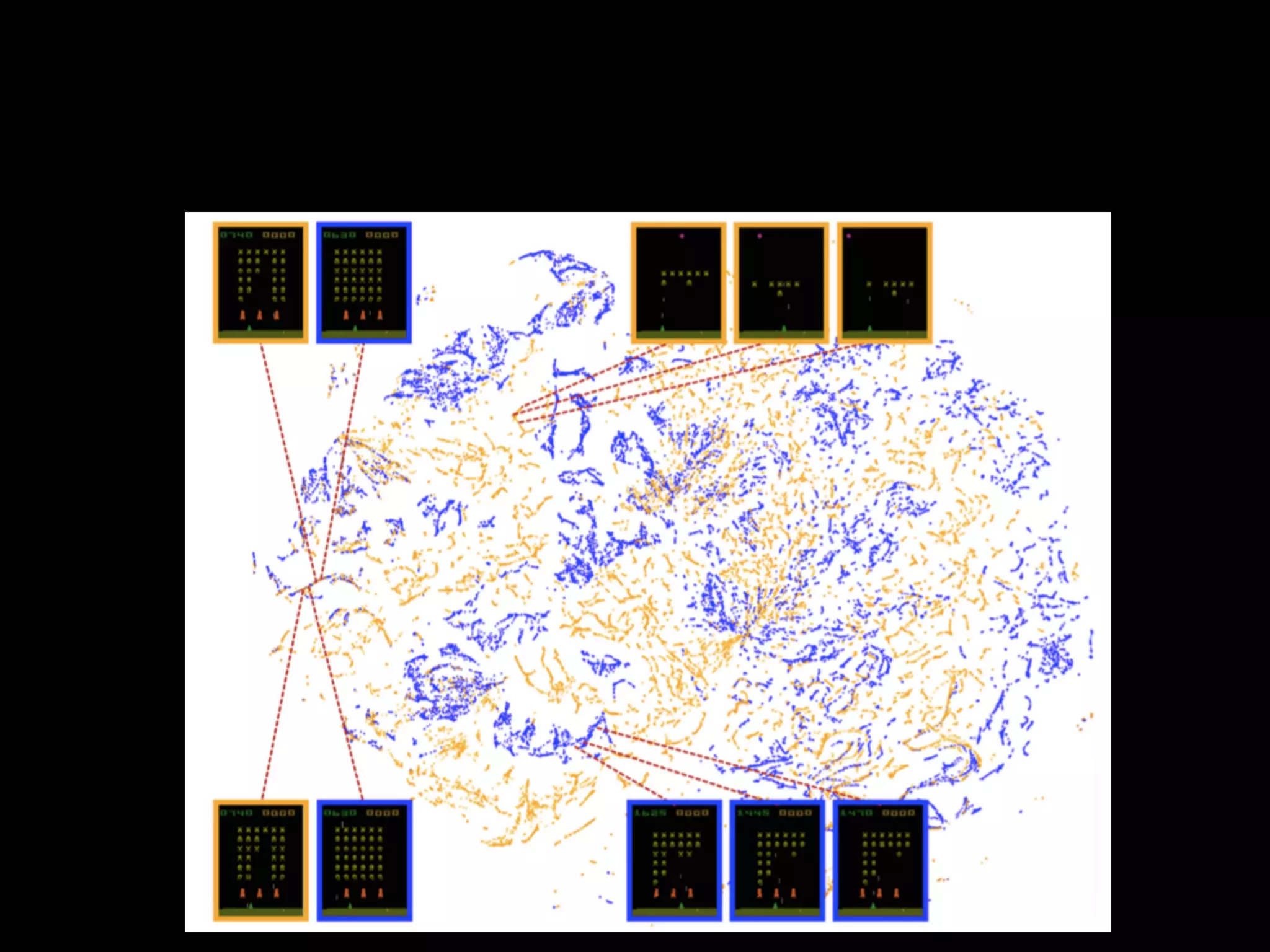












The document summarizes discussions from several Deep Learning meetups in Shanghai. It provides an overview of reinforcement learning concepts like Markov Decision Processes and Q-learning. It then describes how Deep Q-Networks were used to solve Atari games by representing the Q-table with a deep neural network and using experience replay. Finally, it discusses benchmarks and platforms for reinforcement learning like OpenAI Gym and potential directions for the Deep Learning program.














































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)









