









![Zookeeper
Zookeeper
o Coordination for entire cluster
o Master selection
o Root region server lookup
o Node registration
o Client always communicates with Zookeper for lookups
(cached for sub-sequent calls)
hbase(main):001:0> zk "ls /hbase"
[safe-mode, root-region-server, rs, master, shutdown,
replication]](https://image.slidesharecdn.com/hadoop-hbase-operations-practices-130711033632-phpapp01/75/HBase-Operations-and-Best-Practices-15-2048.jpg)
































This document provides an overview and best practices for operating HBase clusters. It discusses HBase and Hadoop architecture, how to set up an HBase cluster including Zookeeper and region servers, high availability considerations, scaling the cluster, backup and restore processes, and operational best practices around hardware, disks, OS, automation, load balancing, upgrades, monitoring and alerting. It also includes a case study of a 110 node HBase cluster.
Introduction to HBase and speaker's credentials as a Data Architect.
Overview of the presentation agenda covering Big Data topics including HBase, architecture, and best practices.
Definition of Big Data, industry trends, advantages, and drawbacks.
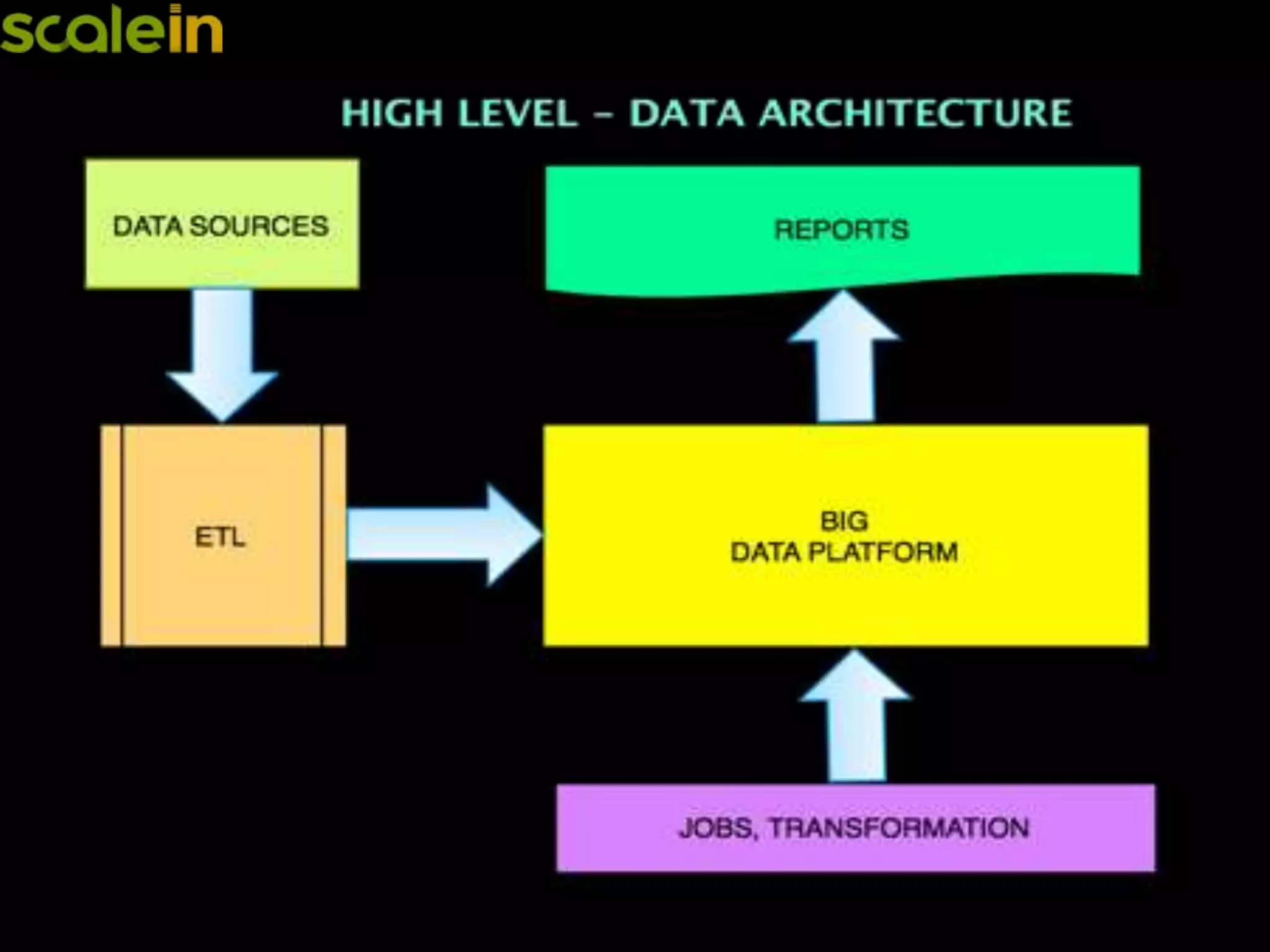
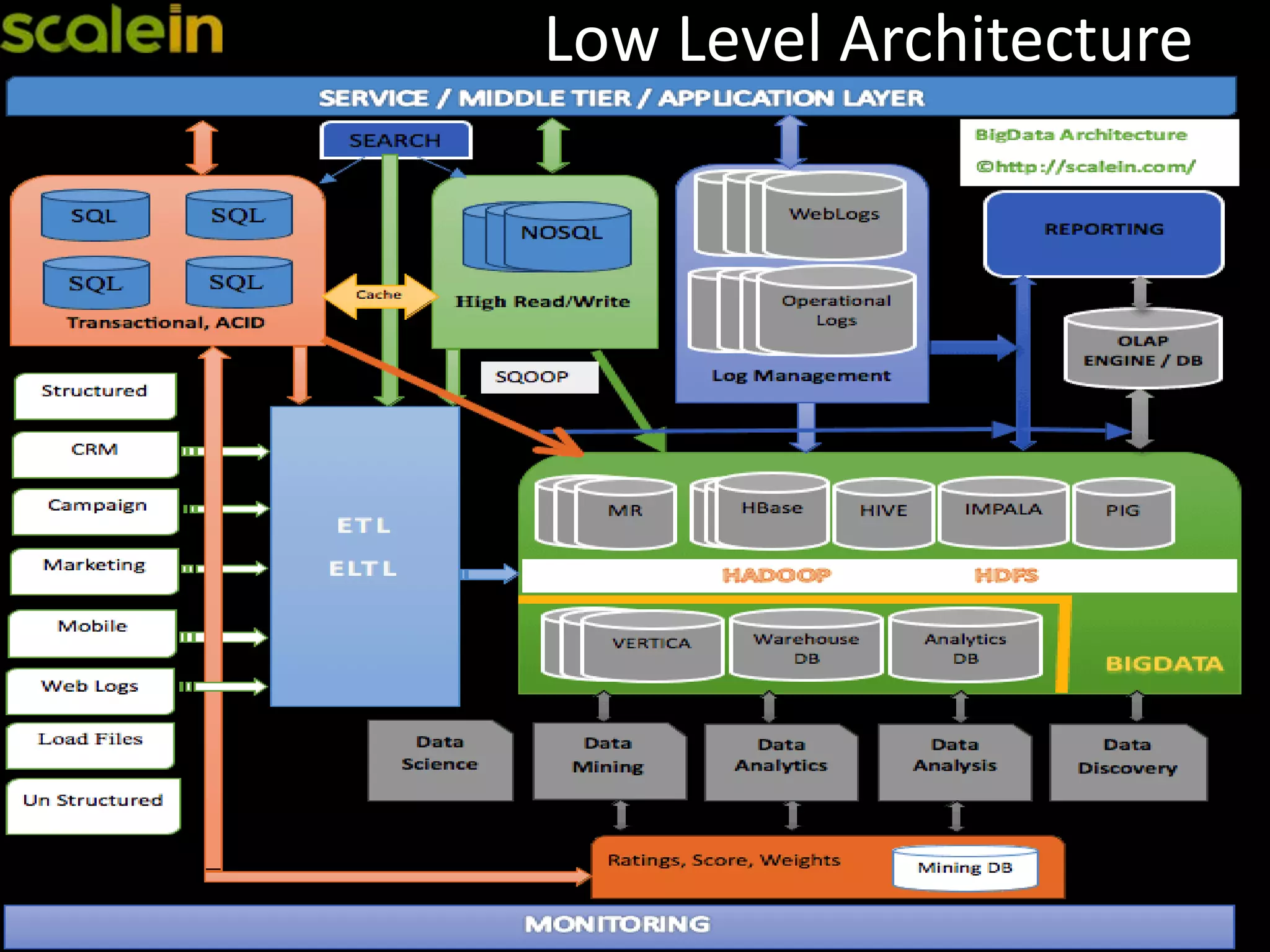
Overview of Big Data architecture and the focus on HBase.
Reasons for HBase adoption, including its scalability and coupling with Hadoop, comparing it to other technologies.
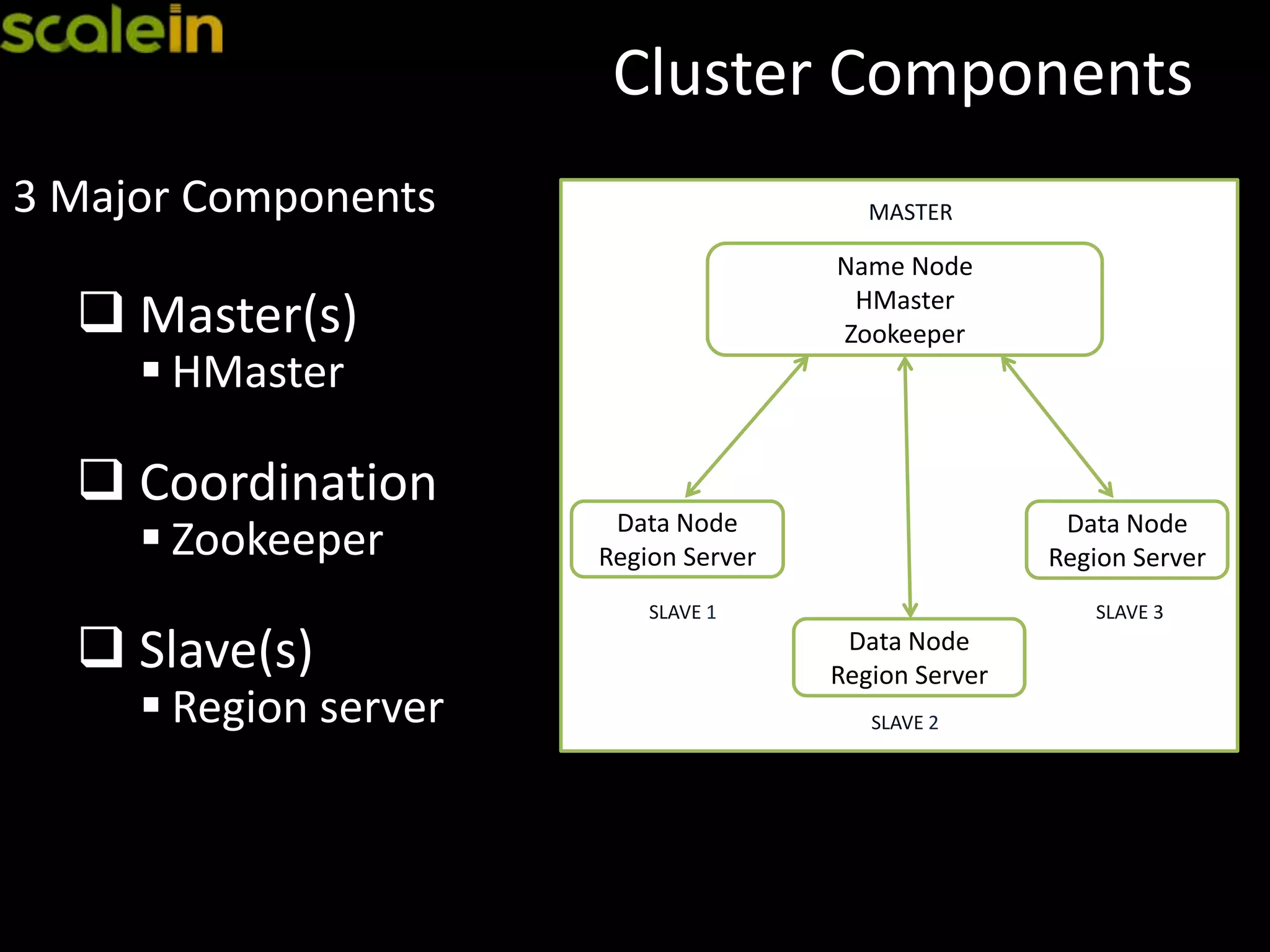
Components of HBase cluster setup, including masters, slaves, and Zookeeper coordination.
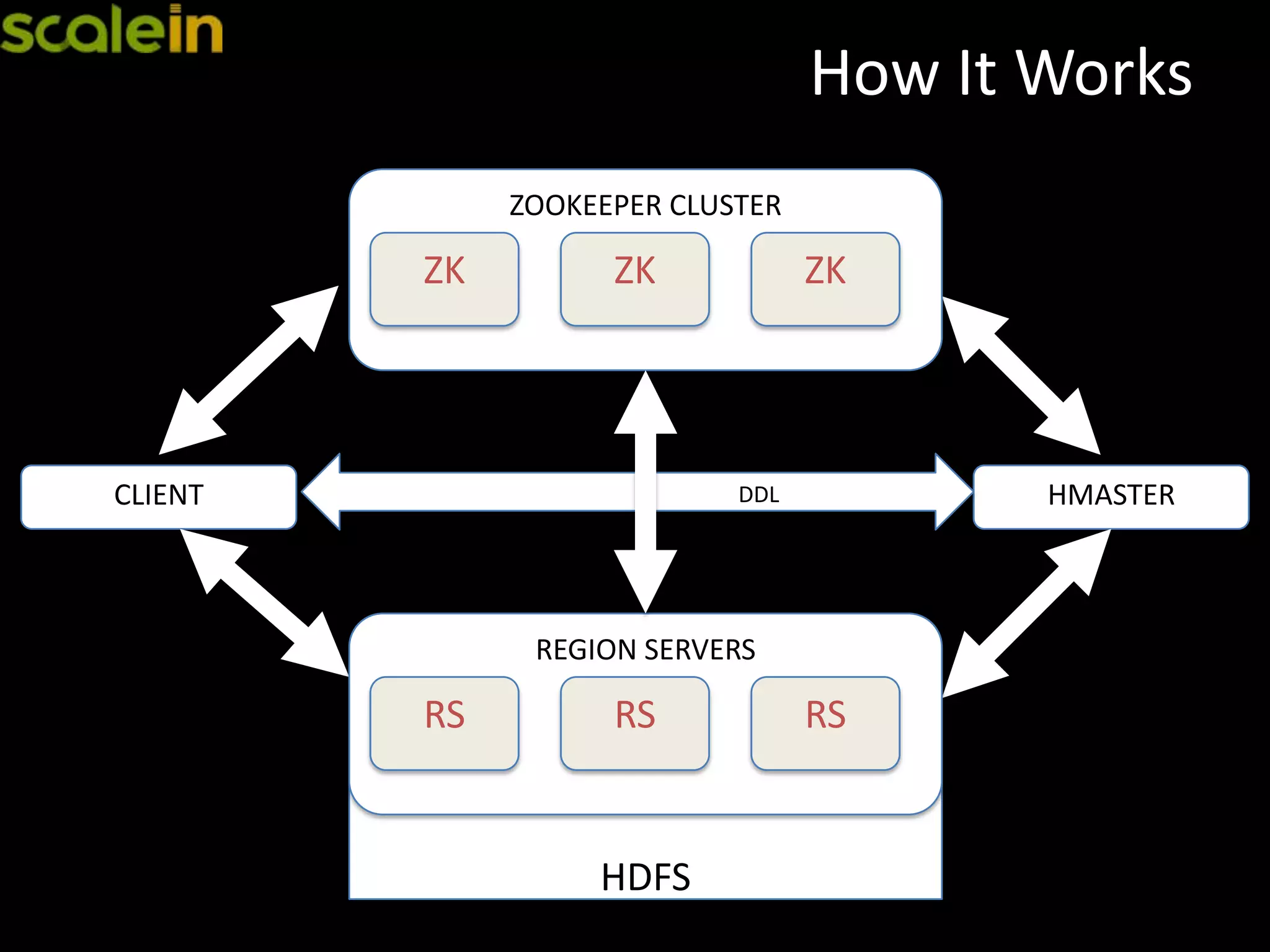
Details on Zookeeper's role in cluster coordination and its setup for optimal performance.
Function and setup of Region Servers in HBase, covering I/O requests and data storage organization.
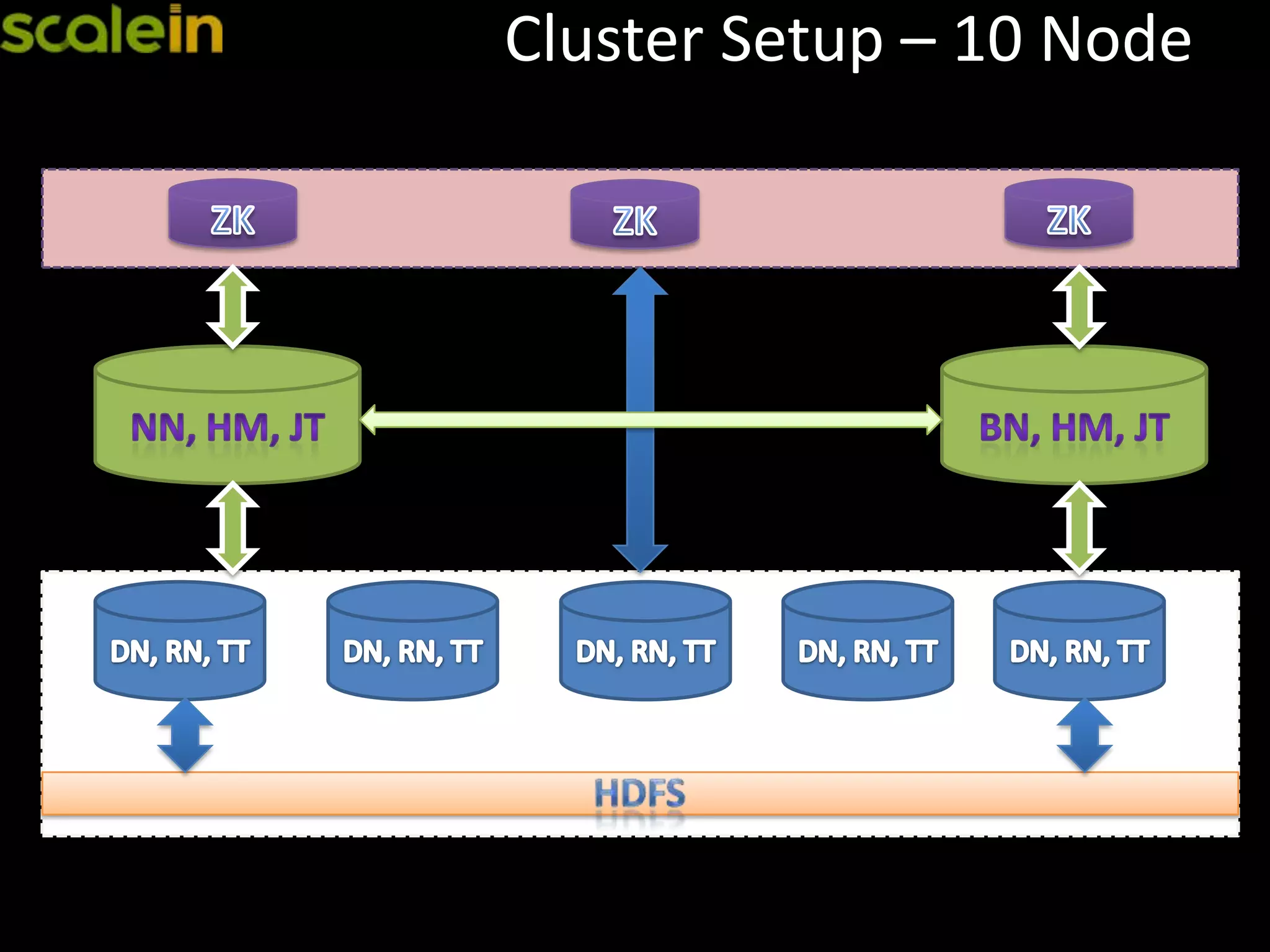
General overview of a 10-node HBase cluster setup.
Importance of High Availability (HA) in HBase clusters and possible failure points.
Techniques for ensuring HA in HBase, including replication strategies and Zookeeper management.
Methods for scaling HBase clusters effectively while considering write designs.
Importance of performance benchmarking and key tuning strategies for HBase.
Explains built-in and external backup strategies for HBase and mechanisms for point-in-time restores.
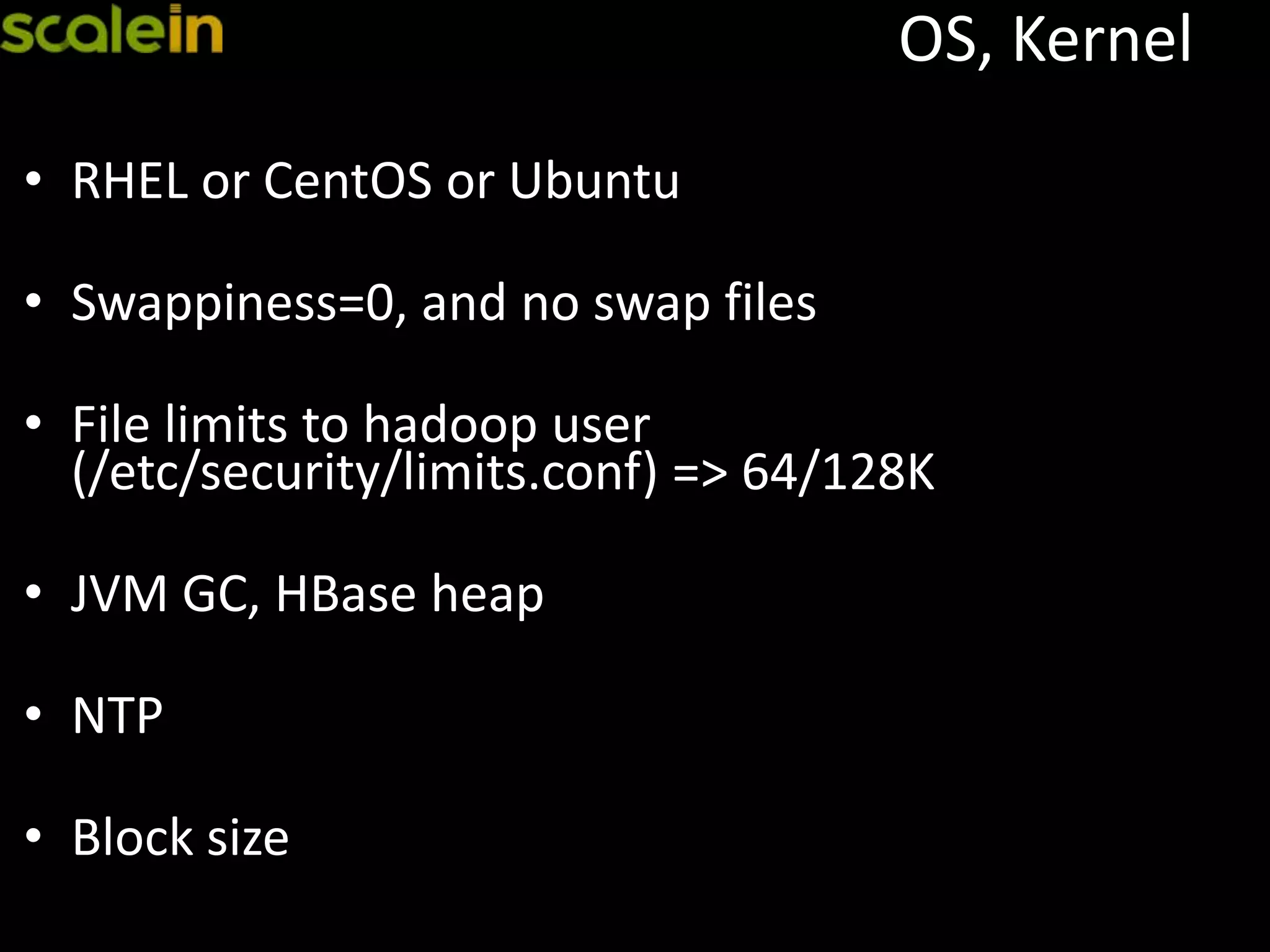
Recommendations for hardware, disks, OS, automation, and load balancing for optimal HBase operation.
Importance of planning upgrades carefully and establishing robust monitoring and alerting systems.
Detailed example of a 110 node cluster setup using HBase, showcasing tools and environment used.
Final remarks and invitation for questions.



































































