Reinforcement Learning:
상호 작용을통해 목표를 달성하는 방법을 배우는 문제
learner, decision maker
everything outside the agent
Policy 𝝅𝒕 𝒂 𝒔 : 𝑺 → ℝ ∈ [𝟎, 𝟏]
4.
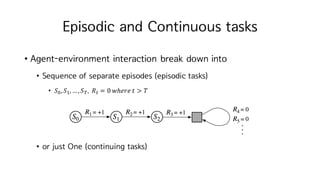
Episodic and Continuoustasks
• Agent-environment interaction break down into
• Sequence of separate episodes (episodic tasks)
• 𝑆H, 𝑆I,…, 𝑆K. 𝑅M = 0 𝑤ℎ𝑒𝑟𝑒 𝑡 > 𝑇
• or just One (continuing tasks)
5.
Value functions, V𝑠
• Estimate how good it is for the agent to be in a given state
• 𝑽: 𝑺 → ℝ
• “how good” is defined in terms of future rewards that can be expected
• 미래의 reward는 어떤 action을취할지에 따라 달라진다 (𝜋)
• Vc
𝑠 = 𝔼c
𝑹 𝒕 𝑆M = 𝑠 = 𝔼c ∑ 𝛾h
𝑟MihiI
KjM
hkH 𝑆M = 𝑠
• where Rl is the total return and 𝑟l is a immediate reward
Action-value functions, Q𝑠, 𝑎
• The value of taking action 𝒂 in state 𝑠 under a policy 𝜋
• 𝑄: 𝑠 → 𝑎|𝜋
• how good it is for the agent to be in taking action 𝑎 in state 𝑠 under a policy 𝜋
• 𝑄c
𝑠, 𝑎 = 𝔼c
𝐺M 𝑆M = 𝑠, 𝐴M = 𝑎 = 𝔼c ∑ 𝛾h
𝑟MihiI
KjM
hkH 𝑆M = 𝑠, 𝐴M = 𝑎
• Optimal action-value function : 𝑉∗
𝑠 = max
o∈p(w)
𝑄∗
(𝑠, 𝑎)
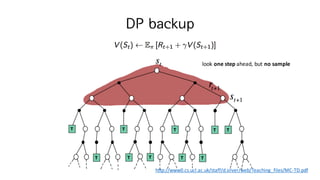
8.
Optimal Value Functions
•Solving RL = finding an optimal policy
• 𝜋가 𝜋 `보다 낫다고 말할 수 있는 건 오직 𝜋의 expected return이 𝜋`보다 클 때
• 𝑉c 𝑠 ≥ 𝑉c`(𝑠)
• 𝑉∗
𝑠 = max
c
𝑉c
𝑠
• 𝑄∗
𝑠, 𝑎 = 𝑚𝑎𝑥c 𝑄c
(𝑠, 𝑎) : the expected return for taking action a in state s
• Express 𝑄∗
in terms of 𝑉∗
𝑸∗
𝑠, 𝑎 = 𝔼 ∑ 𝛾h
𝑟MihiI
KjM
hkH 𝑆M = 𝑠, 𝐴M = 𝑎
= 𝔼 𝑟MiI + 𝛾 ∑ 𝛾hKjM
hkH 𝑟Mihit 𝑆M = 𝑠, 𝐴M = 𝑎
= 𝔼 𝑟MiI + 𝛾 𝑽∗
(𝑠MiI)|𝑆M = 𝑠, 𝐴M = 𝑎
= 𝔼[𝑟MiI + 𝛾 max
o`
𝑄 𝑠MiI, 𝑎` |𝑆M = 𝑠, 𝐴M = 𝑎]
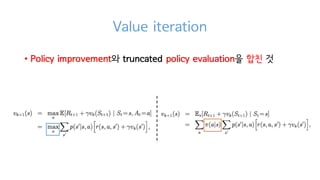
Policy improvement
• Policyevaluation 을 했던건 더 좋은 policy를 찾기 위함
• Policy evaluation으로 Arbitrary 𝜋로 부터 Vc
𝑆 를 계산
• 이제 𝑆 에서 현재 policy 𝝅 를 따르면 얼마나 좋은지 Vc
𝑆 알고 있음
• 그럼 더 좋은 policy 𝝅`를 찾으려면?
• 새로운 𝜋`를 𝜋` = 𝑔𝑟𝑒𝑒𝑑𝑦(𝑉c) 로 구할 수 있음
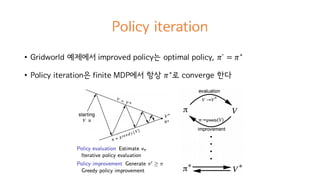
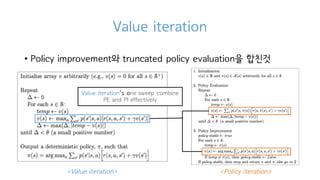
Value iteration
• Policyiteration의 단점
• 𝑉c
를 업데이트하는 Policy evaluation가 converge 할 때까지 기다려야함
• 하지만 Gridworld 예제에서도 봤듯이 굳이
converge 할 때 까지 기다릴 필요는 없음
• 이렇게 해서 나온게 Value iteration
Value iteration
• Policyimprovement와 truncated policy evaluation을 합친것
<Policy iteration><Value iteration>
Value iteration's one sweep combine
PE and PI effectively
32.
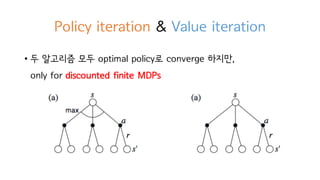
Policy iteration &Value iteration
• 두 알고리즘 모두 optimal policy로 converge 하지만,
only for discounted finite MDPs
33.
Asynchronous Dynamic Programming
•DP의 단점 : MDP의 모오든 state에 대해 계산해야 하며,
각 계산마다 여러번(converge 할 때까지 기다리는)의 iteration 필요
• State가 엄청나게 많으면, 하나의 sweep또 엄청 expensive
• Asynchronous DP algorithm
• back up values of state in any order
• in-place dynamic programming
• prioritized sweeping
• real-time dynamic programming
34.
In-Place Dynamic Programming
•Synchronous value iteration : 두개의 value function을 유지
𝑉’“” 𝑠 ← max
o∈p
𝑟 𝑠, 𝑎, 𝑠` + 𝛾 ‚ 𝑝 𝑠` 𝑠, 𝑎 𝑉–—˜(𝑠`)
w`∈™
𝑉–—˜ ← 𝑉’“”
• Asynchronous (In-place) value iteration : 오직 하나의 value function을 유지
𝑉 𝑠 ← max
o∈p
𝑟 𝑠, 𝑎, 𝑠` + 𝛾 ‚ 𝑝 𝑠` 𝑠, 𝑎 𝑉(𝑠`)
w`∈™
35.
Real-Time Dynamic Programming
•실제로 agent와 관련있는 state만 업데이트
• Agent의 experience를 state 선택시에 가이드로 사용
• 매 time-step의 Sl, 𝐴M, 𝑅MiI마다
𝑉 𝑠M ← max
o∈p
𝑟 𝑠M, 𝑎, 𝑠` + 𝛾 ‚ 𝑝 𝑠` 𝑠M, 𝑎 𝑉(𝑠`)
w`∈™
Definition
•prediction problem (policyevaluation) :
given 𝜋 에 대한 value function 𝑽 𝝅(𝒔)를 계산하는 것
•control problem (policy improvement):
optimal policy 𝝅∗
를 찾는 것
42.
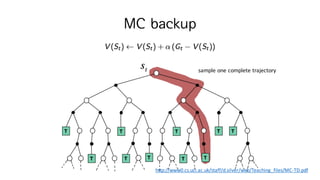
Monte-Carlo Reinforcement Learning
•Return : total discounted reward
GM = 𝑅MiI + 𝛾𝑅Mit + ⋯+ 𝛾KiMjI
𝑅K
• Value function : expected return ≠ reward
𝑉c 𝑠 = 𝔼 𝐺M|𝑆M = 𝑠
• MC policy evaluation은 expected return 𝑉c 𝑠 를
empirical mean return GM로 계산하겠다는 것이 핵심 아이디어
First-Visit MC PolicyEvaluation
Episode 마다 반복 with 𝜋
즉, 하나의 episode에서s를 처음 방문 했을때만 업데이트
한 episode에서 여러번 N(s)가 증가할 수 없음
V(s), N(s), S(s)를 저장하고 있어야함
45.
Every-Visit MC PolicyEvaluation
Episode 마다 반복 with 𝜋
한 episode에서 여러번 N(s)가 증가할 수 있음
V(s), N(s), S(s)를 저장하고 있어야함
46.
Back to basic: Incremental Mean
𝑄hiI =
I
h
∑ 𝑅œ
h
œkI
=
I
h
𝑅h + ∑ 𝑅œ
hjI
œkI =
I
h
𝑅h + (𝑘 − 1 𝑄h + 𝑄h − 𝑄h)
=
I
h
𝑅h + 𝑘𝑄h − 𝑄h = 𝑄h +
I
h
𝑅h − 𝑄h
• Only need memory for k and 𝑄h
• General form:
𝑁𝑒𝑤𝐸𝑠𝑡𝑖𝑚𝑎𝑡𝑒 ← 𝑂𝑙𝑑𝐸𝑠𝑡𝑖𝑚𝑎𝑡𝑒 + 𝑆𝑡𝑒𝑝𝑆𝑖𝑧𝑒 𝑇𝑎𝑟𝑔𝑒𝑡 − 𝑂𝑙𝑑𝐸𝑠𝑡𝑖𝑚𝑎𝑡𝑒
𝑒𝑟𝑟𝑜𝑟 = 𝑇𝑒𝑚𝑝𝑜𝑟𝑎𝑙 𝐷𝑖𝑓𝑓𝑒𝑟𝑒𝑛𝑐𝑒
47.
Incremental Monte-Carlo Updates
•𝑆I, 𝐴I, 𝑅I, … , 𝑆K의 episode를 통해 𝑉(𝑠)를 업데이트 하는 경우
• 각 𝑆M과 𝐺M에 대하여
𝑁 𝑠M ← 𝑁 𝑠M + 1
𝑉 𝑠M ← 𝑉 𝑠M +
1
𝑁 𝑠M
(𝐺M − 𝑉 𝑠M )
• non-stationary 문제에서 fixed constant 𝜶를 사용해 old episodes를 잊을 수
있음
𝑉 𝑠M ← 𝑉 𝑠M + 𝜶(𝐺M − 𝑉 𝑠M )
𝑒𝑟𝑟𝑜𝑟
환경이 시간에 따라 변하는 경우
ex) 벽돌을 하나 깼을때, 벽돌을 30개 깼을때 (굳이 한개 깼을때를 기억할 필요는 없음)
계산된 𝑒𝑟𝑟𝑜𝑟의방향으로 얼마나 이동시킬지
V(s), N(s)만 필요. S(s)는 필요 없음
48.
MC의 장점
• 𝑉c𝑠 는 각 state에 independent 하다
• DP : 𝑉hiI 𝑠 = ∑ 𝜋 𝑎 𝑠 ∑ 𝑝 𝑠` 𝑠, 𝑎 [𝑟(𝑠, 𝑎, 𝑠`) + 𝛾𝑉h 𝑠` ]w`o
• MC : 𝑉 𝑠M ← 𝑉 𝑠M +
I
h
(𝐺M − 𝑉 𝑠M )
• MC do not “bootstrap”
• Computation independent of size of states 𝑆
• 만약 전체 state가 아닌 특정 state 𝑠 ∈ 𝑆̅ ⊆ 𝑆의 𝑉c 𝑠 만 구해도 된다
• DP보다 계산 덜 필요
DP
1. all actions
2. only one transition
MC
1. sampled
2. to the end
49.
MC의 단점
• 모든State s를 방문하지 않았는데, 계산된 V(s)가 미래에 방문할 𝑠를
커버하는지 어떻게 guarantee 할 수 있는가? 없다
• 하지만, 어짜피 주어진 𝜋로 계속해서 방문하기 때문에 모든 s ∈ 𝑆 는 방문하지
못하더라도 주어진 𝜋가 방문하는 𝑆̅, 즉 𝑠 ∈ 𝑆̅ ⊆ 𝑆 한 𝑆 의 subset 𝑆̅는 대부분
방문하므로 괜찮
50.
요약
• MC methods는
•episode를 겪으면서 직접 배운다
• Model-free: MDP transition와 reward를 몰라도 된다
• complete episode로 부터 배운다: no bootstrapping, 진짜 complete Return
• 핵심 아이디어 : 𝑽 𝝅
𝒔 = 평균 Return
• 하지만:
• episodic MDP에서만 쓸 수 있음. episode가 끝나지(terminate) 않으면 MC 못씀!
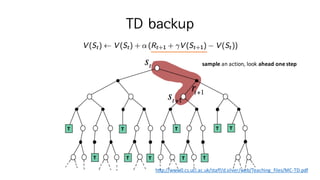
Temporal-Difference (TD) Learning
•TD methods
• 실제 experience로 부터 배운다 (no use of experience memory)
• Model free: MDP trainsition / rewards 정보가 필요 없다
• DP처럼 estimate의 부분만을 보고 (terminal 까지 가보지 않고) 배워 간다
• MC랑 달리 bootstraping 하면서 업데이트 한다
• Guess로 부터 Guess를 업데이트 한다 (핵심 아이디어)
54.
Temporal-Difference (TD) Learning
•목표 : 𝑽 𝝅
𝒔 를 실제 experience로 부터 online으로 배움
• Incremental every-visit MC
• 𝑉 𝑠M 를 실제 return인 𝑮𝒕를 향해 업데이트 한다
• 𝑉 𝑠M ← 𝑉 𝑠M + 𝜶(𝑮𝒕 − 𝑉 𝑠M )
• Simplest temporal-differnce learning algorithm: TD(0)
• 𝑉 𝑠M 를 예측한 return인 RMiI + 𝛾𝑉 𝑠M = immediate reward +
discounted value of next step
• 𝑉 𝑠M ← 𝑉 𝑠M + 𝜶(𝑹 𝒕i𝟏 + 𝜸𝑽(𝒔 𝒕i𝟏) − 𝑉 𝑠M )
TD target
TD error
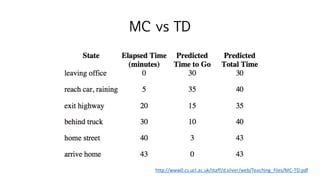
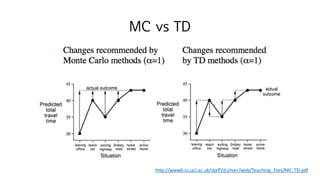
MC vs TD
•자동차 운전의 예시
• MC의 경우
• 자동차가 사고가 나기 직전에 피했다. 𝑮𝒕 = 𝟎
• 그때까지의 trajectory 𝒔 𝒕, 𝒔 𝒕j𝟏,… , 𝒔 𝟎들은 사고가 날 수 있었던 위험한 상황에 대한
negative reward를 받지 못하고 업데이트가 안된다
• 실제로 사고가 난 경우에만 negative 한 상황을 피하도록 배울 수 있다
• TD의 경우
• 자동차가 사고가 나기 직전이라고 판단이 되었을 때. 𝑽 𝒔 𝒕i𝟏 = −𝟏
• 그 직전의 trajectory 𝒔 𝒕는 negative reward로 업데이트 할 수 있다
• 실제로 사고가 나지 않은 경우에도 negative 한 상황을 피하도록 배울 수 있다
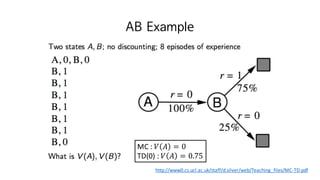
MC vs TD(1)
• TD는 마지막 return을 보기 전에 배울 수 있다
• 매 step 마다 online으로 배운다
• MC는 episode의 마지막까지 기다려 𝑮 𝒕를 알아야 한다
• TD는 마지막 return이 없이도 배울 수 있다
• TD는 episode가 완전하지 않아도 (끝나지 않아도, 끝나지 않았어도) 배운다
• MC는 episode가 완전해야 배운다
• MC는 episodic (terminating) environments에서만 쓸 수 있다
• TD는 continuing (non-terminating) environments에서도 쓸 수 있다
60.
Bias/Variance Trade-off
• Return: 𝐺M = 𝑅MiI + 𝛾𝑅Mit + ⋯ + 𝛾KjI
𝑅K. unbiased prediction of 𝑽 𝝅
𝒔 𝒕
• True TD target : RMiI + 𝛾𝑉c
𝑠MiI . unbiased prediction of 𝑽 𝝅
(𝒔 𝒕)
• TD target : 𝑅MiI + 𝛾𝑉h
𝑠MiI . biased estimate of 𝑽 𝝅
(𝒔 𝒕)
• 𝑉h
는 현재 우리의 불완전한 지식 (bias) 을 나타낸다
• 하지만 TD target은 Return 보다 훨씬 작은 variance를 가진다
• Return은많은 random action, transitions, reward에 의존하며 episode가 길어질수록
variance가 커진다
• TD target은 오직 하나의 random action, transition, reward에 의해 결정된다
bias는 이 두 값의 차이때문에 발생
61.
MC vs TD(2)
• MC : high variance, zero bias
• Good convergence property (even with function approximation)
• 초기 값에 sensitive하지 않다. 이유는 초기 값으로 부터 bootstrap하지 않기 때문
• TD : low variance, some bias
• 보통 MC보다 훨씬 efficient하다
• TD(0)는 𝑉c
𝑠M 로 converge한다.
• 하지만 function approximation로는 항상 converge하지 않는다 (하지만 specific한 case)
• 초기값에 훨씬 sensitive하다
Certainty Equivalence
먼저 data에맞는 MDP를 만들고
그 MDP에 maximum likelihood한 답을 찾음
count of transition
mean rewards, divided by number of visit
only observe last return
68.
MC & TD(3)
• TD는 Markov property 를 타겟으로 한다
• TD는 MDP를 만들어 나가면서 (Environment를 state에 대해 이해) 문제를
푼다
• 보통 Markov environment에서 훨씬 효과적이다
• MC는 Markov property를 타겟으로 하지 않는다
• 보통 non-Markov environment에서 훨씬 효과적이다
• ex) partially observable MDP
Bootstrapping & Sampling
•Bootstrapping : don’t use real return
• MC does not bootstrap
• DP bootstrap : use estimate as a target
• TD bootstrap
• Sampling
• MC samples
• DP does not samples
• TD samples
http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching_files/MC-TD.pdf
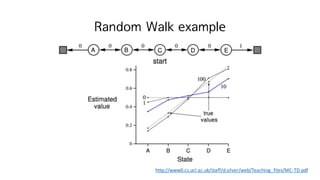
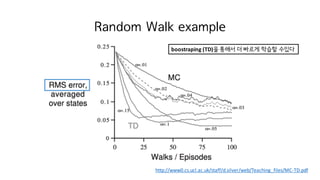
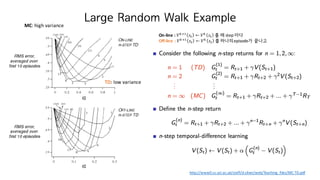
Large Random WalkExample
http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching_files/MC-TD.pdf
MC: high variance
TD: low variance
On-line : 𝑉hiI
𝑠M ← 𝑉h
𝑠M 를 매 step 마다
Off-line : 𝑉hiI
𝑠M ← 𝑉h
𝑠M 를 하나의episode가 끝나고
75.
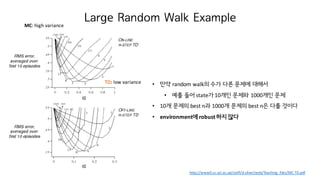
Large Random WalkExample
http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching_files/MC-TD.pdf
MC: high variance
TD: low variance • 만약 random walk의 수가 다른 문제에 대해서
• 예를 들어 state가 10개인 문제와 1000개인 문제
• 10개 문제의 best n과 1000개 문제의 best n은 다를 것이다
• environment에 robust 하지 않다
76.
Averaging n-step Returns
•𝐺M
(’)
= 𝑟MiI + 𝛾𝑟Mit + ⋯+ 𝛾’jI
𝑟Mi’ + 𝛾’
𝑉(𝑠Mi’)
• 1-step 한 것과 2-step 뿐만 아니라 n-step 에서도 잘 하고 싶다면?
• 𝐺M
(t,²)
=
I
t
𝐺M
(t)
+
I
t
𝐺M
(²)
• 더 효율적으로 계산할 수 없을까?
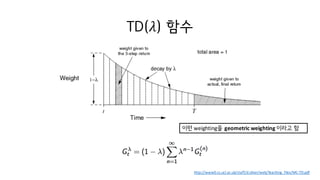
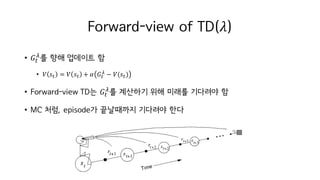
Forward-view of TD(𝜆)
•𝐺M
µ
를 향해 업데이트 함
• 𝑉 𝑠M = 𝑉 𝑠M + 𝛼 𝐺M
µ − 𝑉(𝑠M)
• Forward-view TD는 𝐺M
µ
를 계산하기 위해 미래를 기다려야 함
• MC 처럼, episode가 끝날때까지 기다려야 한다
80.
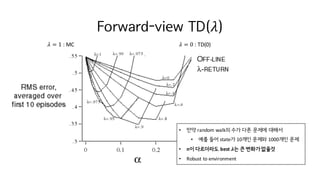
Forward-view TD(𝜆)
𝜆 =1 : MC 𝜆 = 0 : TD(0)
• 만약 random walk의 수가 다른 문제에 대해서
• 예를 들어 state가 10개인 문제와 1000개인 문제
• n이 다르더라도 best 𝝀는 큰 변화가 없을것
• Robust to environment
81.
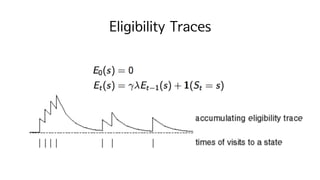
Backward-view TD(𝜆)
• Updateonline, every step, from incomplete sequences 의 장점을 유지
• “종”이 감전을 일으켰을까? 아니면 “빛”이 감전을 일으켰을까?
• Frequency heuristic : 가장 자주 발생했던 state에 importance를
• Recency heuristic : 가장 최근에 발생한 state에 importance를
• Eligibility trace : 두 개의 heuristic을 합친 것




![Reinforcement Learning:
상호 작용을 통해 목표를 달성하는 방법을 배우는 문제
learner, decision maker
everything outside the agent
Policy 𝝅𝒕 𝒂 𝒔 : 𝑺 → ℝ ∈ [𝟎, 𝟏]](https://image.slidesharecdn.com/4-160714190818/85/Reinforcement-Learning-an-introduction-3-320.jpg)


![Optimal Value Functions
• Solving RL = finding an optimal policy
• 𝜋가 𝜋 `보다 낫다고 말할 수 있는 건 오직 𝜋의 expected return이 𝜋`보다 클 때
• 𝑉c 𝑠 ≥ 𝑉c`(𝑠)
• 𝑉∗
𝑠 = max
c
𝑉c
𝑠
• 𝑄∗
𝑠, 𝑎 = 𝑚𝑎𝑥c 𝑄c
(𝑠, 𝑎) : the expected return for taking action a in state s
• Express 𝑄∗
in terms of 𝑉∗
𝑸∗
𝑠, 𝑎 = 𝔼 ∑ 𝛾h
𝑟MihiI
KjM
hkH 𝑆M = 𝑠, 𝐴M = 𝑎
= 𝔼 𝑟MiI + 𝛾 ∑ 𝛾hKjM
hkH 𝑟Mihit 𝑆M = 𝑠, 𝐴M = 𝑎
= 𝔼 𝑟MiI + 𝛾 𝑽∗
(𝑠MiI)|𝑆M = 𝑠, 𝐴M = 𝑎
= 𝔼[𝑟MiI + 𝛾 max
o`
𝑄 𝑠MiI, 𝑎` |𝑆M = 𝑠, 𝐴M = 𝑎]](https://image.slidesharecdn.com/4-160714190818/85/Reinforcement-Learning-an-introduction-8-320.jpg)

![Bellman optimality equation
𝑽∗
𝑠 = max
o
𝔼[𝑅MiI + 𝛾𝑉∗
(𝑠MiI)|𝑆M = 𝑠, 𝐴M = 𝑎]
= max
o
∑ 𝑝 𝑠` 𝑠, 𝑎 [𝑟 𝑠, 𝑎, 𝑠` + 𝛾𝑽∗
(𝑠`)]w`
𝑸∗
𝑠, 𝑎 = 𝔼[𝑅MiI + 𝛾 max
o`
𝑄∗
(𝑠MiI, 𝑎`)|𝑆M = 𝑠, 𝐴M = 𝑎]
= ∑ 𝑝 𝑠` 𝑠, 𝑎 [𝑟 𝑠, 𝑎, 𝑠` + 𝛾 max
o`
𝑸∗
𝑠MiI, 𝑎` ]w`
• For finite MDPs, Bellman optimality equation has a unique solution independent of the policy
• DP are obtained by turning Bellman equations into assignments
into update rules for improving approximations of value functions](https://image.slidesharecdn.com/4-160714190818/85/Reinforcement-Learning-an-introduction-10-320.jpg)


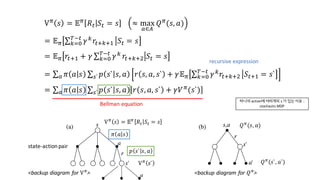
![Policy Evaluation
• How to compute 𝑉c
𝑠 for an arbitrary policy 𝜋? 𝝅 의 value를 계산 하는 방법?
= policy evaluation
𝑉c
𝑠 = 𝔼 𝑟M + 𝛾𝑉c
𝑠` 𝑆M = 𝑠
= ‚ 𝜋 𝑎 𝑠 ‚ 𝑝 𝑠` 𝑠, 𝑎 [𝑟(𝑠, 𝑎, 𝑠`) + 𝛾𝑉c
𝑠` ]
w`o
𝜋에 대한 𝑠의 future reward의 expectation](https://image.slidesharecdn.com/4-160714190818/85/Reinforcement-Learning-an-introduction-13-320.jpg)
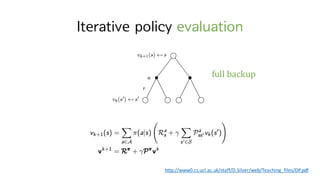
![Policy Evaluation
• 만약 environment의 모든 행동을 알고 있다면 (known MDP)
𝑉c
는 그저 |𝑺|개의 unknown variables (Vc
𝑆 , 𝑠 ∈ 𝑆)로 구성된
|𝑺|개의 linear equations
• 처음엔 arbitrary approximate value function 인 𝑉H로부터 시작. 𝑉H, 𝑉I, 𝑉t,…
𝑉hiI 𝑠 = 𝔼 𝑟M + 𝛾𝑉h 𝑠` 𝑆M = 𝑠
= ‚ 𝜋 𝑎 𝑠 ‚ 𝑝 𝑠` 𝑠, 𝑎 [𝑟(𝑠, 𝑎, 𝑠`) + 𝛾𝑉h 𝑠` ]
w`o
<Iterative policy evaluation>](https://image.slidesharecdn.com/4-160714190818/85/Reinforcement-Learning-an-introduction-14-320.jpg)


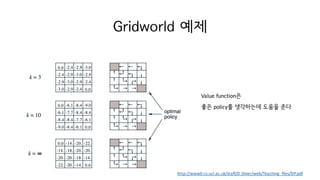

![Policy improvement theorem
• 새로운 policy로 바꾸는 것이 좋을까 나쁠까?
𝑄c 𝑠, 𝑎 = 𝔼c 𝐺M 𝑆M = 𝑠, 𝐴M = 𝑎
= 𝔼c ∑ 𝛾h 𝑟MihiI
KjM
hkH 𝑆M = 𝑠, 𝐴M = 𝑎
= 𝔼c 𝑟MiI + ∑ 𝛾h 𝑟MihiI
KjM
hkI 𝑆M = 𝑠, 𝐴M = 𝑎 = 𝔼c 𝑟MiI + 𝛾𝑉c(𝑠`) 𝑆M = 𝑠, 𝐴M = 𝑎
• 𝑄c 𝑠, 𝜋`(𝑠) 가 𝑉c(𝑠)보다 크다면 𝜋`가 𝜋보다 좋다
𝑄c 𝑠, 𝜋`(𝑠) ≥ 𝑉c 𝑠 for all 𝑠 ∈ 𝑆 이면,
𝑉c` 𝑠 ≥ 𝑉c 𝑠 for all 𝑠 ∈ 𝑆. WHY?
현재 value새로운 𝜋`로 선택한 value
𝑸 𝝅
𝑠, 𝑎 = ‚ 𝑝 𝑠` 𝑠, 𝑎 [𝑟 𝑠, 𝑎, 𝑠` + 𝛾max
o`
𝑸 𝝅
𝑠MiI, 𝑎` ]
w`](https://image.slidesharecdn.com/4-160714190818/85/Reinforcement-Learning-an-introduction-21-320.jpg)




![Greedy policy
𝜋` 𝑠 = argmax
o
𝑞c(𝑠, 𝑎)
= argmax
o
𝔼[𝑅MiI + 𝛾𝑉c
𝑠MiI |𝑆M = 𝑠, 𝐴M = 𝑎]
= argmax
o
∑ 𝑝 𝑠` 𝑠, 𝑎 [𝑟(𝑠, 𝑎, 𝑠`) + 𝛾𝑉c
𝑠` ]w`
• Greedy policy 는 𝑉c
로부터 𝑡 + 1에서 최고의 value를 보이는 action을 선택
<Policy improvement theorem>](https://image.slidesharecdn.com/4-160714190818/85/Reinforcement-Learning-an-introduction-26-320.jpg)

















![MC의 장점
• 𝑉c 𝑠 는 각 state에 independent 하다
• DP : 𝑉hiI 𝑠 = ∑ 𝜋 𝑎 𝑠 ∑ 𝑝 𝑠` 𝑠, 𝑎 [𝑟(𝑠, 𝑎, 𝑠`) + 𝛾𝑉h 𝑠` ]w`o
• MC : 𝑉 𝑠M ← 𝑉 𝑠M +
I
h
(𝐺M − 𝑉 𝑠M )
• MC do not “bootstrap”
• Computation independent of size of states 𝑆
• 만약 전체 state가 아닌 특정 state 𝑠 ∈ 𝑆̅ ⊆ 𝑆의 𝑉c 𝑠 만 구해도 된다
• DP보다 계산 덜 필요
DP
1. all actions
2. only one transition
MC
1. sampled
2. to the end](https://image.slidesharecdn.com/4-160714190818/85/Reinforcement-Learning-an-introduction-48-320.jpg)



































































![[BIZ+005 스타트업 투자/법률 기초편] 첫 투자를 위한 스타트업 기초상식 | 비즈업 조가연님](https://cdn.slidesharecdn.com/ss_thumbnails/5ckl-170317080235-thumbnail.jpg?width=640&height=640&fit=bounds)




![[한국어] Multiagent Bidirectional- Coordinated Nets for Learning to Play StarCra...](https://cdn.slidesharecdn.com/ss_thumbnails/multiagentbidirectional-coordinatednetsforlearningtoplaystarcraftcombatgames-170623022918-thumbnail.jpg?width=640&height=640&fit=bounds)













![[머가]Chap11 강화학습](https://cdn.slidesharecdn.com/ss_thumbnails/chap11-170923012256-thumbnail.jpg?width=640&height=640&fit=bounds)











![Random Thoughts on Paper Implementations [KAIST 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/kaist2018-180426031539-thumbnail.jpg?width=640&height=640&fit=bounds)





