Downloaded 49 times







![Agenda
• Goals of CSBT[1]
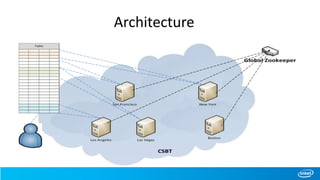
• Architecture of CSBT
– Highly Available Global Zookeeper Quorum
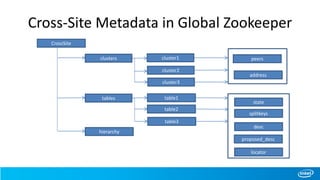
– Cross-Site Metadata in Global Zookeeper
– Cluster Locator
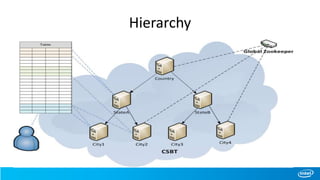
– Hierarchy
• Admin Operations on CSBT
• Read/Write operations on CrossSiteHTable
• Data Replication and FailOver
• Future Improvements
[1] – CSBT refers to Cross-Site Big Table](https://image.slidesharecdn.com/ecosystem-session3-140616155121-phpapp01/85/Cross-Site-BigTable-using-HBase-7-320.jpg)











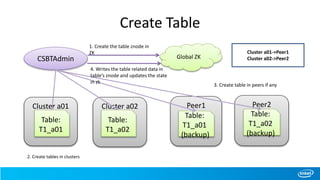
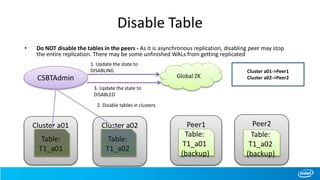
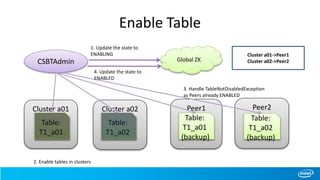
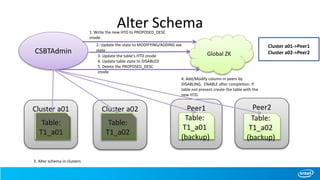



![Scan with Start/Stop row
• New scan APIs added where cluster names could be passed while creating scans
• Scan from table T1 [ start – “row1”, end – “row6” ] , clusters-[cluster a01, cluster a02]
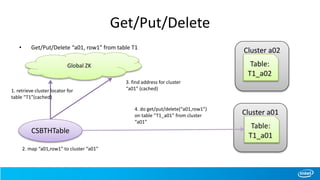
Cluster a01
Table:
T1_a01
CSBTHTable
Global ZK
1. retrieve cluster info for
table “T1”(cached)
2. find address for cluster
“a01” and “a02” (cached)
3. scan from(“a01,row1”) to
(“a01,row6) on table “T1_a01”
from cluster “a01”
4. scan from(“a02,row1”) to
(“a02,row6) on table “T1_a02”
from cluster “a02”
Cluster a02
Table:
T1_a02
Cluster a03
Table:
T1_a03](https://image.slidesharecdn.com/ecosystem-session3-140616155121-phpapp01/85/Cross-Site-BigTable-using-HBase-31-320.jpg)
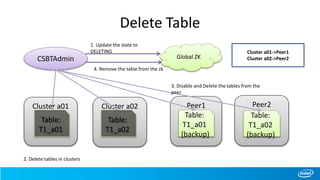
![Scan with Hierarchy
Scan from table T1 [ start – “row1”, end – “row6” ] , clusters-
[California]
California – virtual node
SFO, LA, San Diego – physical nodes](https://image.slidesharecdn.com/ecosystem-session3-140616155121-phpapp01/85/Cross-Site-BigTable-using-HBase-32-320.jpg)
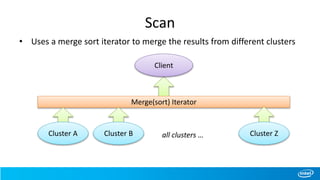



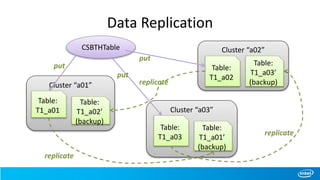
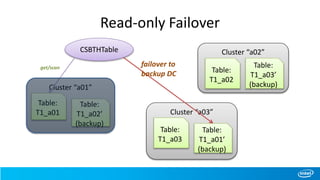




The document outlines the features and architecture of Apache HBase for cross-site big table implementations, highlighting the use of partitioning rules to efficiently manage data across geographically distributed clusters. It discusses the necessity for high data availability, ease of access, and a hierarchical relationship among data centers, along with detailed operations for managing tables and replication processes. Future improvements are suggested, including enhanced security measures and optimizations for MapReduce tasks across clusters.









































































































