Downloaded 16 times













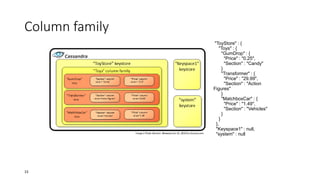


![Column family
• A column family is a container for columns, analogous to the table in
a relational system.
• A Column family holds an ordered list of columns, which is been
refered by the column name.
• [Keyspace][ColumnFamily][Key][Column]
19](https://image.slidesharecdn.com/introductiontocassandra-140302110749-phpapp02/85/Introduction-to-cassandra-19-320.jpg)




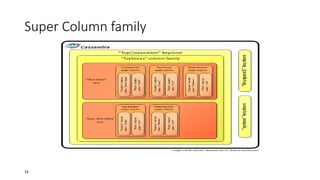
![Super column
• The value of a super column is a map of subcolumns (which store
byte array values).
• it’s important to keep columns that you are likely to query together in
the same column family, and a super column can be helpful for this.
• Super columns are not indexed.
• Cassandra looks like a four-dimensional hash table. But for super
columns, it becomes more like a five-dimensional hash:
[Keyspace][ColumnFamily][Key][SuperColumn][SubColumn]
24](https://image.slidesharecdn.com/introductiontocassandra-140302110749-phpapp02/85/Introduction-to-cassandra-24-320.jpg)








This document provides an introduction to Cassandra, including what it is, how it works, and how to model data in Cassandra. Specifically: - Cassandra is a distributed, decentralized, column-oriented NoSQL database modeled after Amazon Dynamo and Google Bigtable. It is fault-tolerant, scalable, and provides high availability. - Cassandra uses an eventual consistency model and is optimized for availability over strong consistency. It addresses problems with horizontal scaling in relational databases. - Data is modeled using keyspaces, column families, rows, columns, and super columns. Common design patterns include materialized views and storing column names as values.

































































