Downloaded 53 times

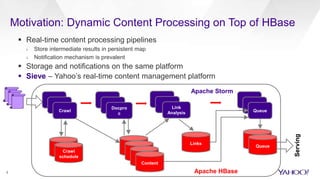


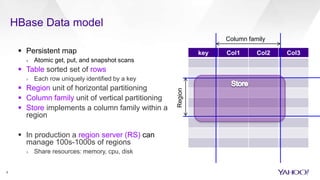

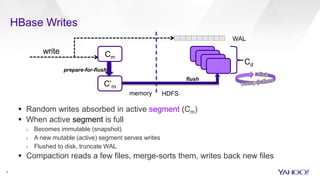
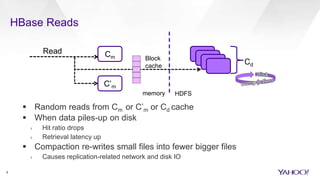


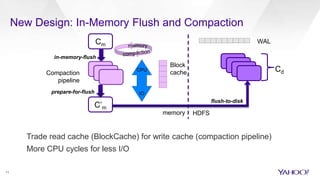


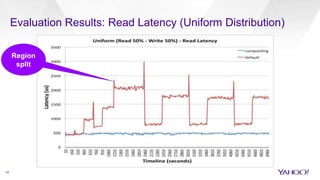











HBase Accelerated introduces an in-memory flush and compaction pipeline for HBase to improve performance of real-time workloads. By keeping data in memory longer and avoiding frequent disk flushes and compactions, it reduces I/O and improves read and scan latencies. Evaluation on workloads with high update rates and small working sets showed the new approach significantly outperformed the default HBase implementation by serving most data from memory. Work is ongoing to further optimize the in-memory representation and memory usage.











































































































