Download as PDF, PPTX












![Candidate Region Generation
• Foreground confidence
• Measure the foreground confidence of each candidate region
• Appearance confidence 𝜙𝑖
(𝑡)
• Obtain a saliency map using technique in [1]
• Average the saliency values within the candidate region
• Edge confidence 𝜓𝑖
(𝑡)
• Combine color-based edge map and motion-based edge map
𝑐𝑖
(𝑡)
= 𝜙𝑖
(𝑡)
+ 𝜓𝑖
(𝑡)
[1] W.-D. Jang, C. Lee, and C.-S. Kim, “Primary object segmentation in videos via alternate convex optimization of foreground and
background distributions,” CVPR, 2016](https://image.slidesharecdn.com/naver-171102015242/85/Video-Object-Segmentation-in-Videos-13-320.jpg)







![• DAVIS dataset [2]
• 50 video sequences (3,455 annotated frames)
• Performance measure
• Region similarity 𝒥: Intersection over union
• Contour accuracy ℱ: F-measure that is the harmonic mean of the
contour precision and recall rates
Experimental results
[2] F. Perazzi, J. Pont-Tuset, B. McWilliams, L. Van Gool, M. Gross, and A. Sorkine-Hornung, “A benchmark dataset and evaluation
methodology for video object segmentation,” CVPR 2016](https://image.slidesharecdn.com/naver-171102015242/85/Video-Object-Segmentation-in-Videos-23-320.jpg)
![Experimental results
• Impacts of ARP
• Compare ARP with the conventional refinement techniques [20,
36]
• Apply refinement techniques to our initial regions (IR)
[20] A. Papazoglou and V. Ferrari, “Fast object segmentation in unconstrained video,” ICCV,2013.
[36] D. Zhang, O. Javed, and M. Shah, “Video object segmentation through spatially accurate and temporally dense extraction of
primary object regions,” CVPR, 2013.](https://image.slidesharecdn.com/naver-171102015242/85/Video-Object-Segmentation-in-Videos-24-320.jpg)




![Object Track Generation
• Joint detection and tracking
• Detector [3]
• Find object location without manual annotations
• Some objects may remain undetected
• Tracker [4]
• Boost the recall rate of objects using temporal correlations
• Three cases
• Both detection and tracking boxes
• Only detection box
• Only tracking box
[3] Y. Li, K. He, J. Sun, et al. “R-FCN: Object detection via region-based fully convolutional networks,” NIPS, 2016
[4] H.-U. Kim, D.-Y. Lee, J.-Y. Sim, and C.-S. Kim, “SOWP: Spatially ordered and weighted patch descriptor for visual tracking,” ICCV, 2015.](https://image.slidesharecdn.com/naver-171102015242/85/Video-Object-Segmentation-in-Videos-30-320.jpg)






![Experimental Results
• YouTube-Objects dataset
• Contain 126 videos for 10 object classes
• Performance measure
• Intersection over union (IoU)
[34] Y.-H. Tsai, G. Zhong, and M.-H. Yang, “Semantic cosegmentation in videos.,” ECCV,2016.
[42] Y. Zhang, X. Chen, J. Li, C. Wang, and C. Xia, “Semantic object segmentation via detection in weakly labeled video,” CVPR 2015.](https://image.slidesharecdn.com/naver-171102015242/85/Video-Object-Segmentation-in-Videos-37-320.jpg)


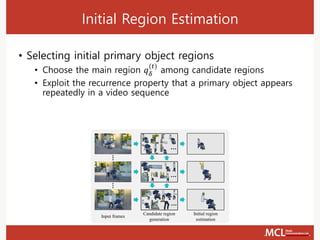
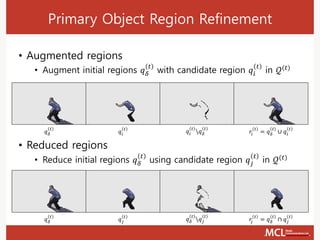
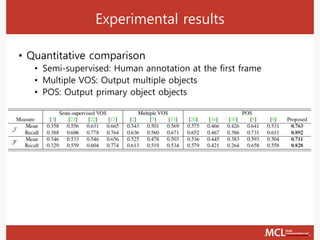
The document discusses video object segmentation techniques, including semi-supervised and primary object segmentation methods. It outlines a process for candidate region generation, initial region estimation, and region refinement using augmentation and reduction processes. Additionally, it explores multiple object segmentation and integrates detection and tracking for improved segmentation outcomes.




































![[142] 생체 이해에 기반한 로봇 – 고성능 로봇에게 인간의 유연함과 안전성 부여하기](https://cdn.slidesharecdn.com/ss_thumbnails/142-171016082840-thumbnail.jpg?width=640&height=640&fit=bounds)



![[132]웨일 브라우저 1년 그리고 미래](https://cdn.slidesharecdn.com/ss_thumbnails/321-171016021602-thumbnail.jpg?width=640&height=640&fit=bounds)





![[2017 PYCON 튜토리얼]OpenAI Gym을 이용한 강화학습 에이전트 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/random-170816031315-thumbnail.jpg?width=640&height=640&fit=bounds)
























































