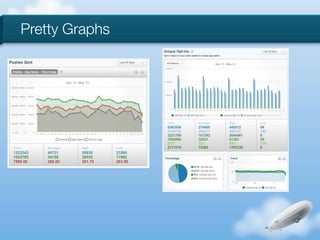
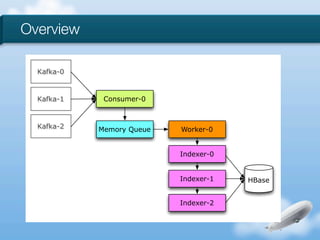
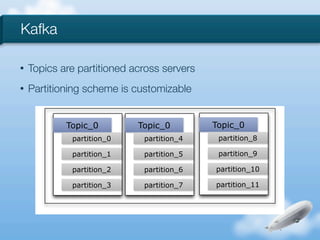
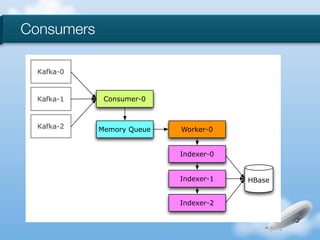
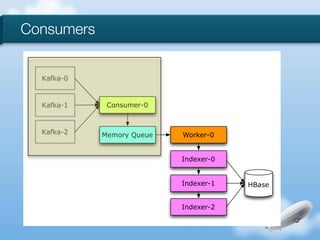
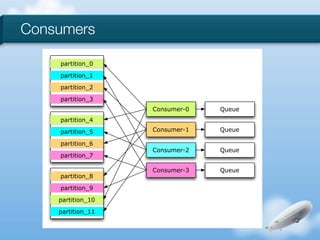
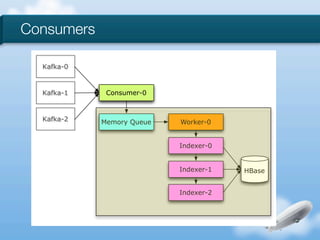
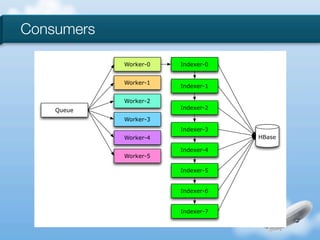
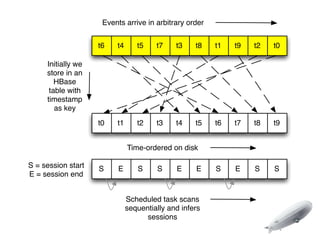
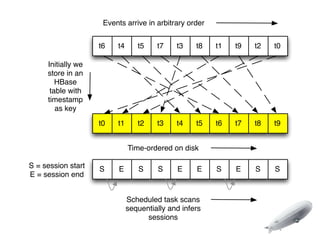
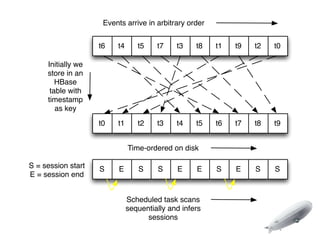
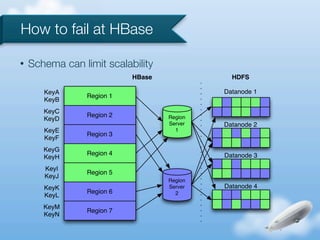
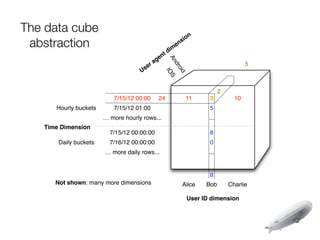
The document discusses the implementation of near-realtime analytics using Kafka and HBase at Urban Airship, highlighting the challenges and methodologies involved in processing large volumes of data from mobile services. It outlines the architecture of Kafka for efficient data streaming and the advantages of HBase for low-latency data querying, as well as the strategies for counting and managing asynchronous event data. Key advantages of the approach include high scalability and fast performance, but it also acknowledges potential difficulties such as schema limitations and the need for careful resource management.






















































![[Hadoop Meetup] Apache Hadoop 3 community update - Rohith Sharma](https://cdn.slidesharecdn.com/ss_thumbnails/apachehadoop3communityupdate-rohith-171222071357-thumbnail.jpg?width=640&height=640&fit=bounds)




















![Realtime Analytics With Elasticsearch [New Media Inspiration 2013]](https://cdn.slidesharecdn.com/ss_thumbnails/realtimeanalyticselasticsearch-karelminarik-nmi2013-130119084635-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)














![[Hi c2011]building mission critical messaging system(guoqiang jerry)](https://cdn.slidesharecdn.com/ss_thumbnails/hic2011buildingmissioncriticalmessagingsystemguoqiangjerry-111206111202-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

























