Download as PDF, PPTX







![Related works
• Object proposal-based algorithm
• Generate object proposals in each frame
• Select object proposals that are similar to the target object
[2015][ICCV][Perazzi] Fully Connected Object Proposals for Video Segmentation
Generated object proposals
Segment track](https://image.slidesharecdn.com/170822-171107015546/85/Online-video-object-segmentation-via-convolutional-trident-network-8-320.jpg)
![Related works
• Superpixel-based algorithm
• Over-segment each frame into superpixels
• Trace the target object based on the inter-frame matching
[2015][CVPR][Wen] Joint Online Tracking and Segmentation
Inter-frame matching Segment track](https://image.slidesharecdn.com/170822-171107015546/85/Online-video-object-segmentation-via-convolutional-trident-network-9-320.jpg)





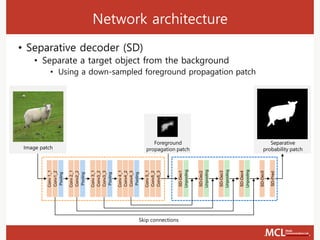

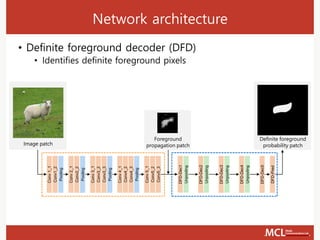
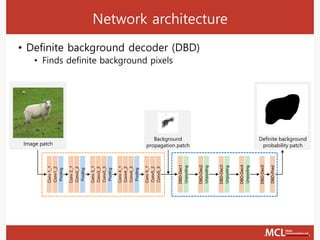
![Network architecture
• Implementation issues in decoders
• Prediction layer
• Sigmoid layer is used to yield normalized outputs within [0, 1]
• Rectified linear unit (ReLU) + Batch normalization
• Kernel size
• 3 ×3 kernels are used in the prediction layers
• 5 × 5 kernels are used in the other convolution layers](https://image.slidesharecdn.com/170822-171107015546/85/Online-video-object-segmentation-via-convolutional-trident-network-23-320.jpg)




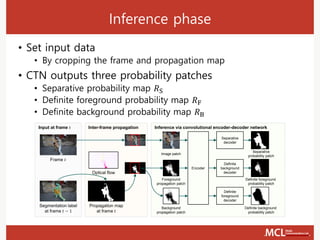


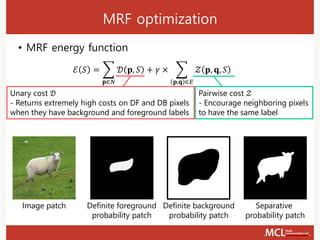






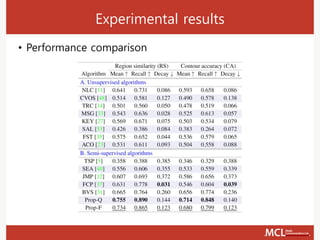

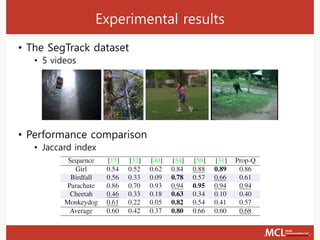
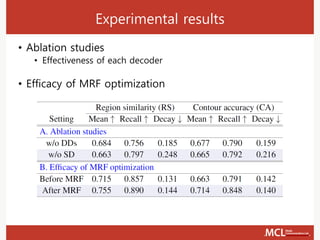
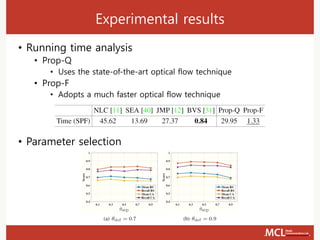


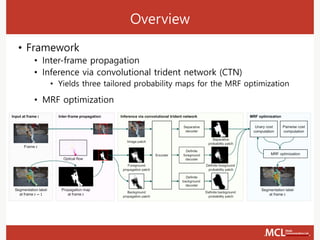
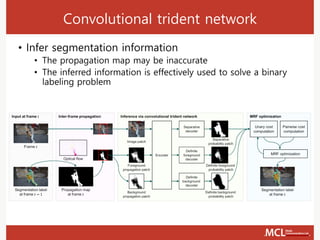
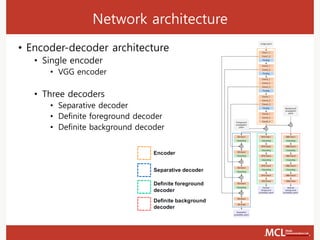
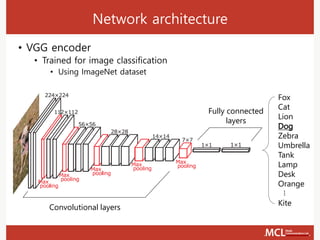
The document presents a semi-supervised online video object segmentation algorithm utilizing a convolutional trident network for effective segmentation of primary objects in videos, with minimal user interaction. It discusses the challenges associated with video object segmentation and outlines the algorithm's architecture, including various decoders and optimization strategies. Through experimental results on multiple datasets, including the Davis benchmark, it demonstrates the algorithm's marked performance enhancements in segmentation accuracy and processing speed.







































![[2017 PYCON 튜토리얼]OpenAI Gym을 이용한 강화학습 에이전트 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/random-170816031315-thumbnail.jpg?width=640&height=640&fit=bounds)





![[132]웨일 브라우저 1년 그리고 미래](https://cdn.slidesharecdn.com/ss_thumbnails/321-171016021602-thumbnail.jpg?width=640&height=640&fit=bounds)
![[142] 생체 이해에 기반한 로봇 – 고성능 로봇에게 인간의 유연함과 안전성 부여하기](https://cdn.slidesharecdn.com/ss_thumbnails/142-171016082840-thumbnail.jpg?width=640&height=640&fit=bounds)



























































