



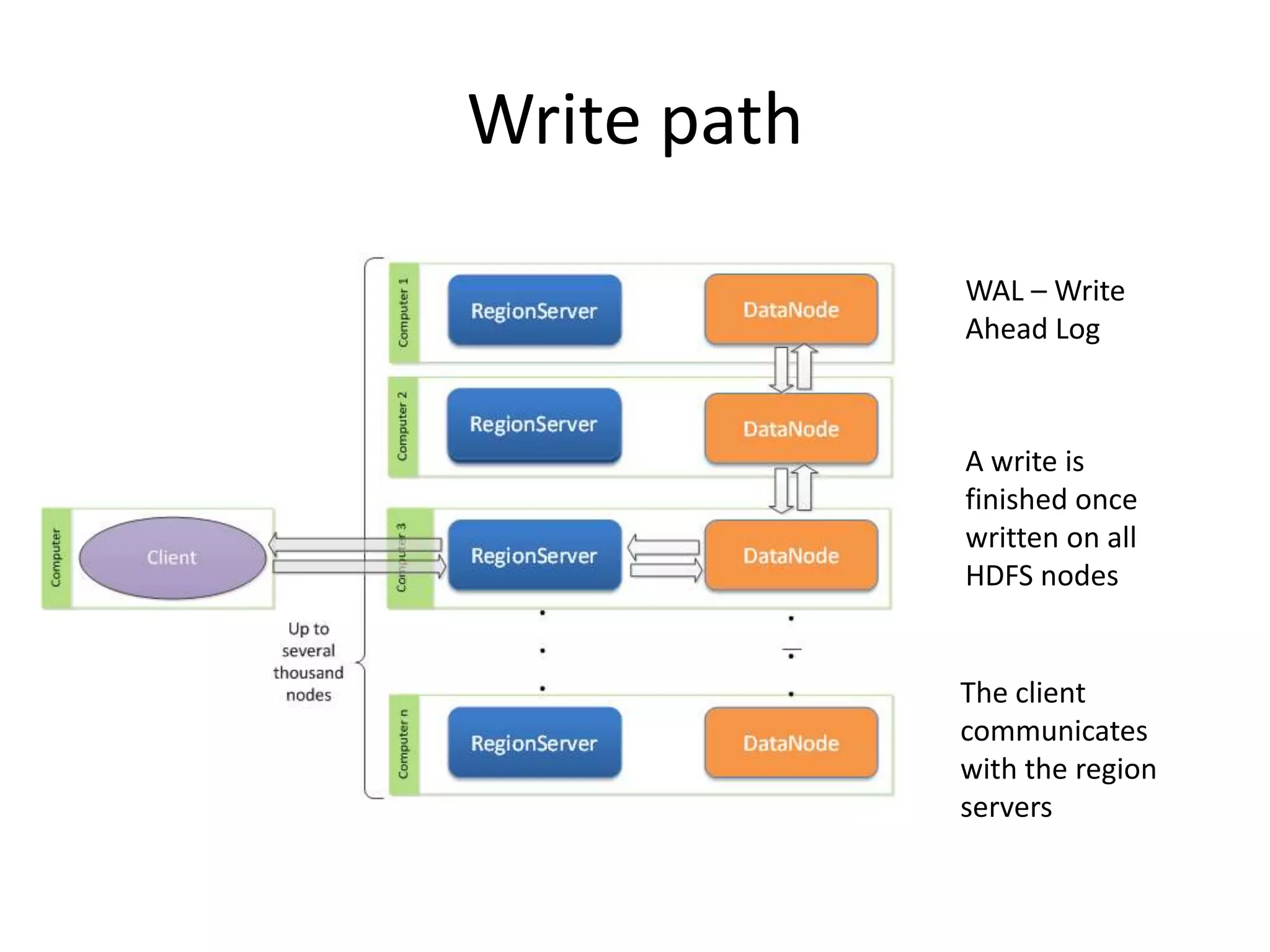

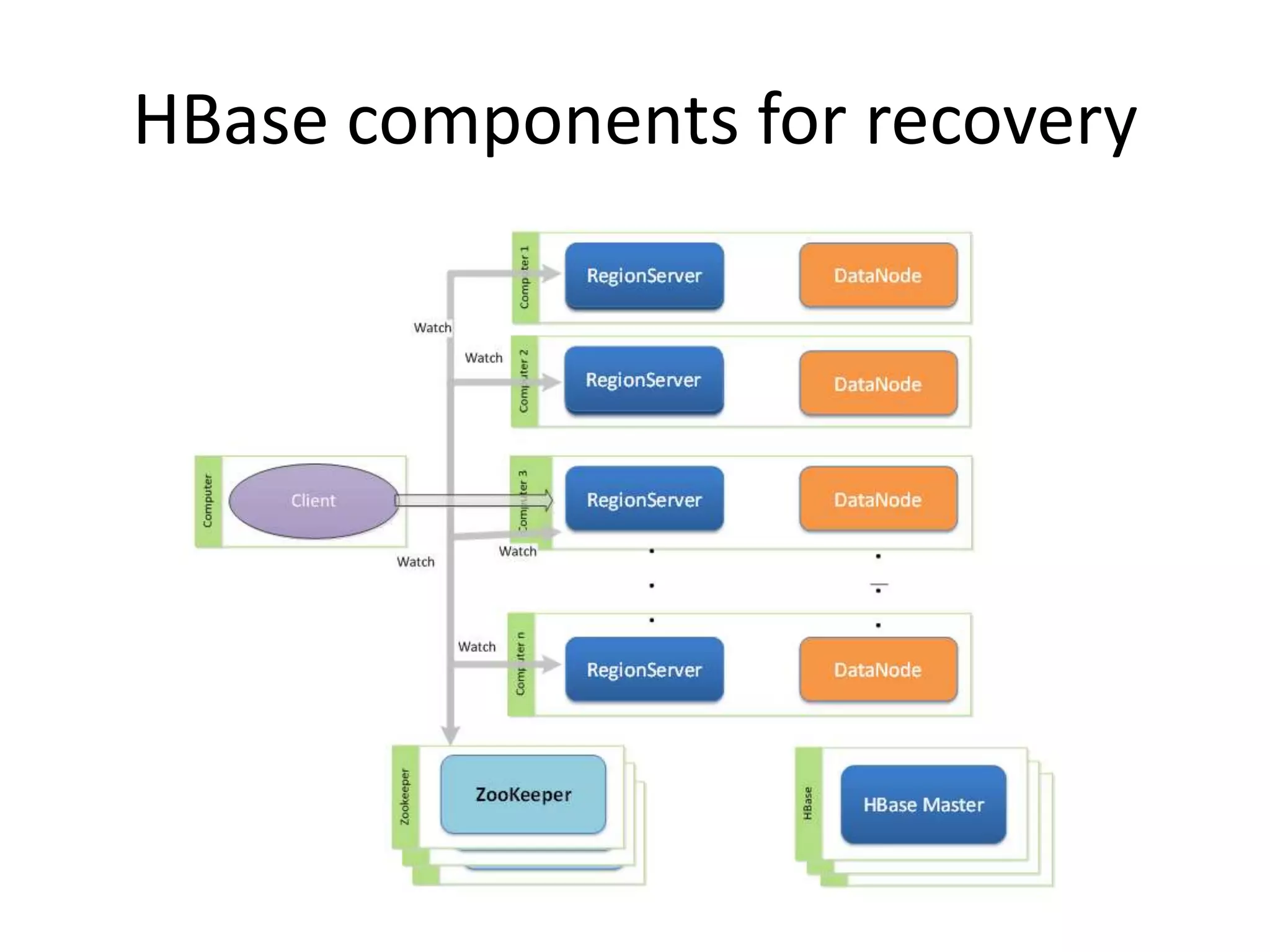
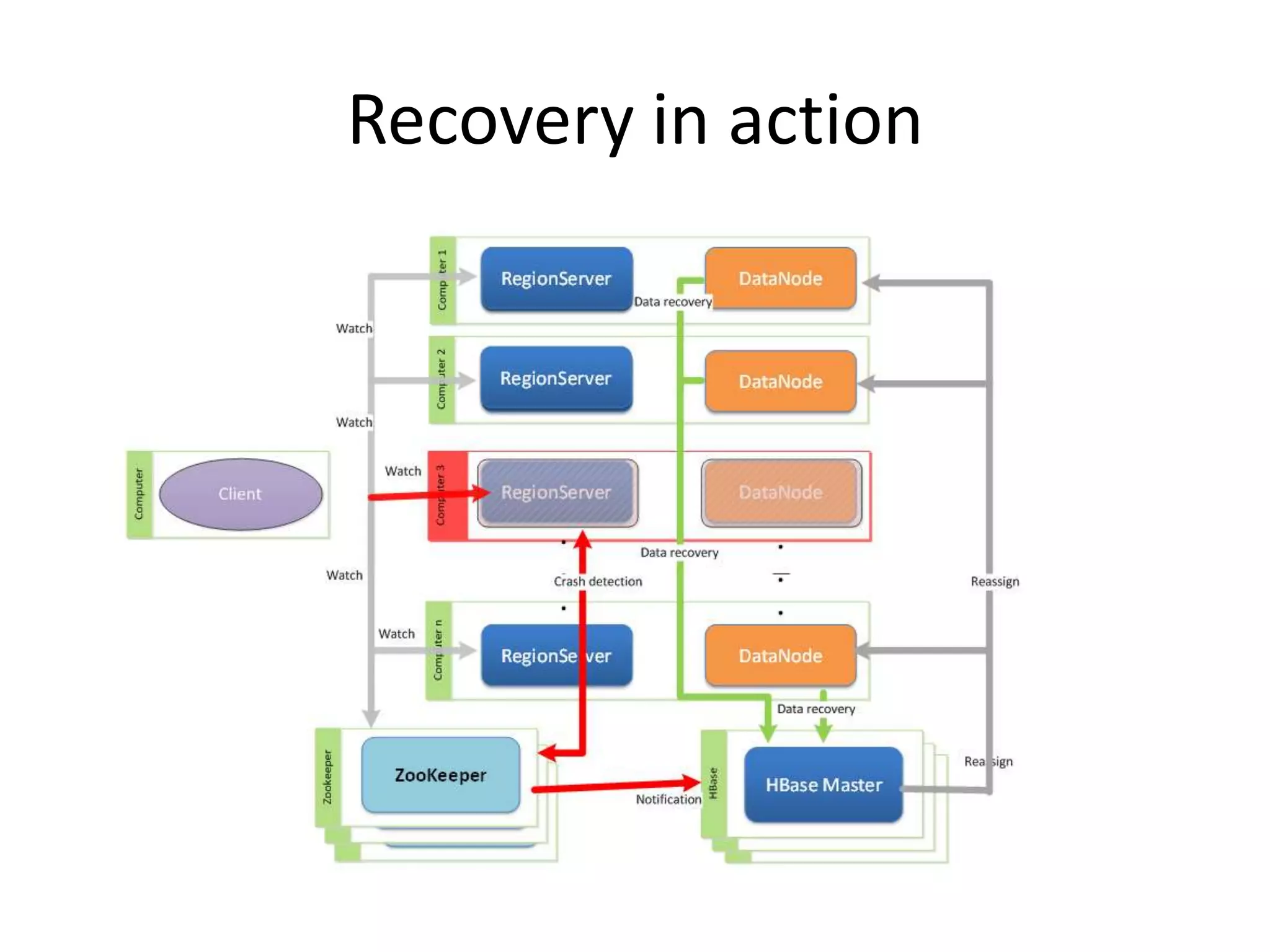
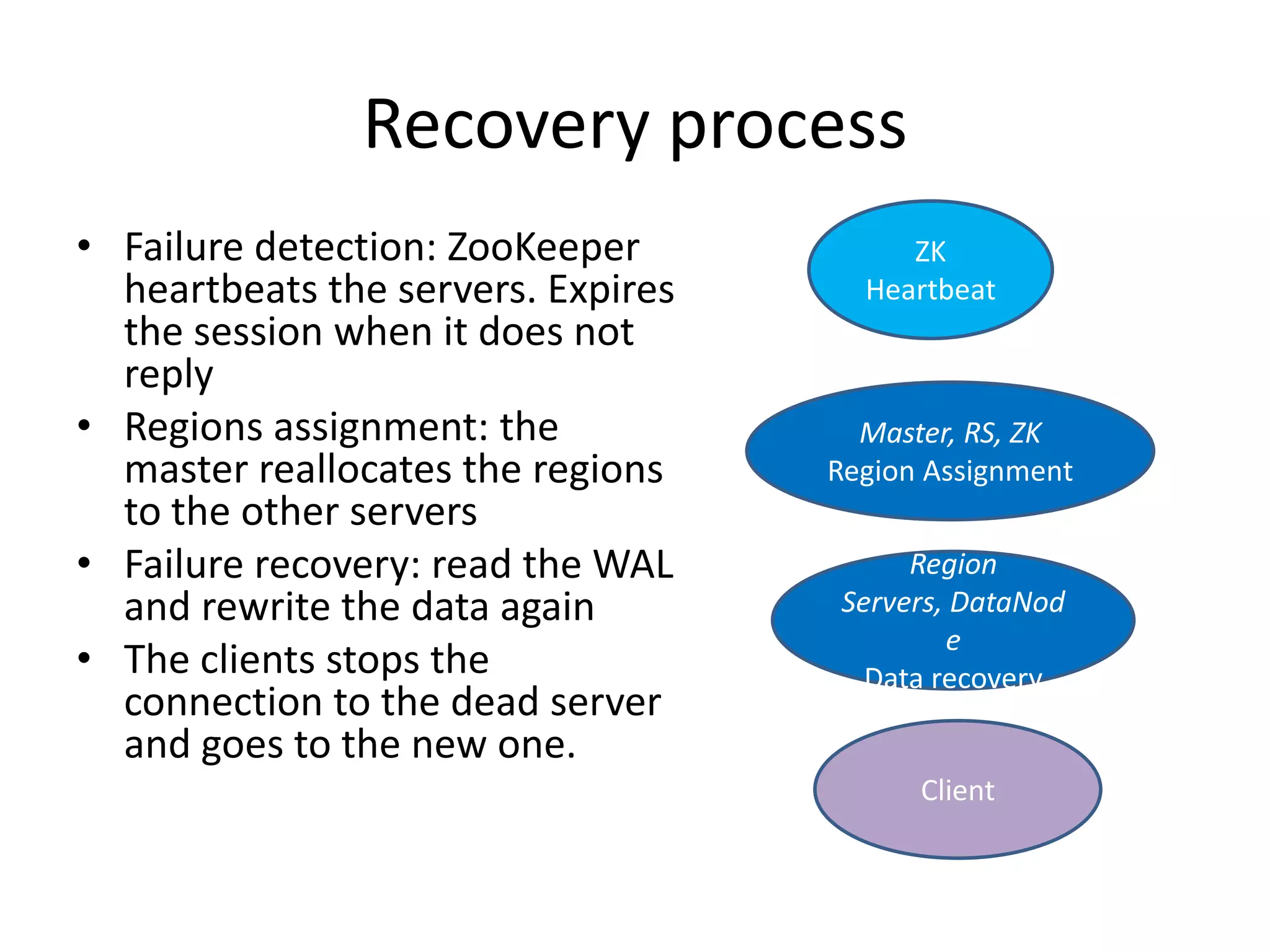







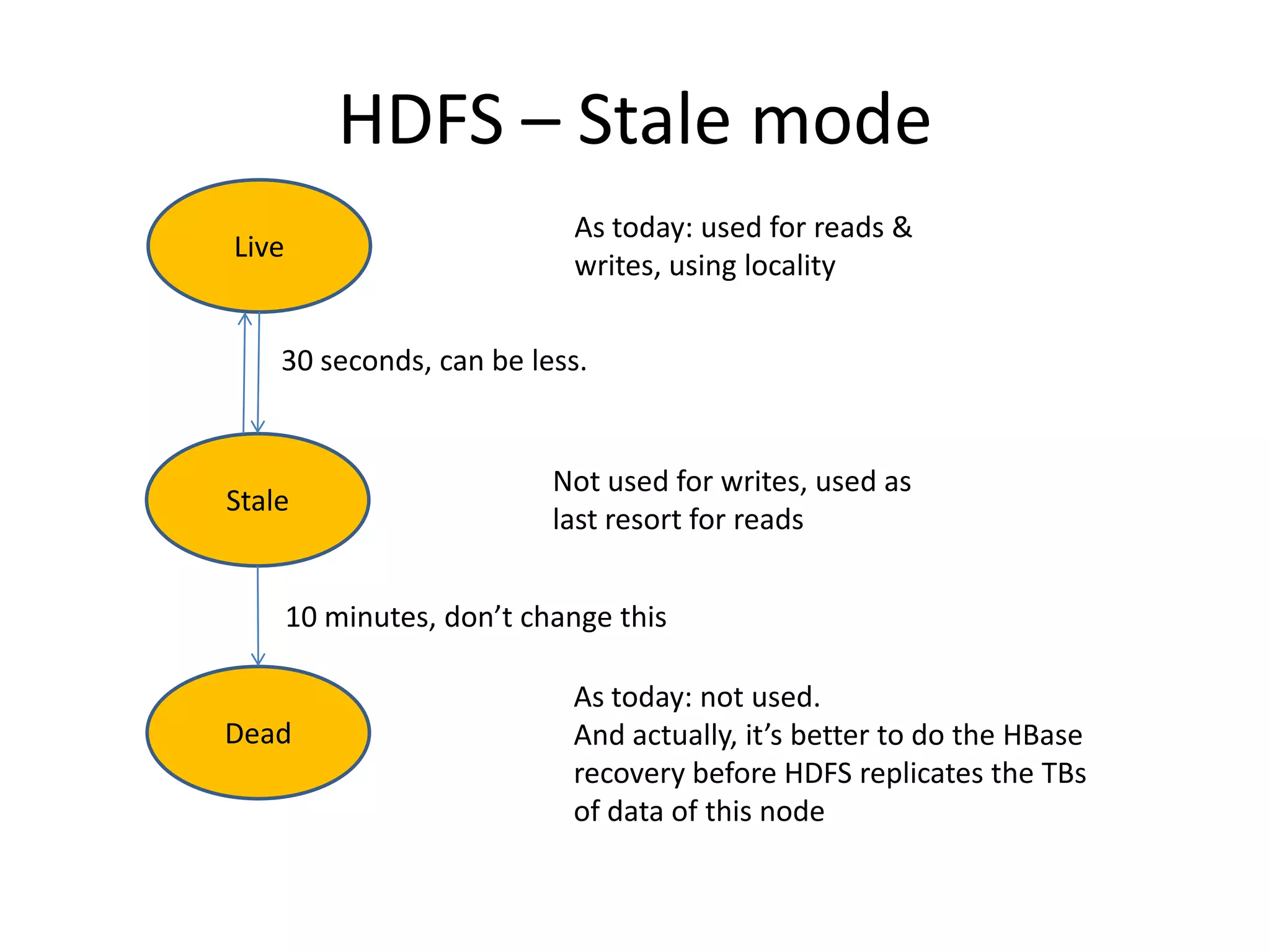



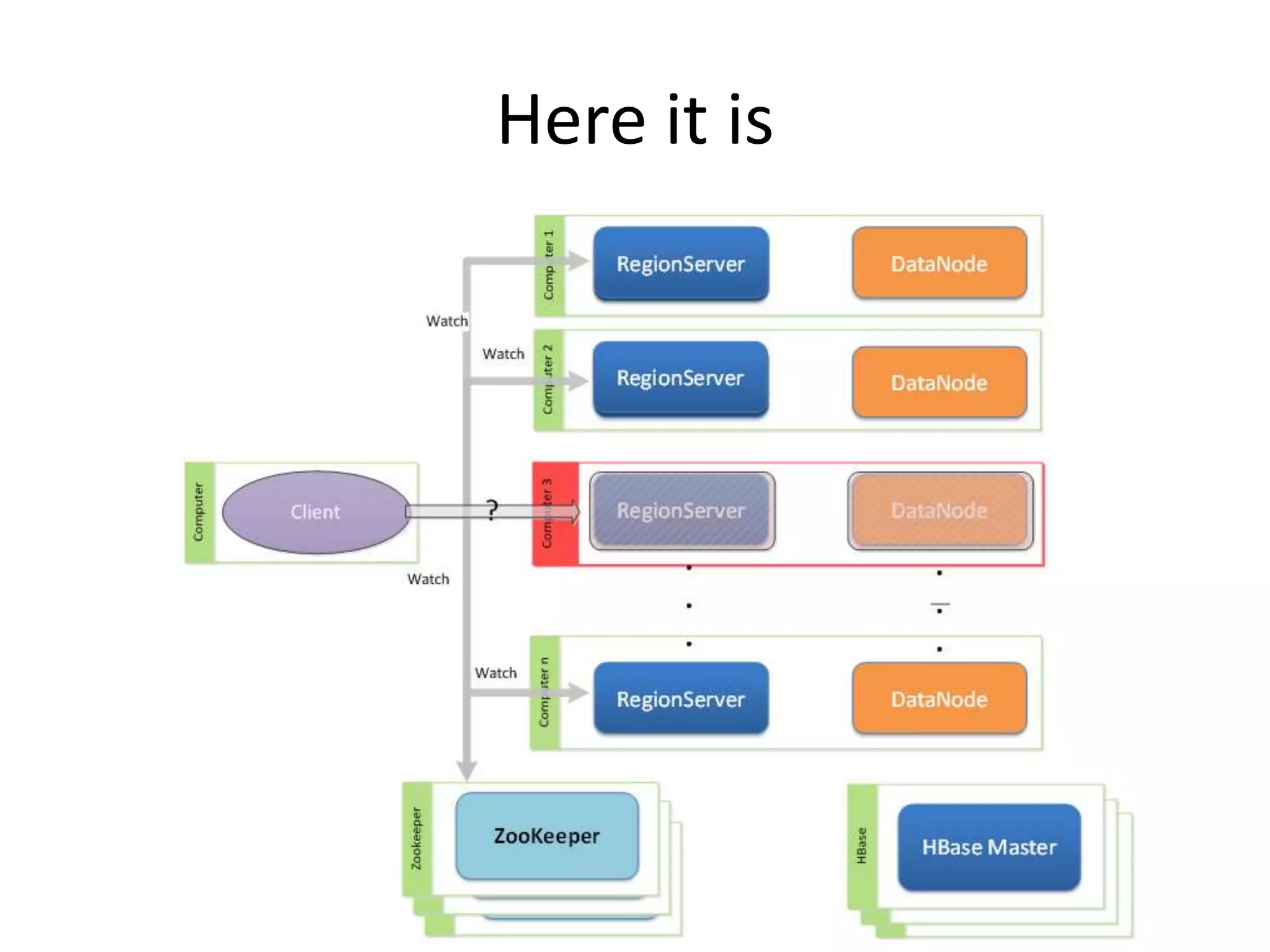




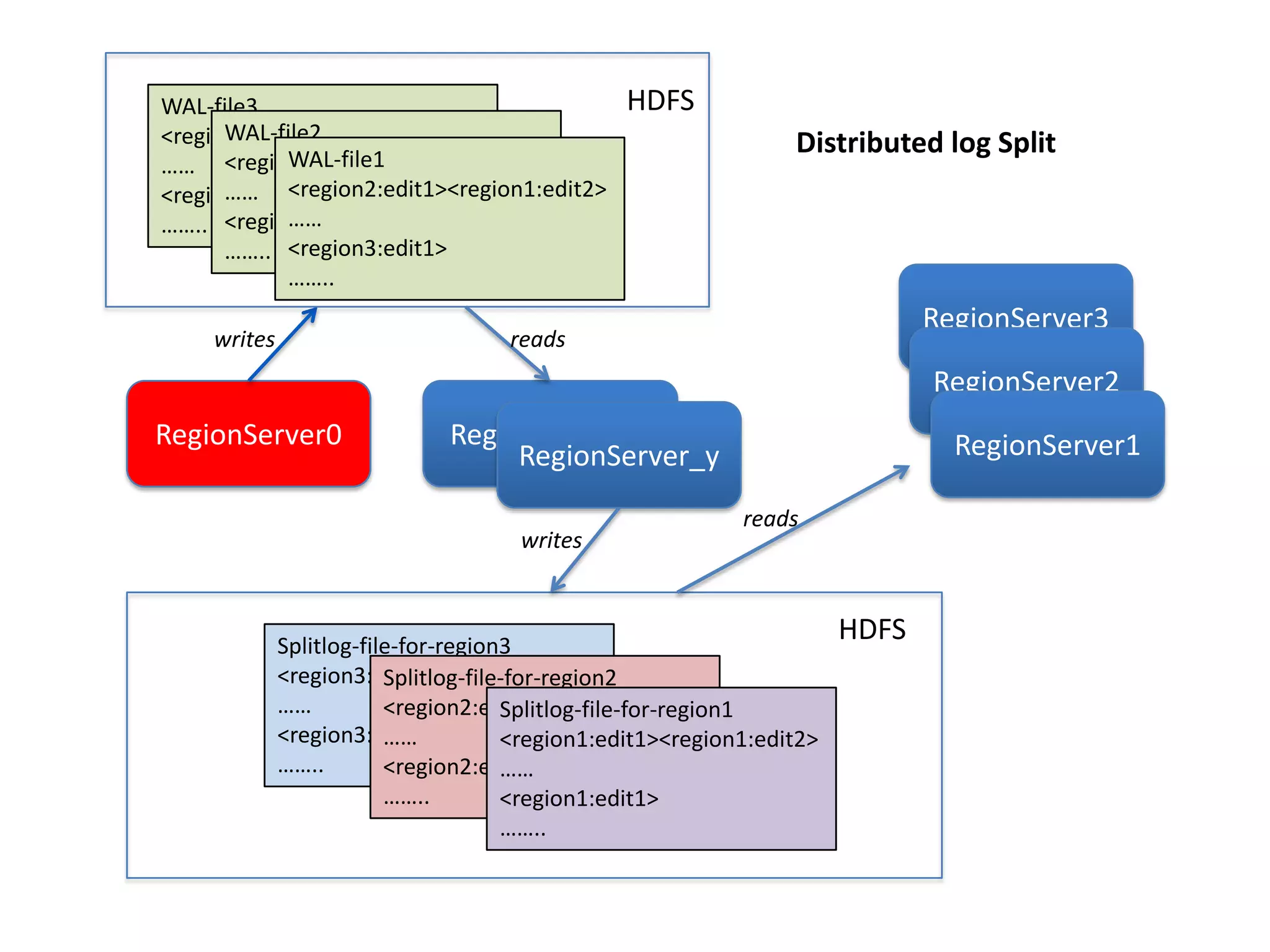
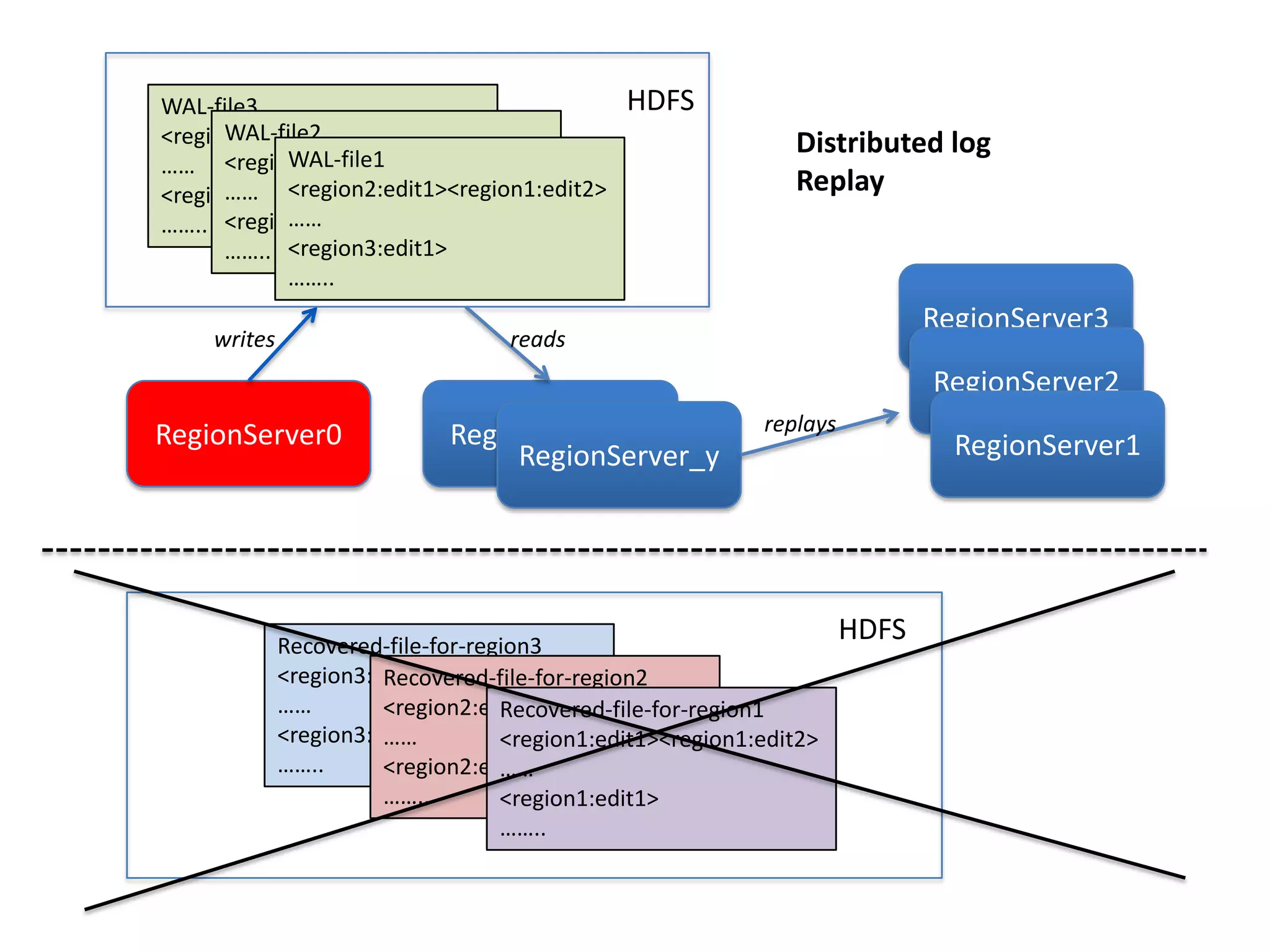




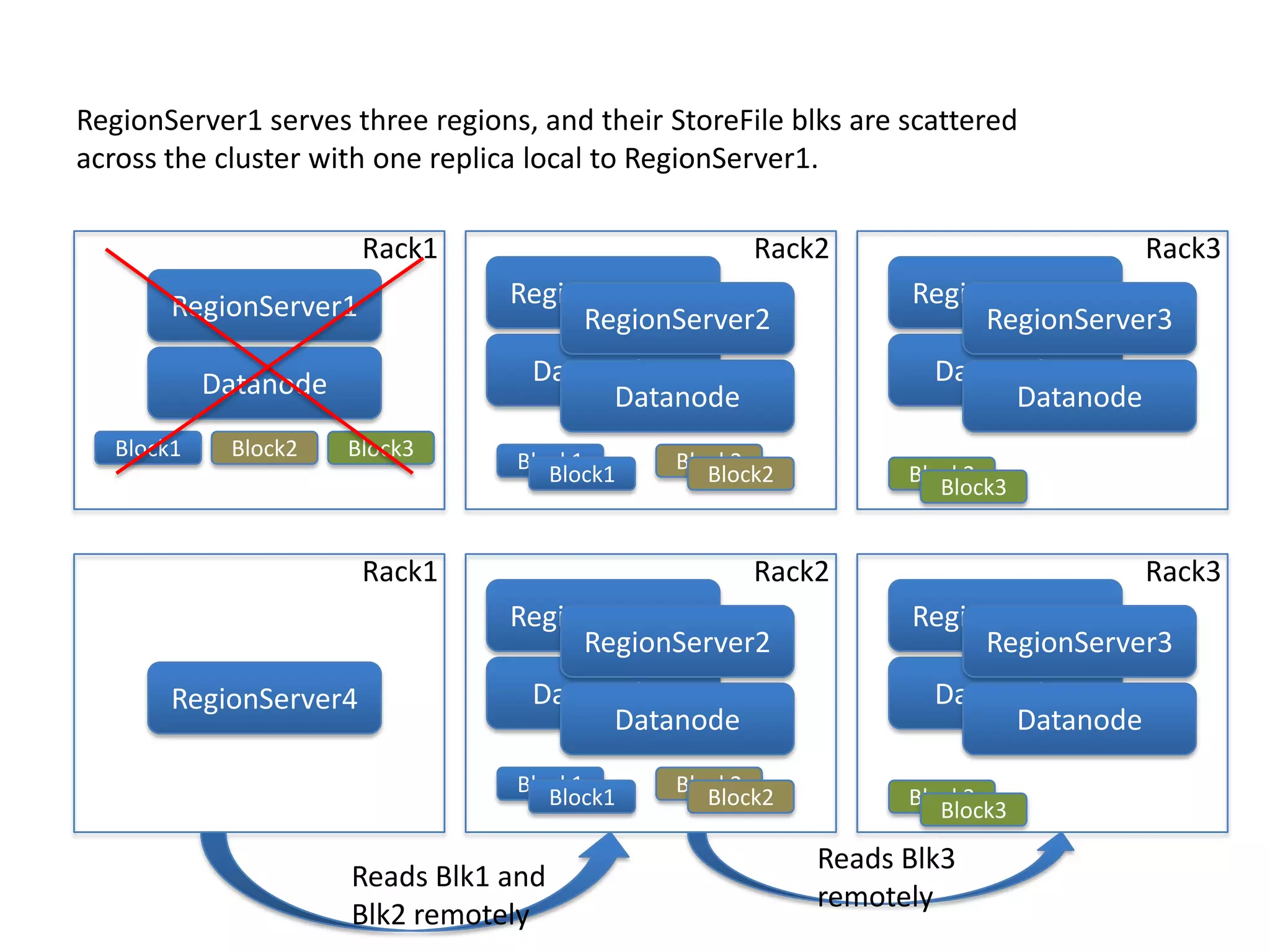
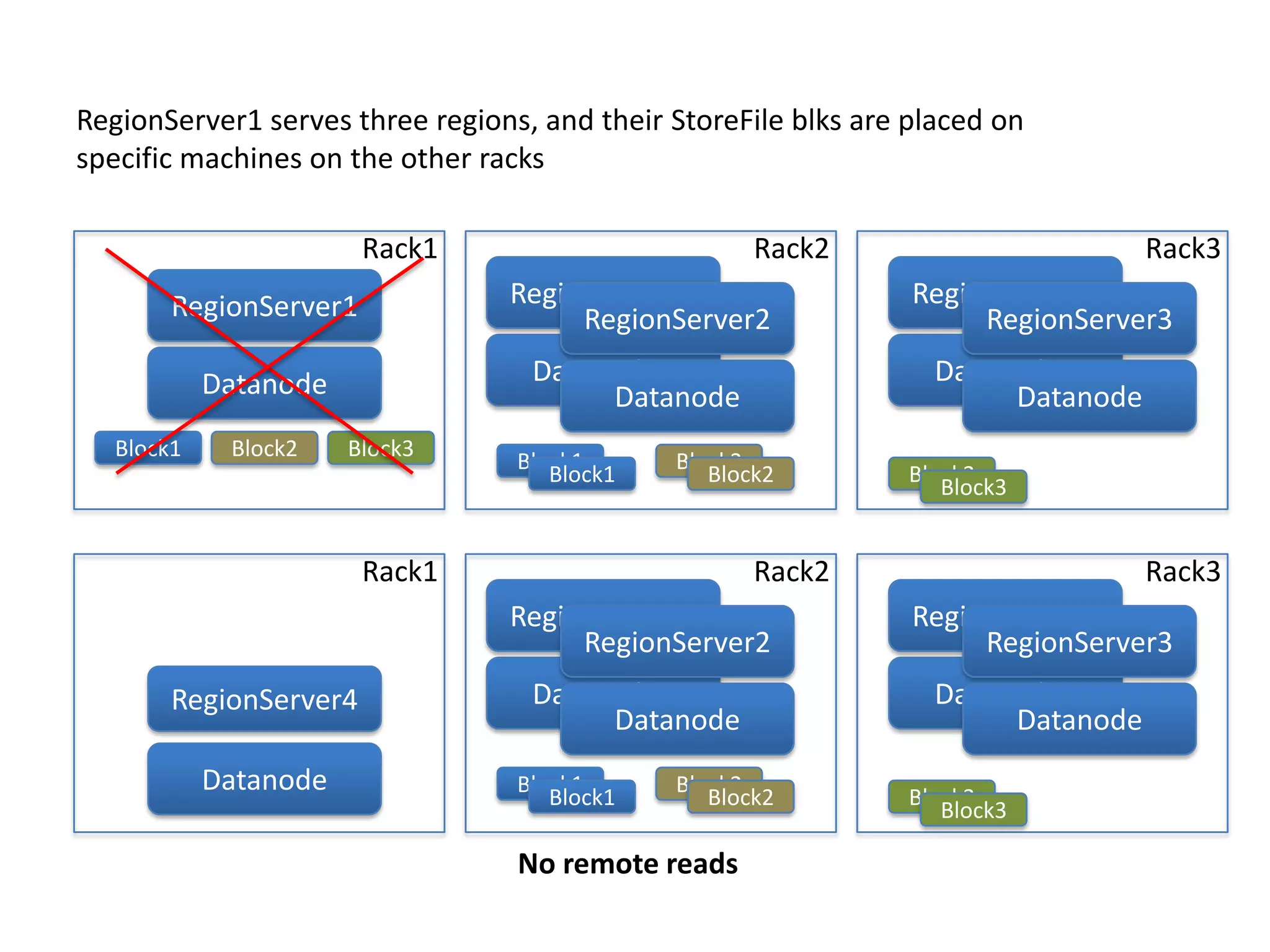



This document discusses ways to reduce the mean time to recovery (MTTR) in HBase to below 1 minute. It outlines improvements made to failure detection, region reassignment, and data recovery processes. Faster failure detection is achieved by lowering ZooKeeper timeouts to 30 seconds from 180. Region reassignment is made faster through parallelism. Data recovery is improved by rewriting the recovery process to directly write edits to regions instead of HDFS. These changes have reduced recovery times from 10-15 minutes to less than 1 minute in tests.





































































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)



