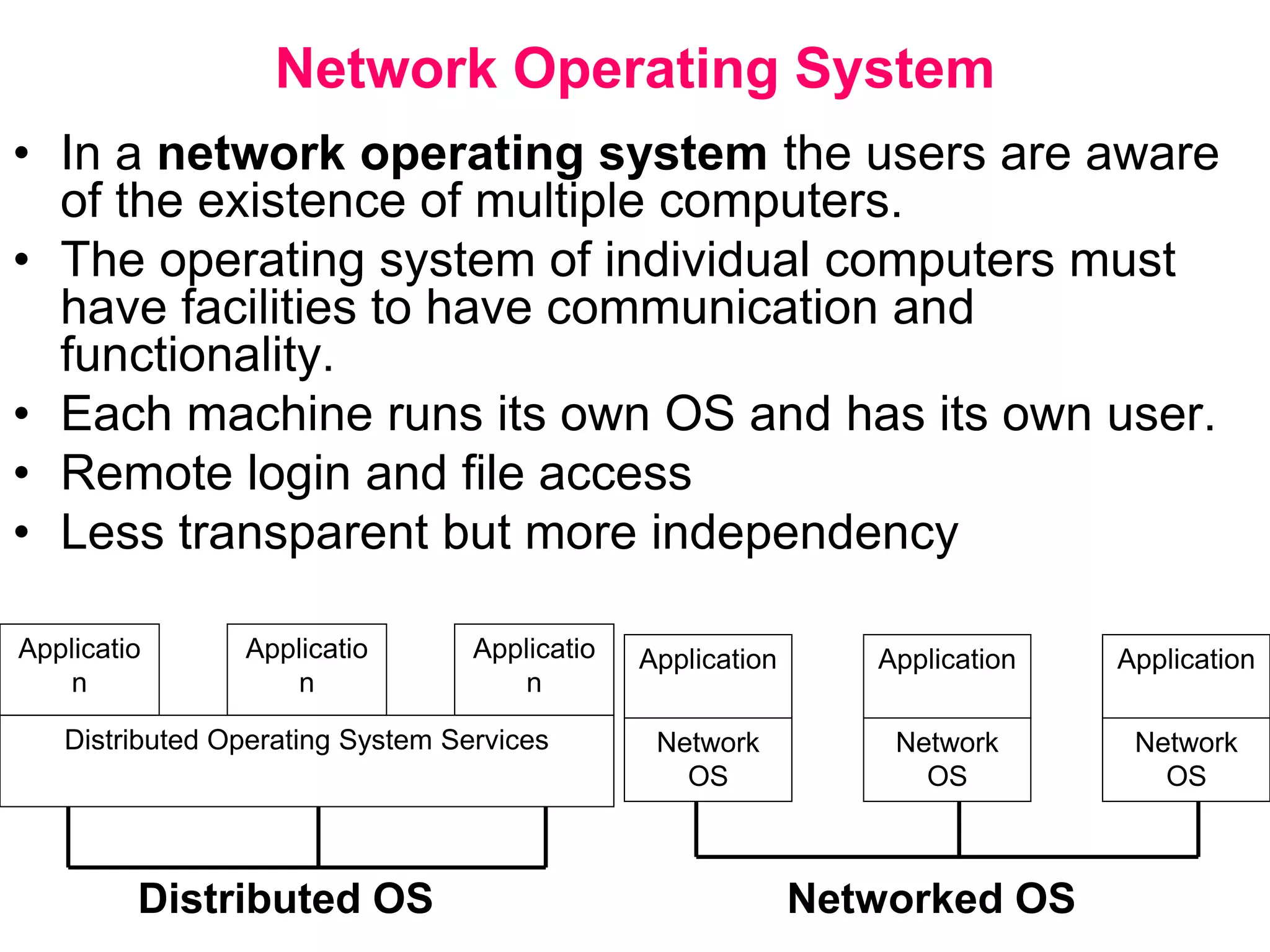
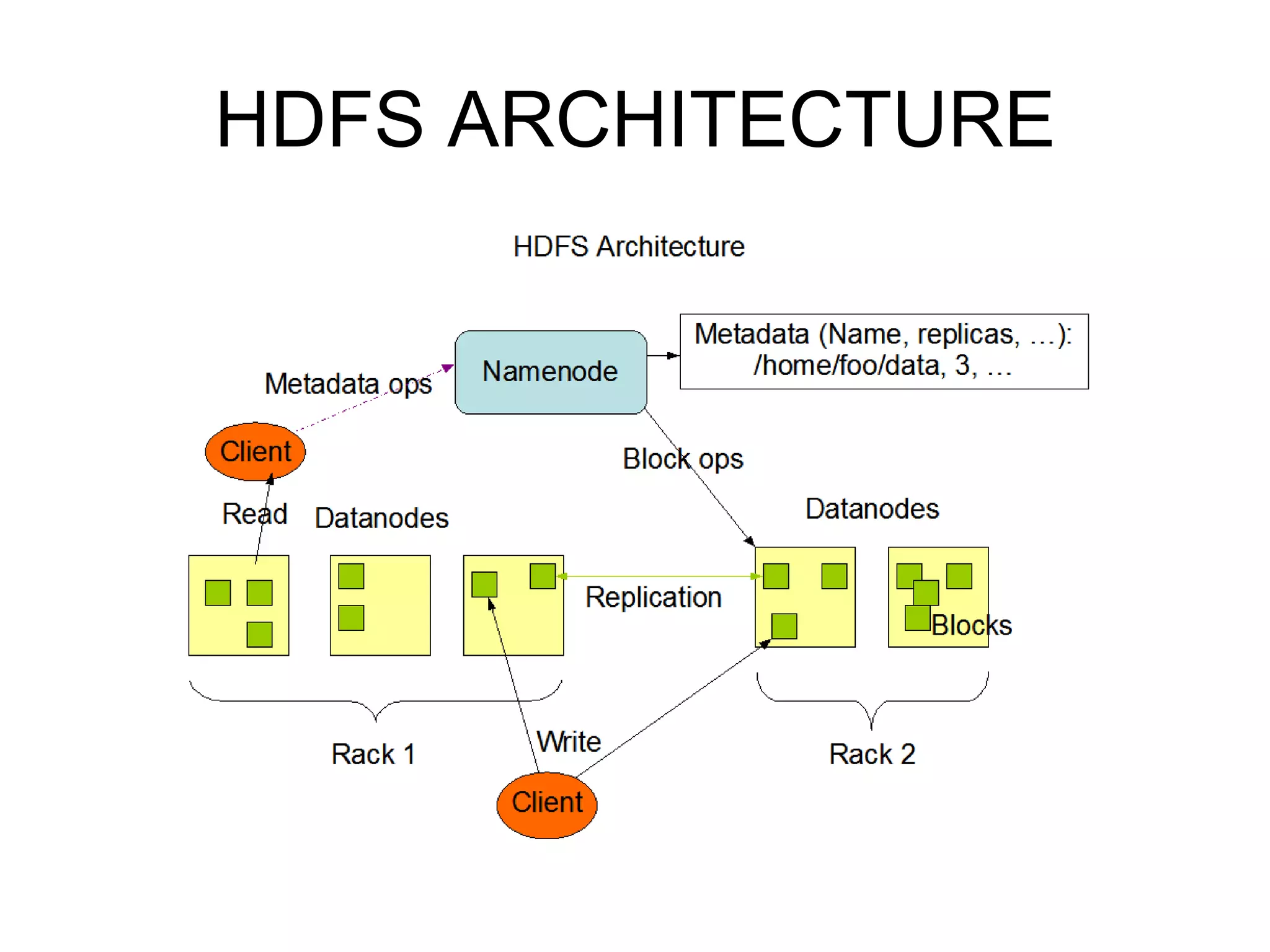
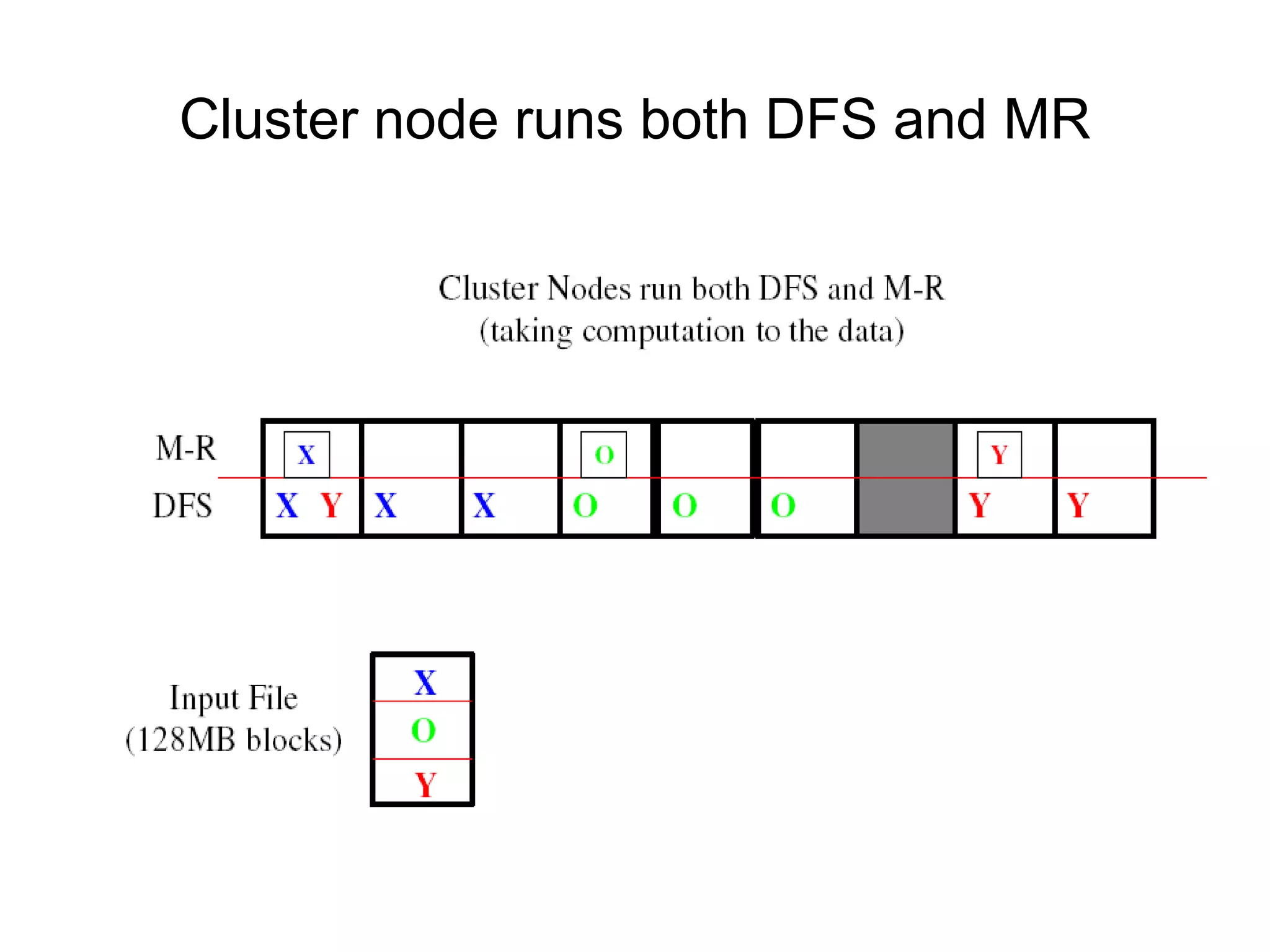
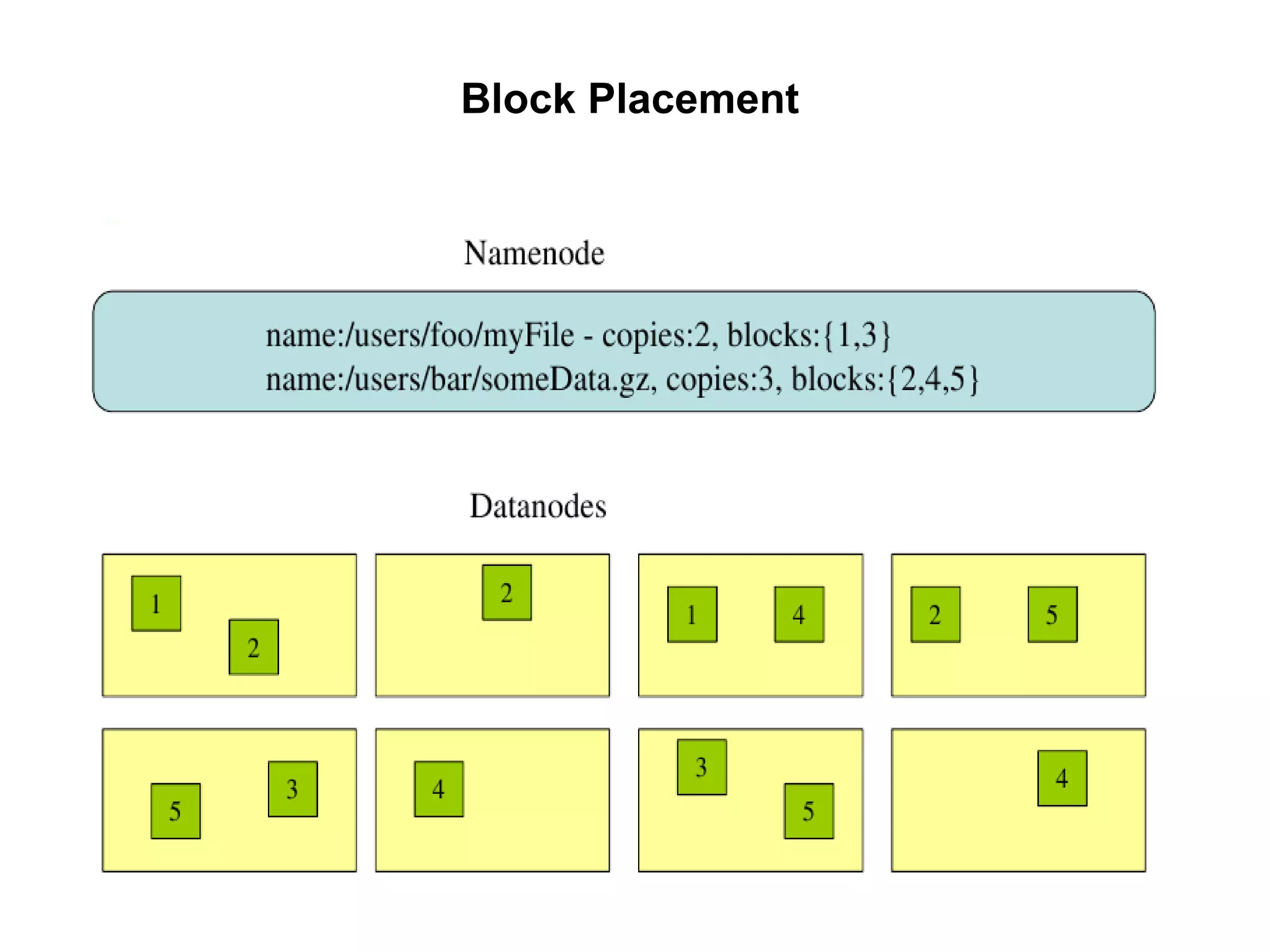
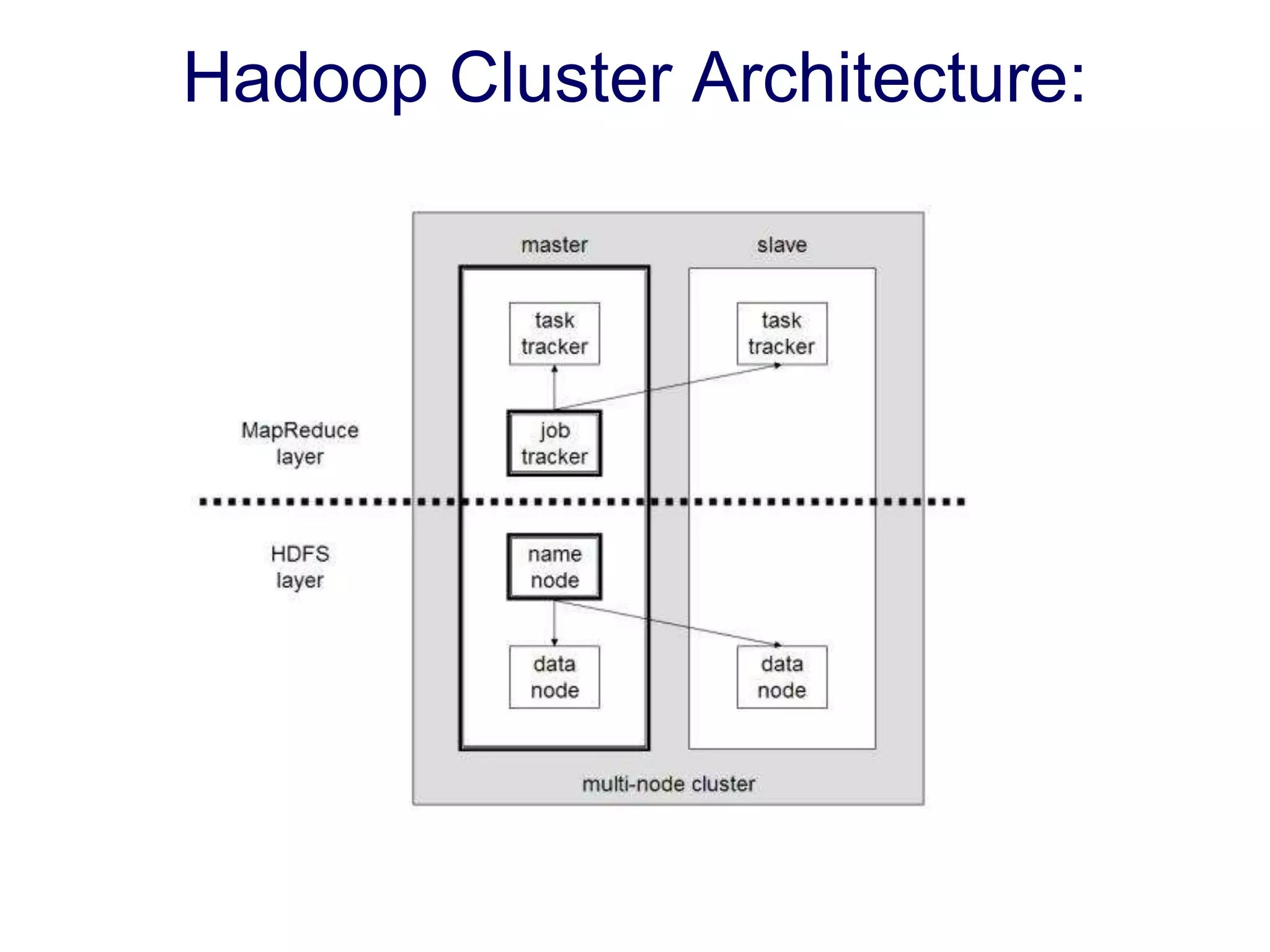
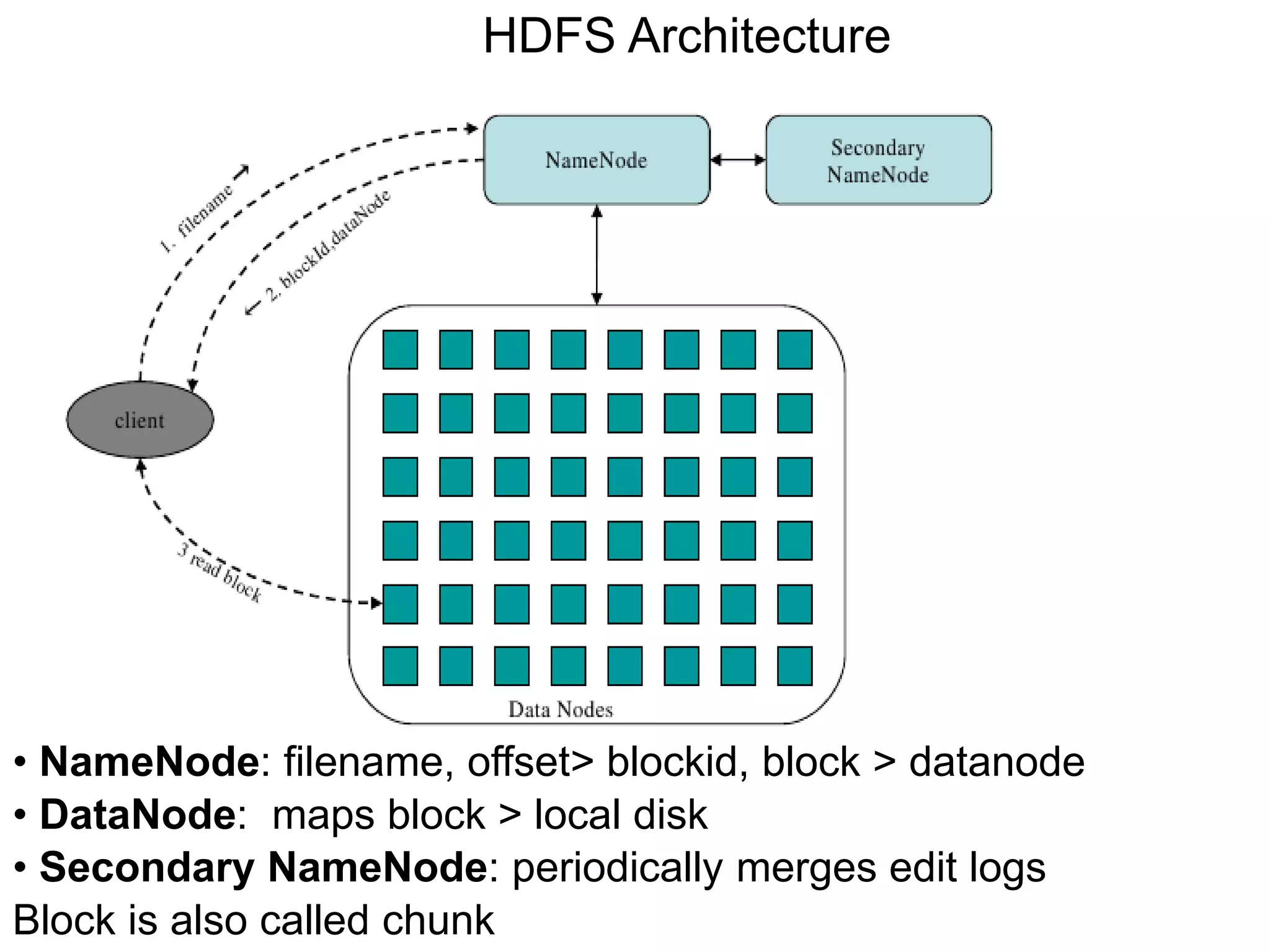
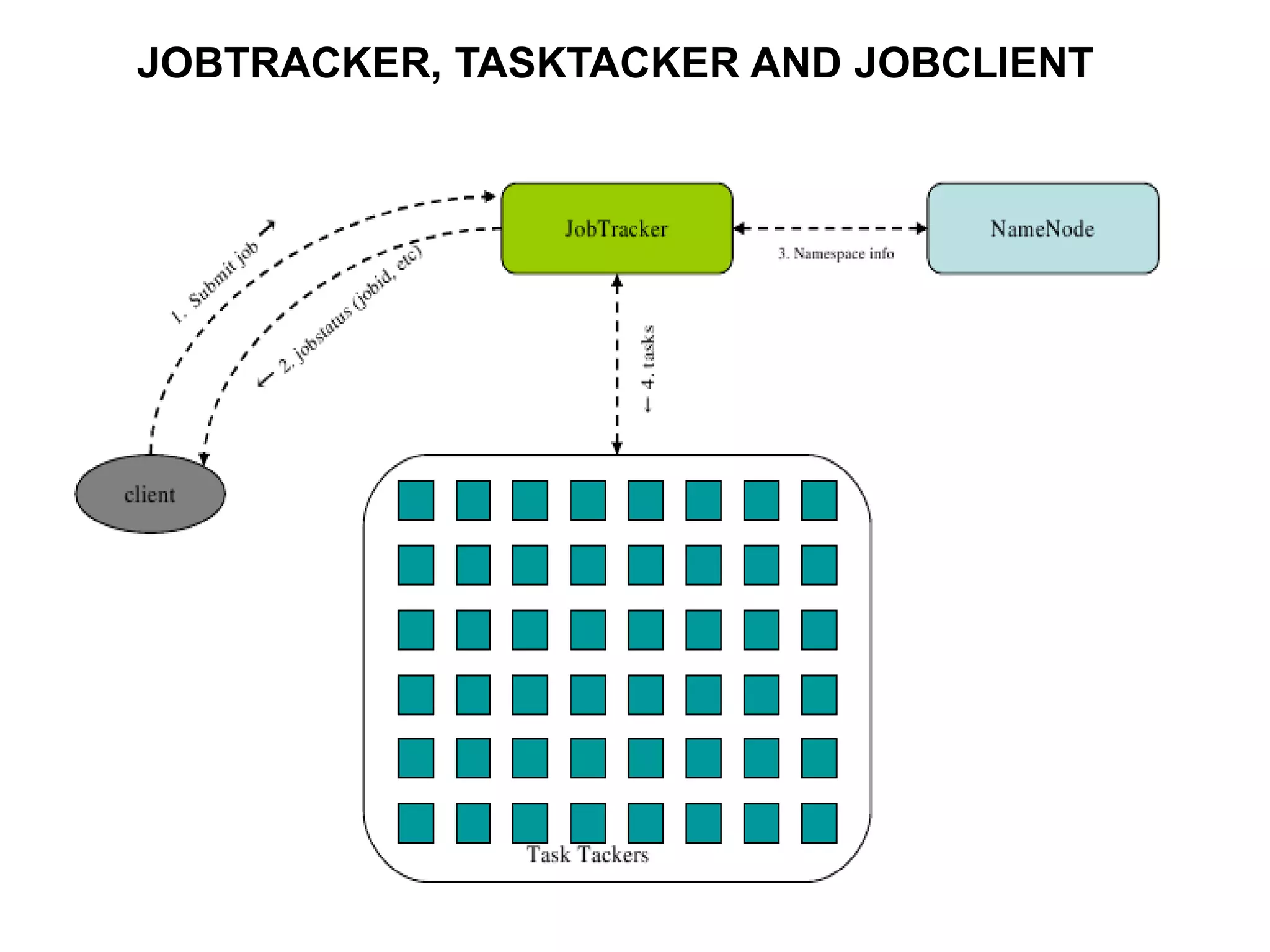
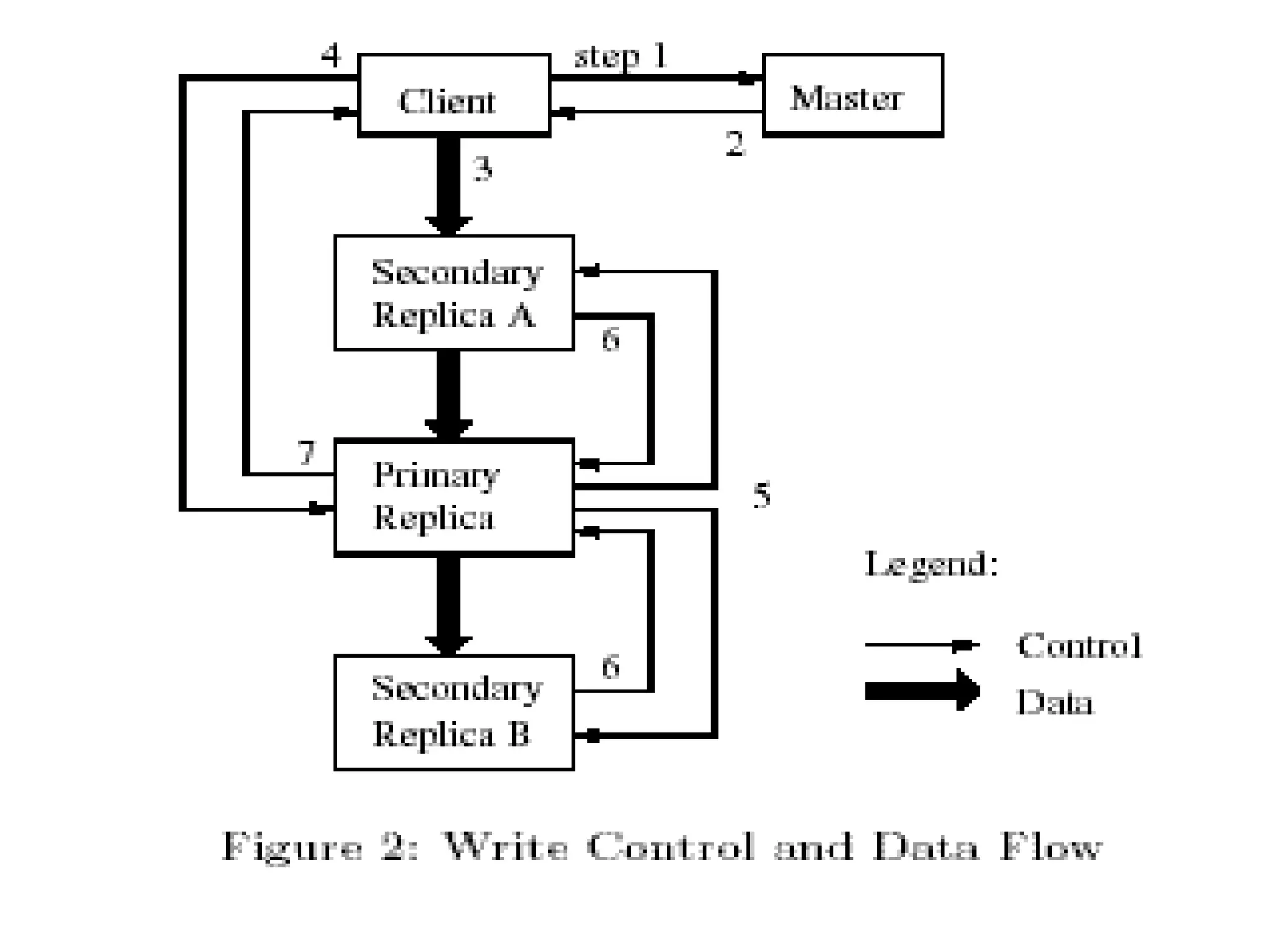
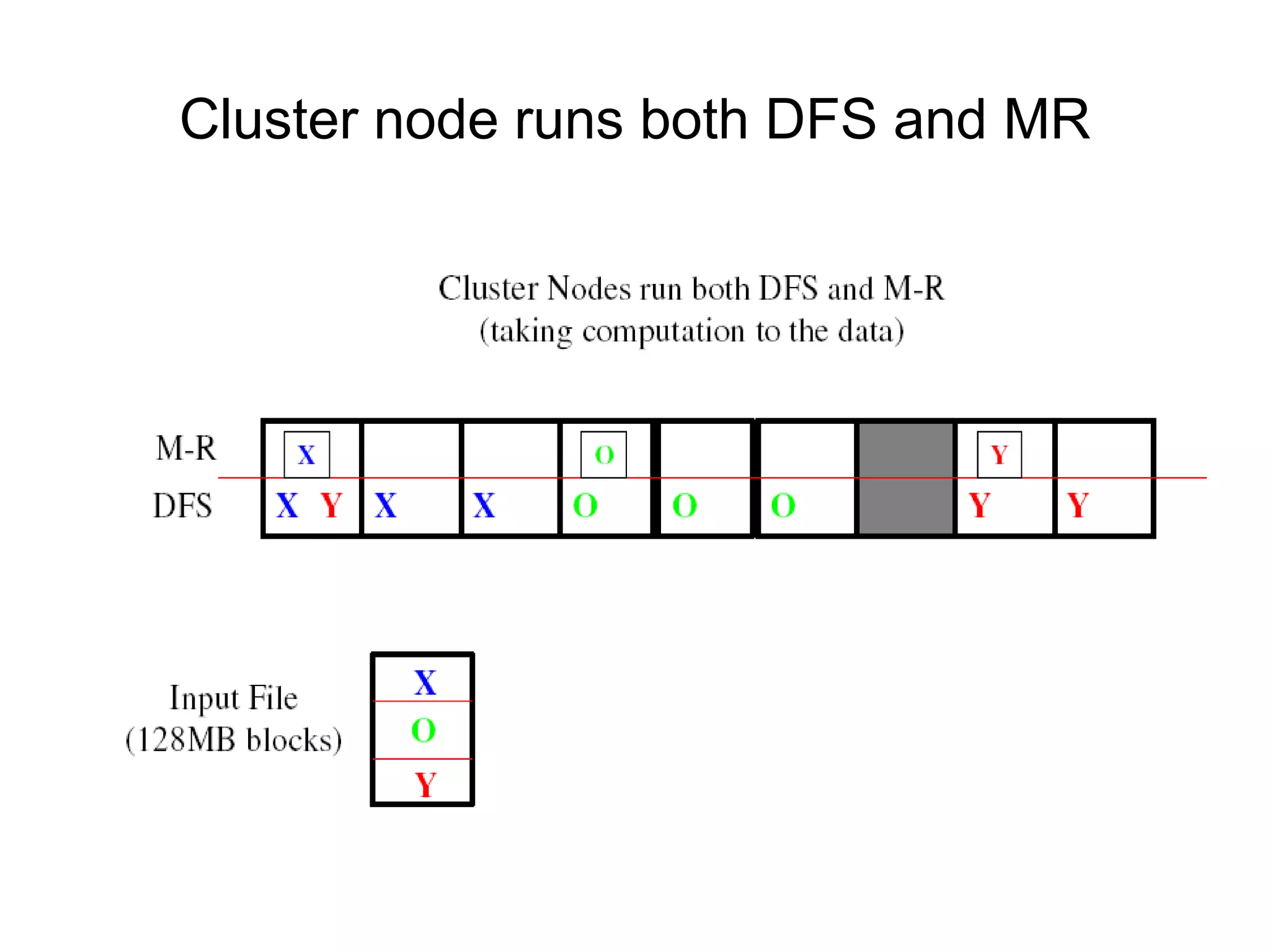
Hadoop is a framework for distributed storage and processing of large datasets across clusters of commodity hardware. It includes HDFS, a distributed file system, and MapReduce, a programming model for large-scale data processing. HDFS stores data reliably across clusters and allows computations to be processed in parallel near the data. The key components are the NameNode, DataNodes, JobTracker and TaskTrackers. HDFS provides high throughput access to application data and is suitable for applications handling large datasets.