













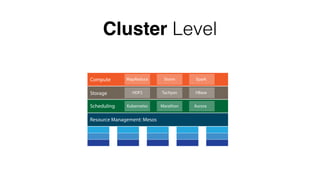
![Node Level
Hardware
OS/Kernel
Mesos
Slave
Docker
Salt
Minion
Containers
Kafka
Broker
HBase
HRS
[APP]](https://image.slidesharecdn.com/operations-session7a-150605170215-lva1-app6892/85/HBaseCon-2015-Elastic-HBase-on-Mesos-22-320.jpg)



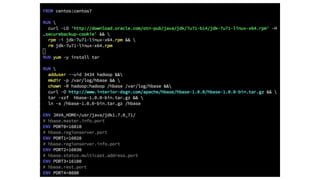



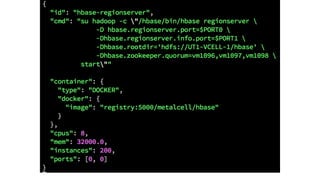















![Contact
• @clehene
• clehene@[gmail | adobe].com
• hstack.org](https://image.slidesharecdn.com/operations-session7a-150605170215-lva1-app6892/85/HBaseCon-2015-Elastic-HBase-on-Mesos-47-320.jpg)

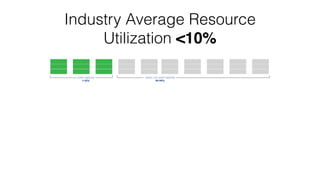
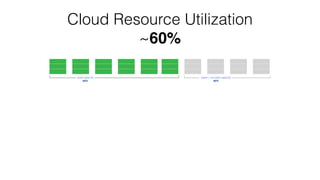
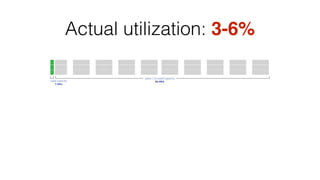
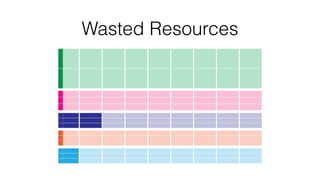
The document discusses the challenges and opportunities for optimizing resource utilization in HBase deployments within a Mesos-managed environment. It emphasizes the importance of elasticity, mixed workloads, and Docker containers for improved resource sharing and management. Key goals include achieving multi-tenancy, real-time scheduling, and efficient scaling to meet varying demands in cloud infrastructure.











































































































