Downloaded 111 times



























![What is sstable2json?
• bin/sstable2json is a utility which exports an SSTable in JSON
format, for testing and debugging
• -k exclude a set of keys specified in HEX format (limit: 500)
• -x exclude a specified set of keys (limit: 500)
• -e enumerate keys only
©2014 DataStax Training. Use only with permission. Slide 22
./sstable2json [full_path_to_SSTable_Data_file] | more](https://image.slidesharecdn.com/intro-to-cassandra-150505152210-conversion-gate02/85/Intro-to-Cassandra-39-320.jpg)

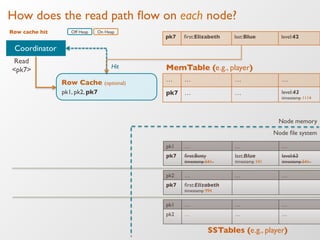
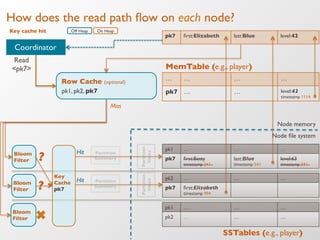
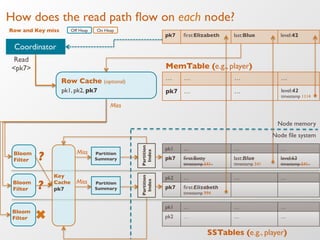
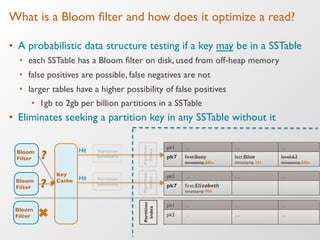
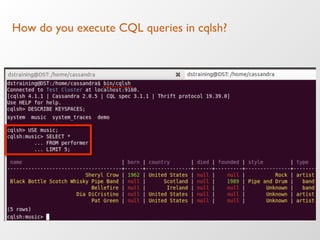




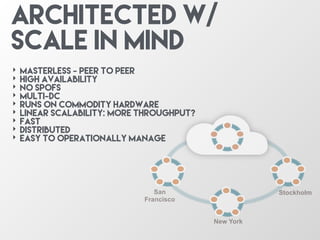
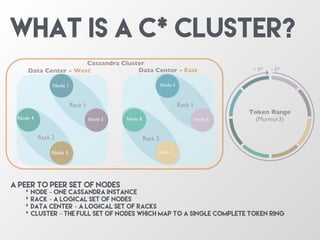
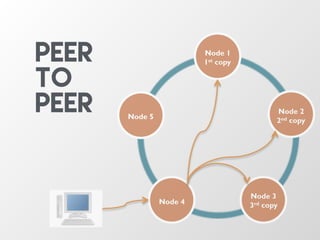
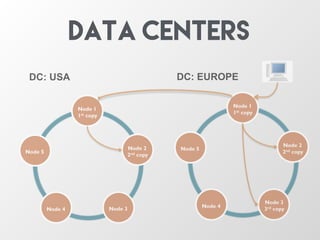
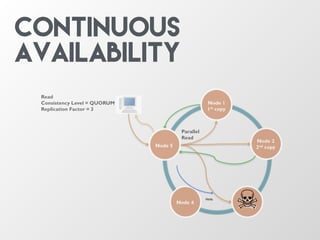
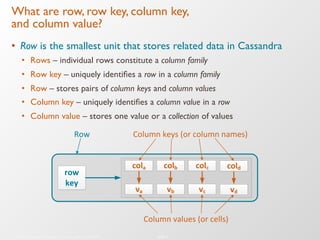
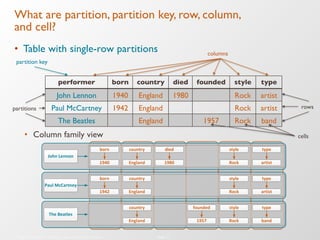
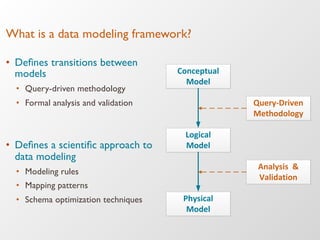
The document discusses the architecture and features of Apache Cassandra, highlighting its masterless, peer-to-peer structure that ensures high availability and linear scalability. It elaborates on data modeling concepts, CQL (Cassandra Query Language), and the mechanisms of writing and reading data efficiently through components like memtables and SSTables. Additionally, it provides insights into query patterns and performance optimization techniques for managing large datasets.




































































































