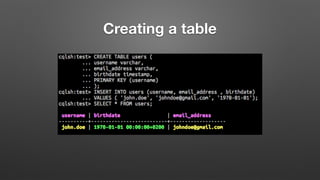
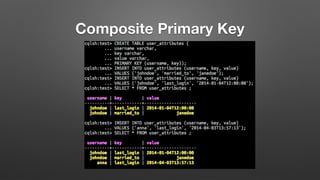
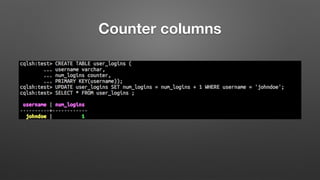
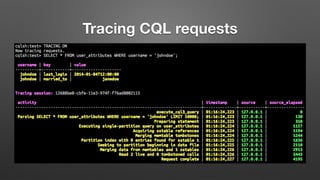
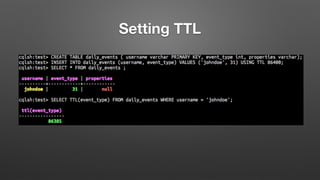
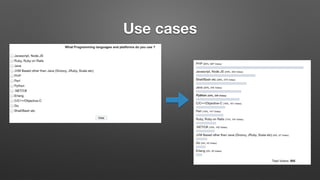
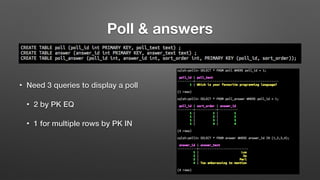
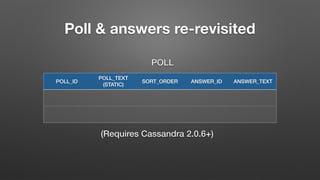
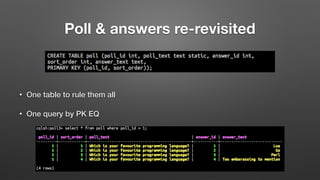
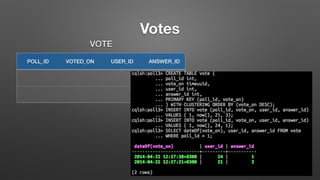
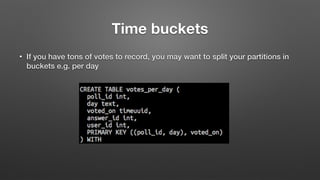
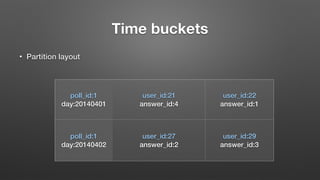
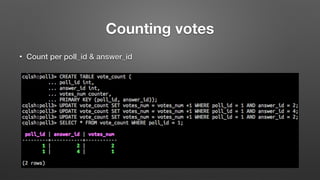
The document outlines key features and operational concepts of Cassandra, a distributed database designed for scalability and high availability. It covers data modeling, including CQL syntax, primary keys, and replication factors, while also discussing use cases like polls and time-series data management. Additionally, it highlights the advantages of Cassandra's masterless design and the nuances of consistency levels and querying, essential for effective database management.









![Masterless design
• All nodes in the cluster are equal
• Gossip protocol among servers
• Adding / removing nodes is easy
• Clients are cluster-aware
Traditional replicated relational database systems focus on the
problem of guaranteeing strong consistency to replicated data.
Although strong consistency provides the application writer a
convenient programming model, these systems are limited in
scalability and availability [7]. These systems are not capable of
A
B
C
DE
F
G
Key K
Nodes B, C
and D store
keys in
range (A,B)
including
K.
Figure 2: Partitioning and replication of keys in Dynamo
ring.
Image from “Dynamo: Amazon’s Highly Available Key-value Store”](https://image.slidesharecdn.com/cassandra-at-iconplatforms-140426141632-phpapp02/85/Cassandra-Basics-Counters-and-Time-Series-Modeling-9-320.jpg)


































































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)








