






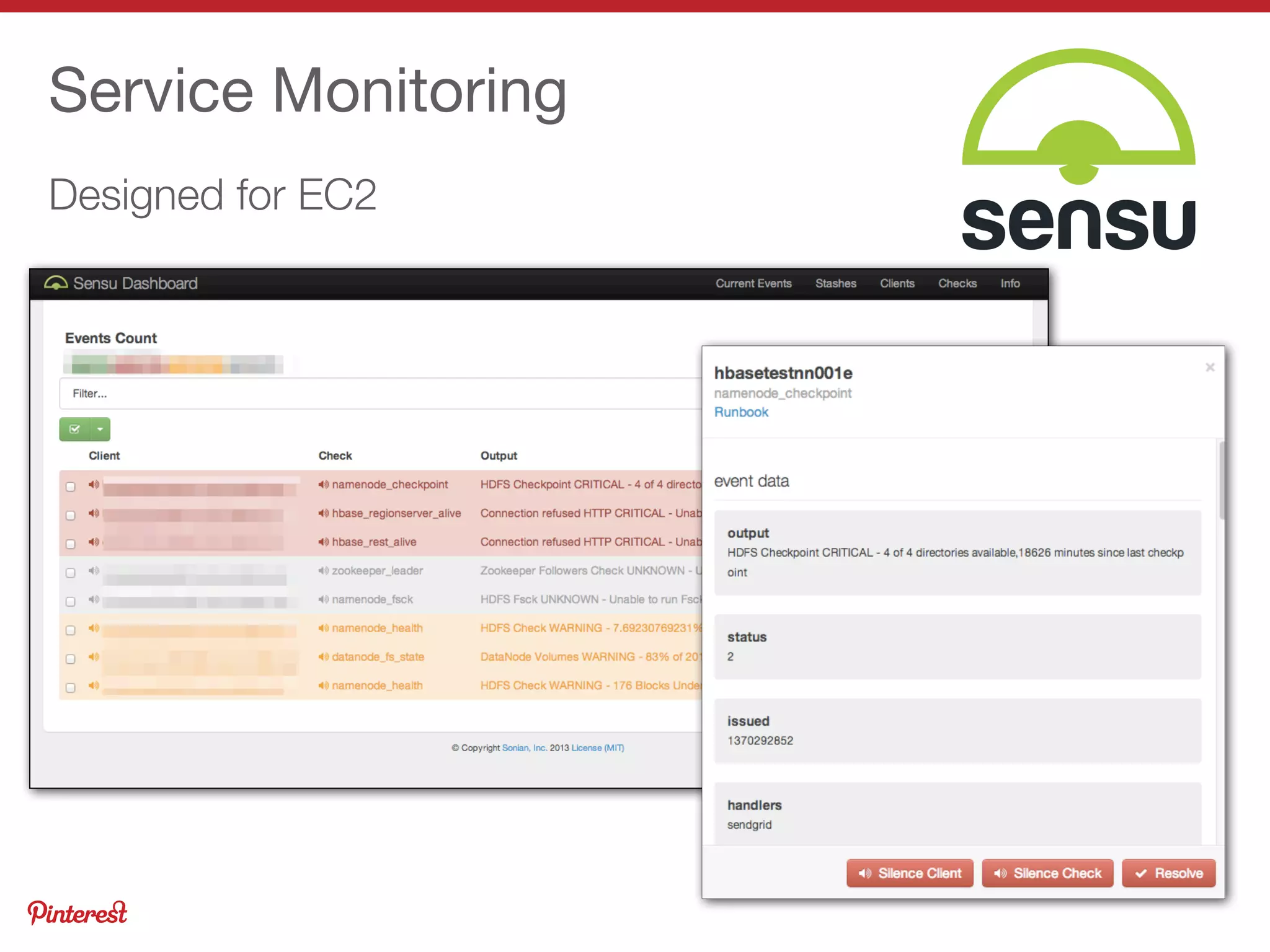

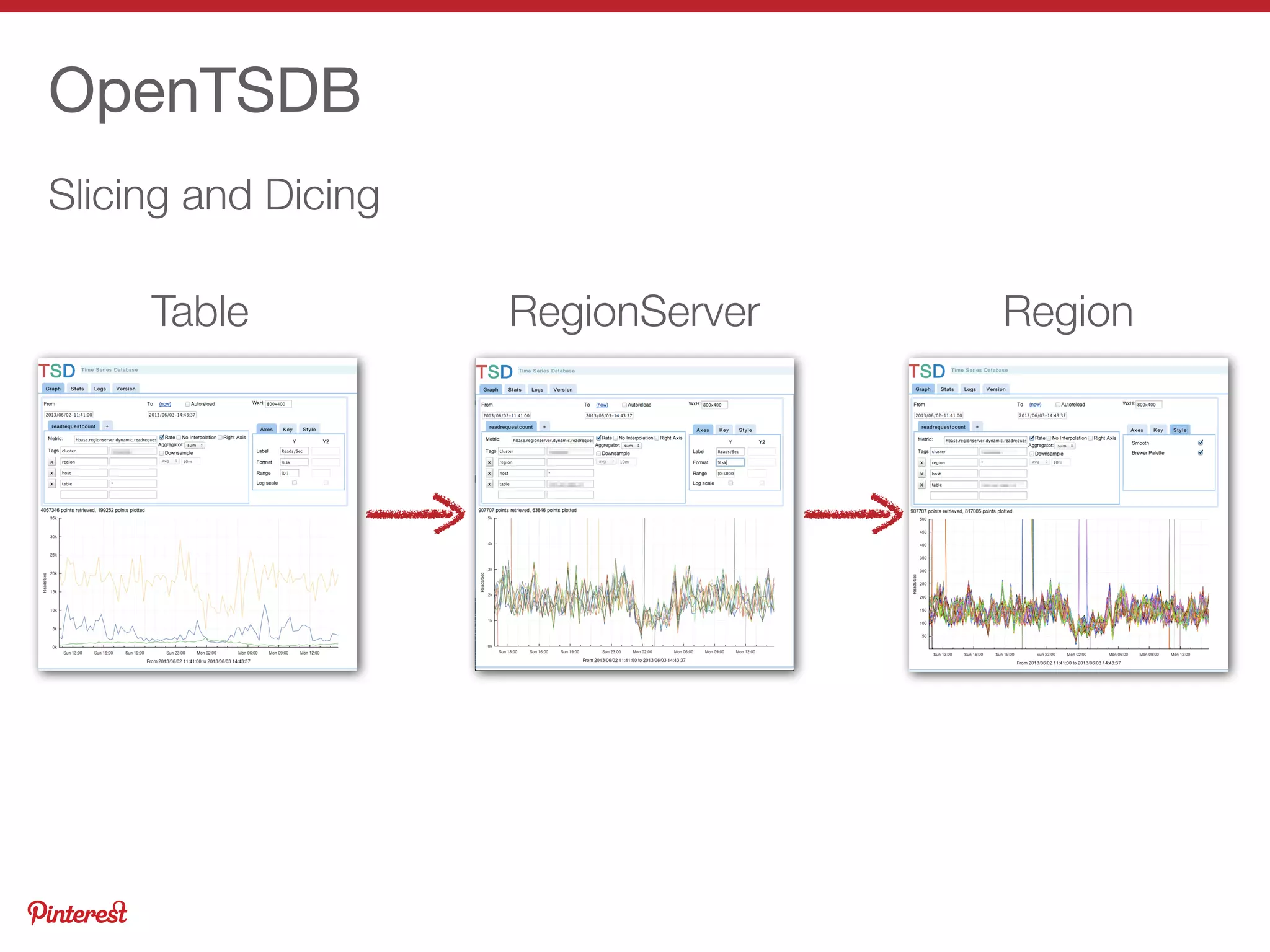
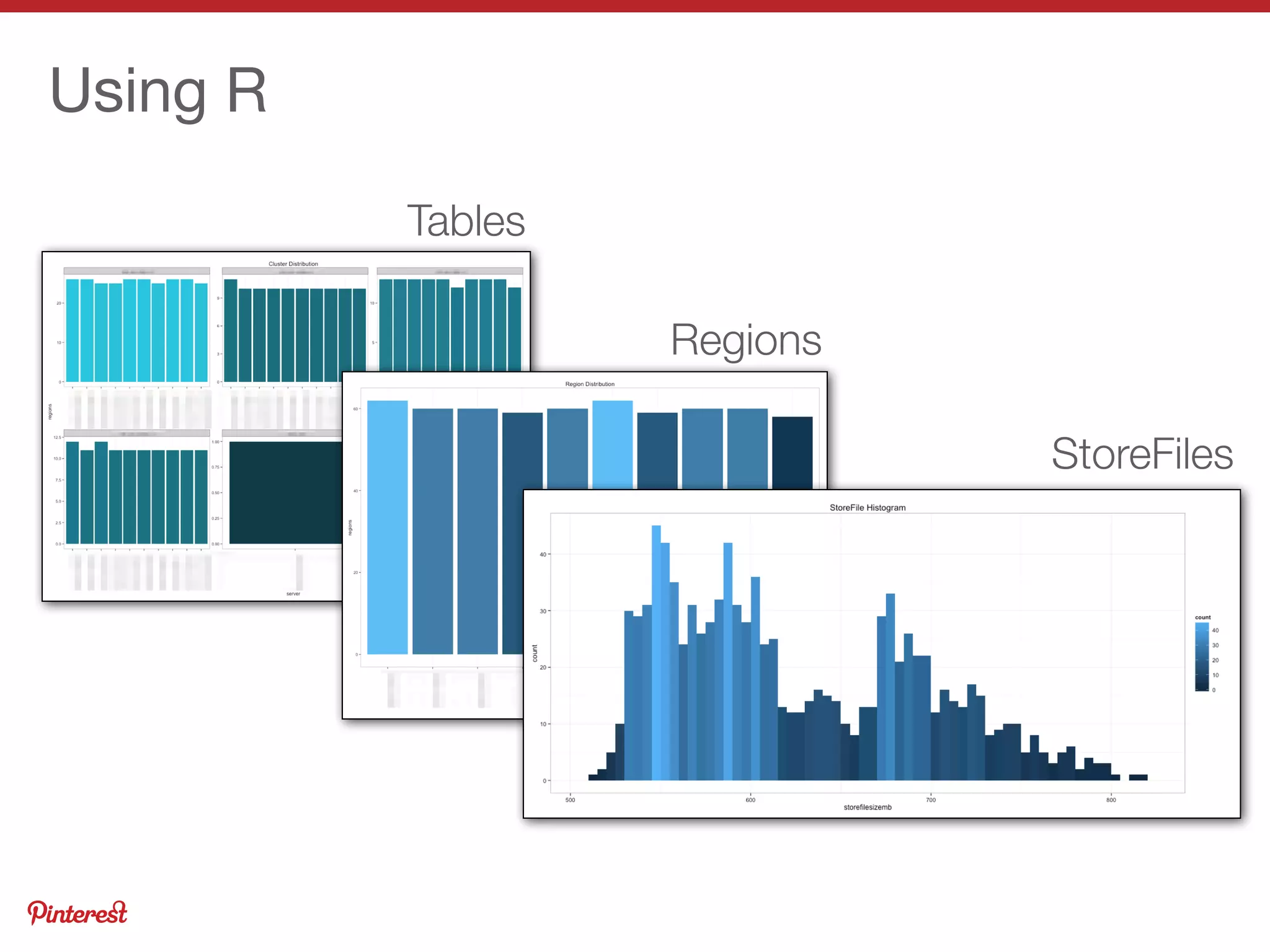

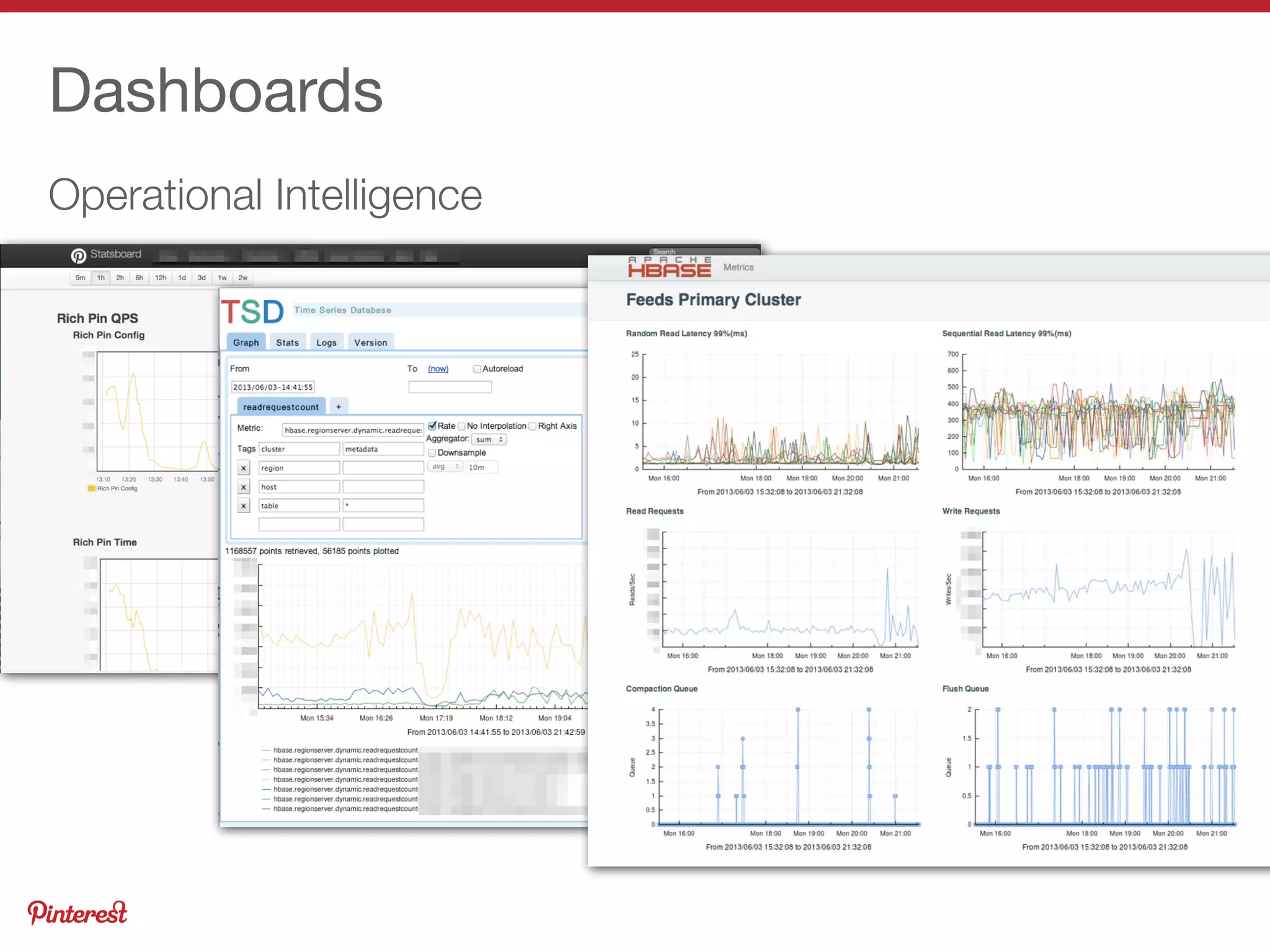
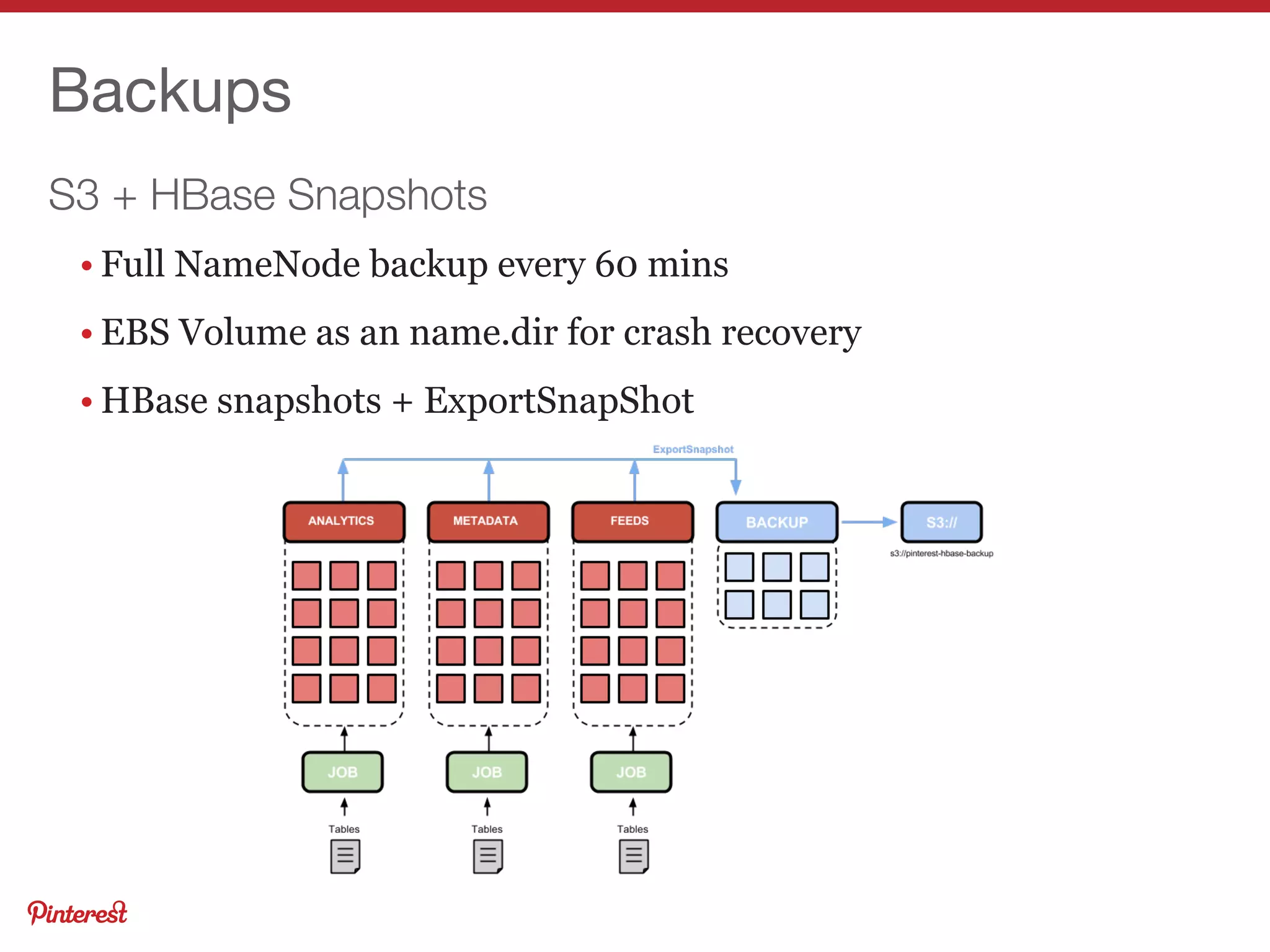




This document summarizes Jeremy Carroll's presentation on HBase operations at Amazon. It discusses how Amazon uses HBase across 5 clusters with billions of page views. Key points include: - HBase is deployed on Amazon Web Services using CDH and customized for EC2 instability and lack of rack locality - Puppet is used to provision nodes and apply custom HDFS and HBase configurations - Extensive monitoring of the clusters is done using OpenTSDB, Ganglia, and custom dashboards to ensure high availability - Various techniques are used to optimize performance, handle large volumes, and back up data on EC2 infrastructure.




























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














