Download to read offline







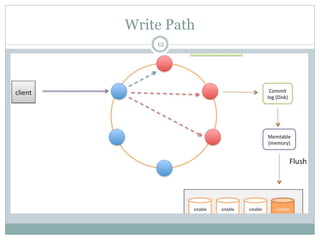
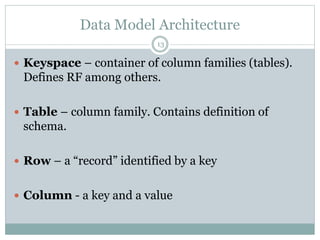
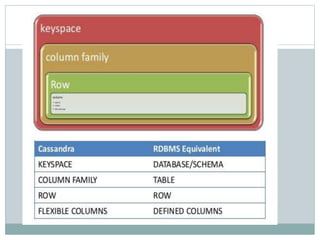







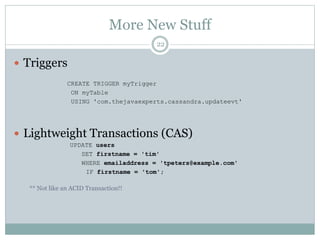

















The document provides an overview and discussion of Cassandra including its architecture, data model, and real world applications. It discusses Cassandra's distributed architecture based on BigTable and Dynamo, as well as key concepts like nodes, clusters, consistency levels, and tunable consistency. The document also covers data modeling techniques in Cassandra like compound primary keys, materialized views, secondary indexes, counters, and using time to live for expiring data. Real world examples are provided for many of these techniques.



















































































