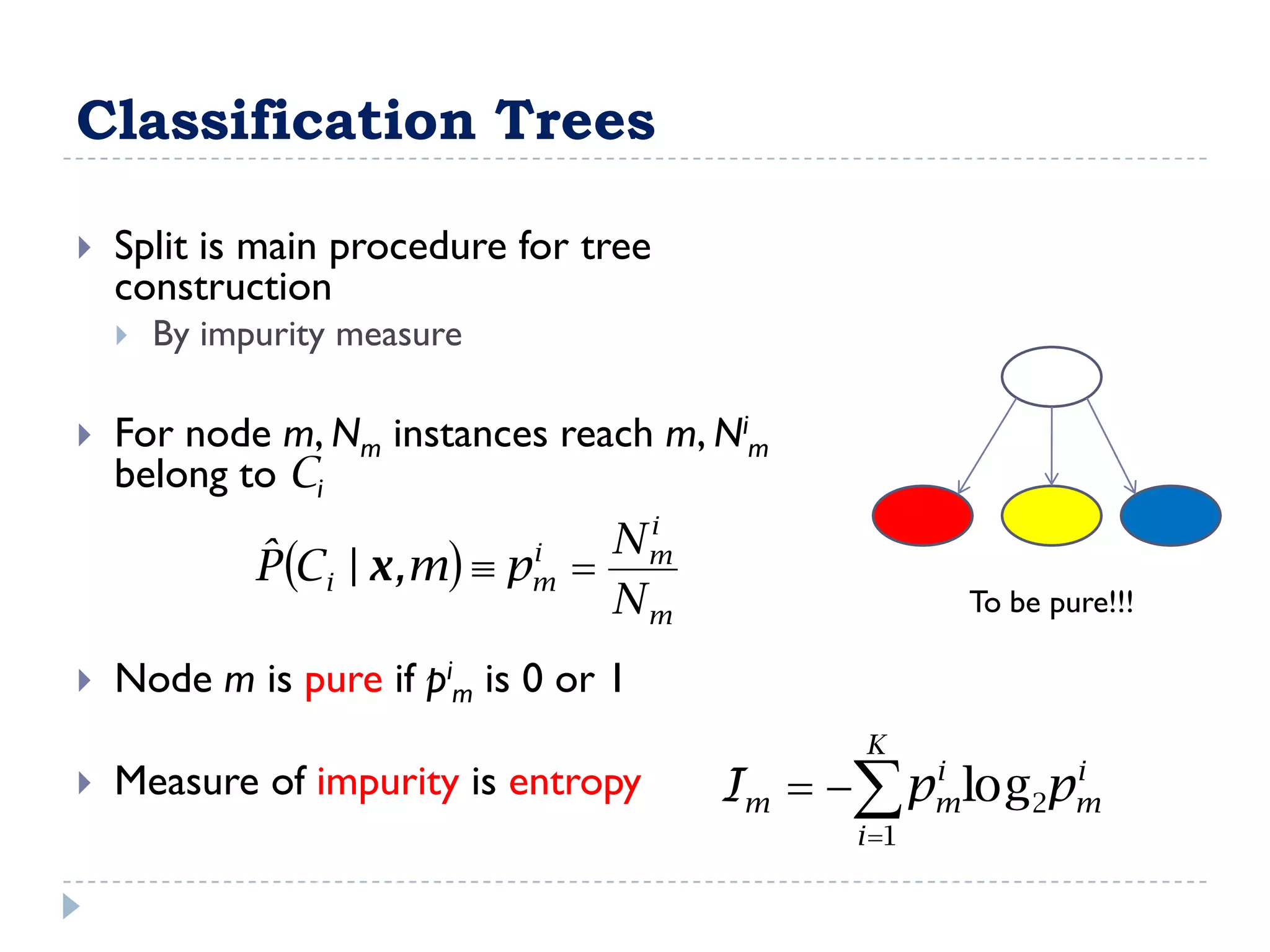
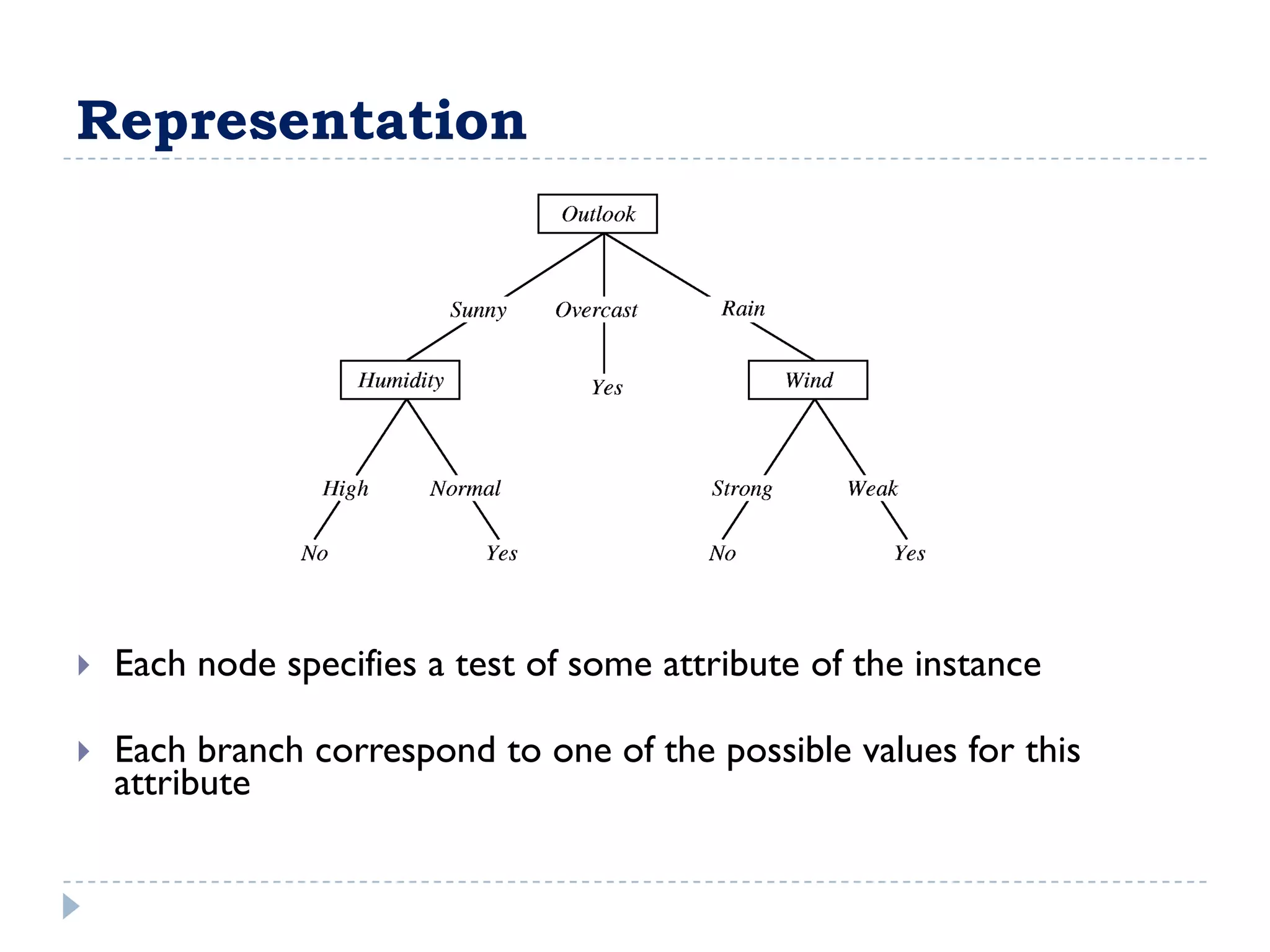
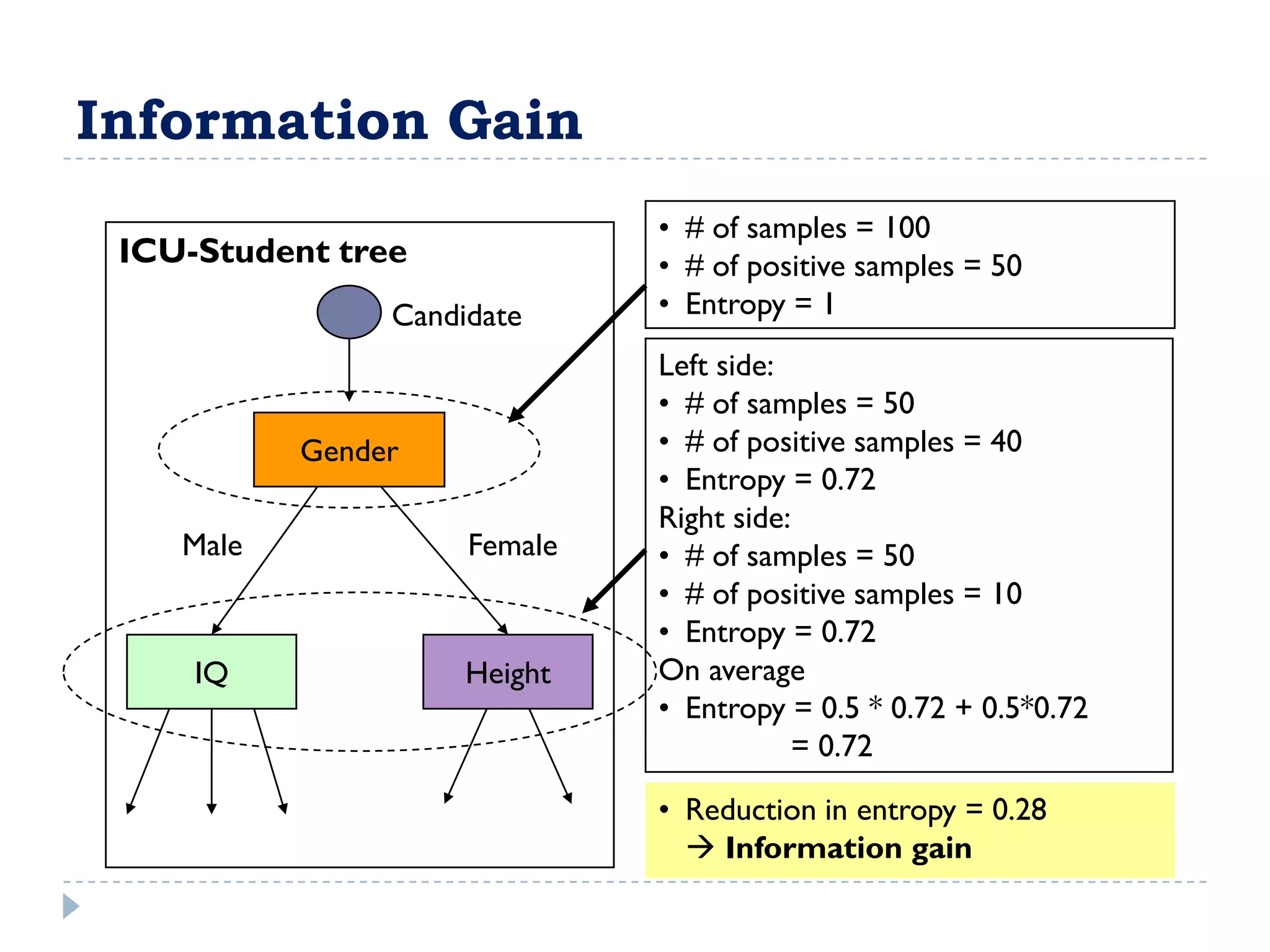
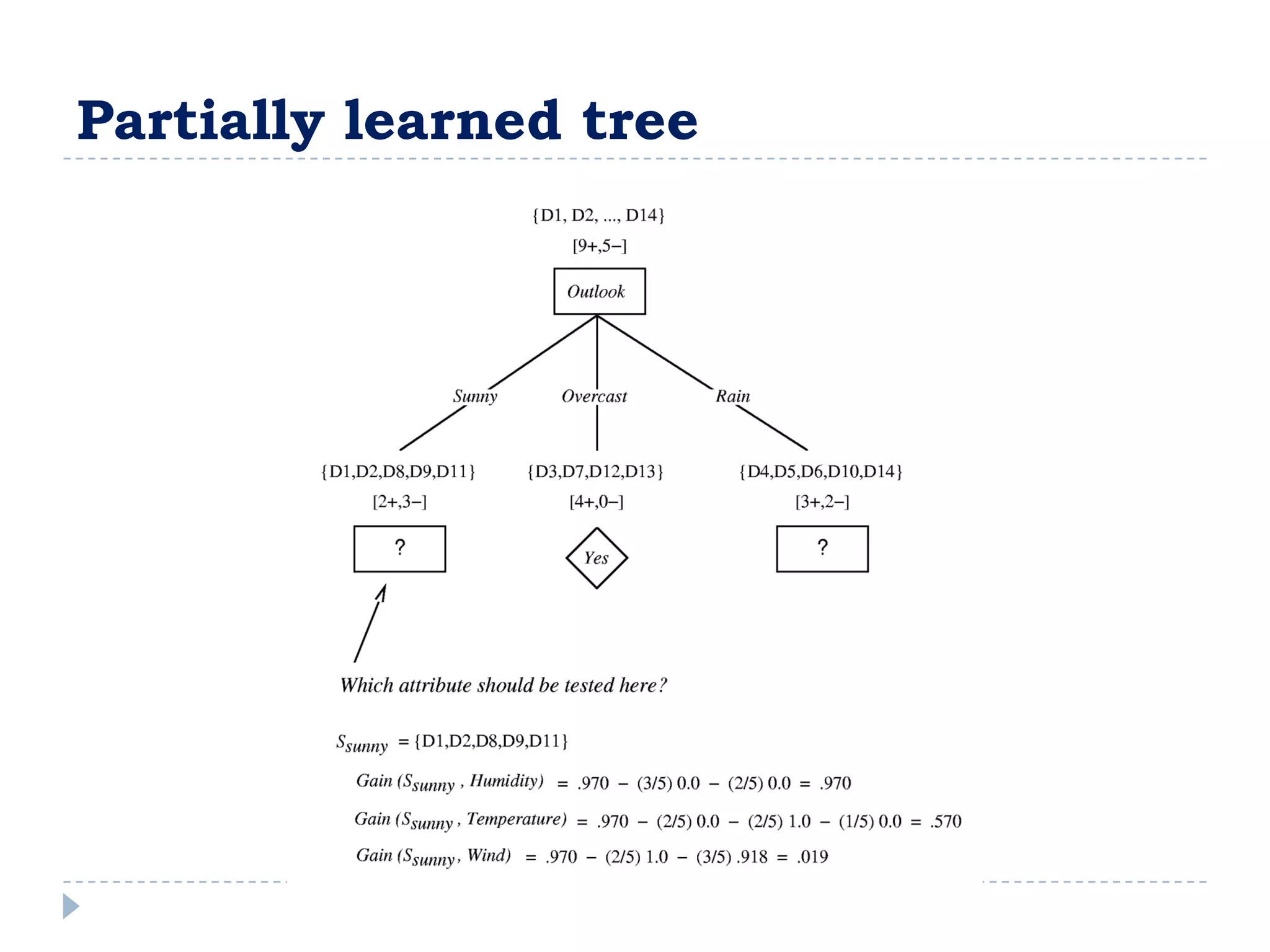
The attribute that should be tested at the root of the decision tree is the attribute that results in the maximum information gain, or minimum entropy, when used to split the training data. In other words, the attribute that best separates the data according to the target classes. This attribute will create "purer" nodes with respect to the target classes.







![Examples (2)
from a HW of Neural Networks Class (KAIST-2002)
Function approximation (Mexican hat)
f3 ( x1 , x2 ) sin 2 x12 x2 ,
2
x1 , x2 [1,1]](https://image.slidesharecdn.com/introduction-to-machine-learning2924/75/Introduction-to-Machine-Learning-10-2048.jpg)



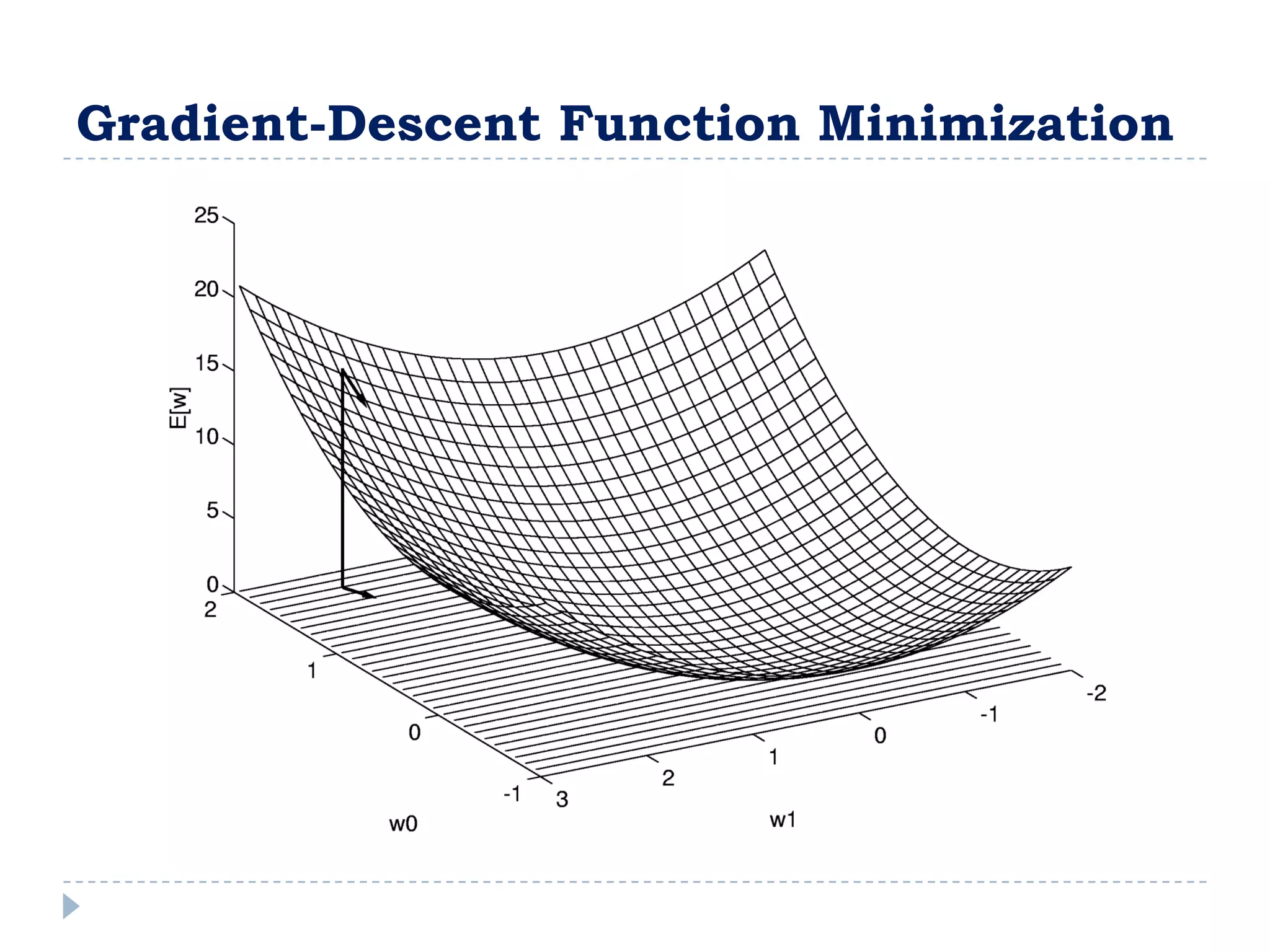

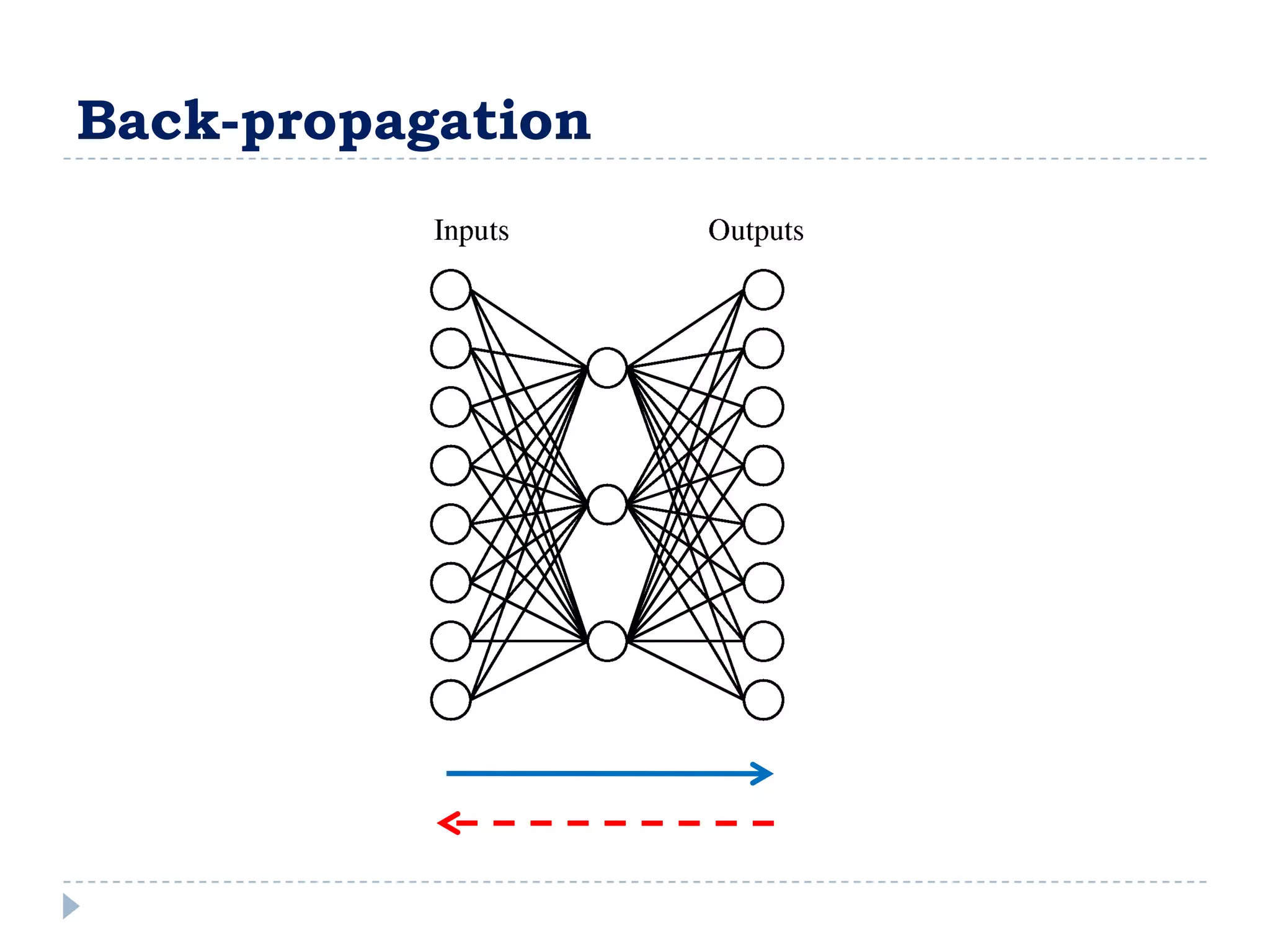



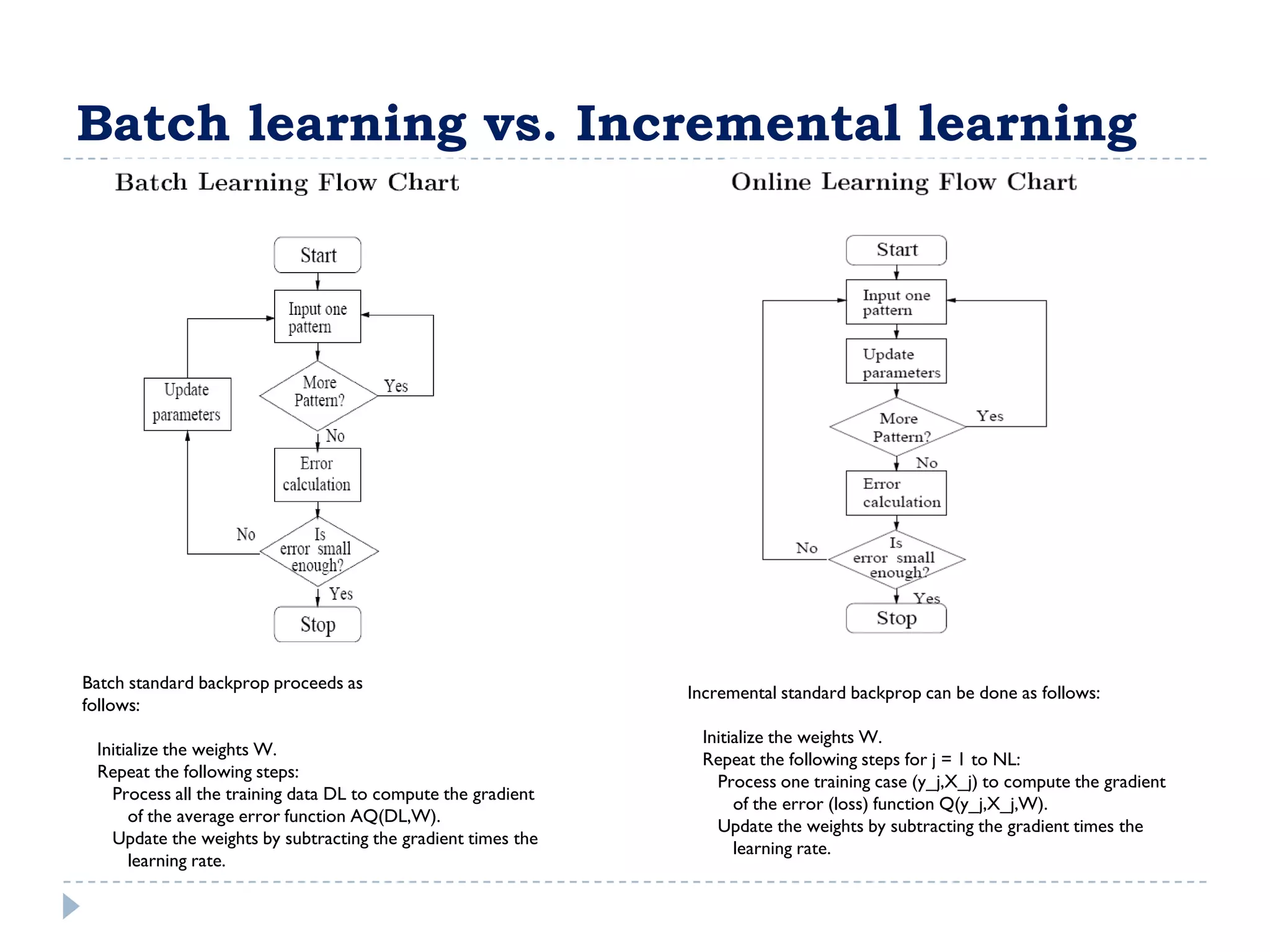

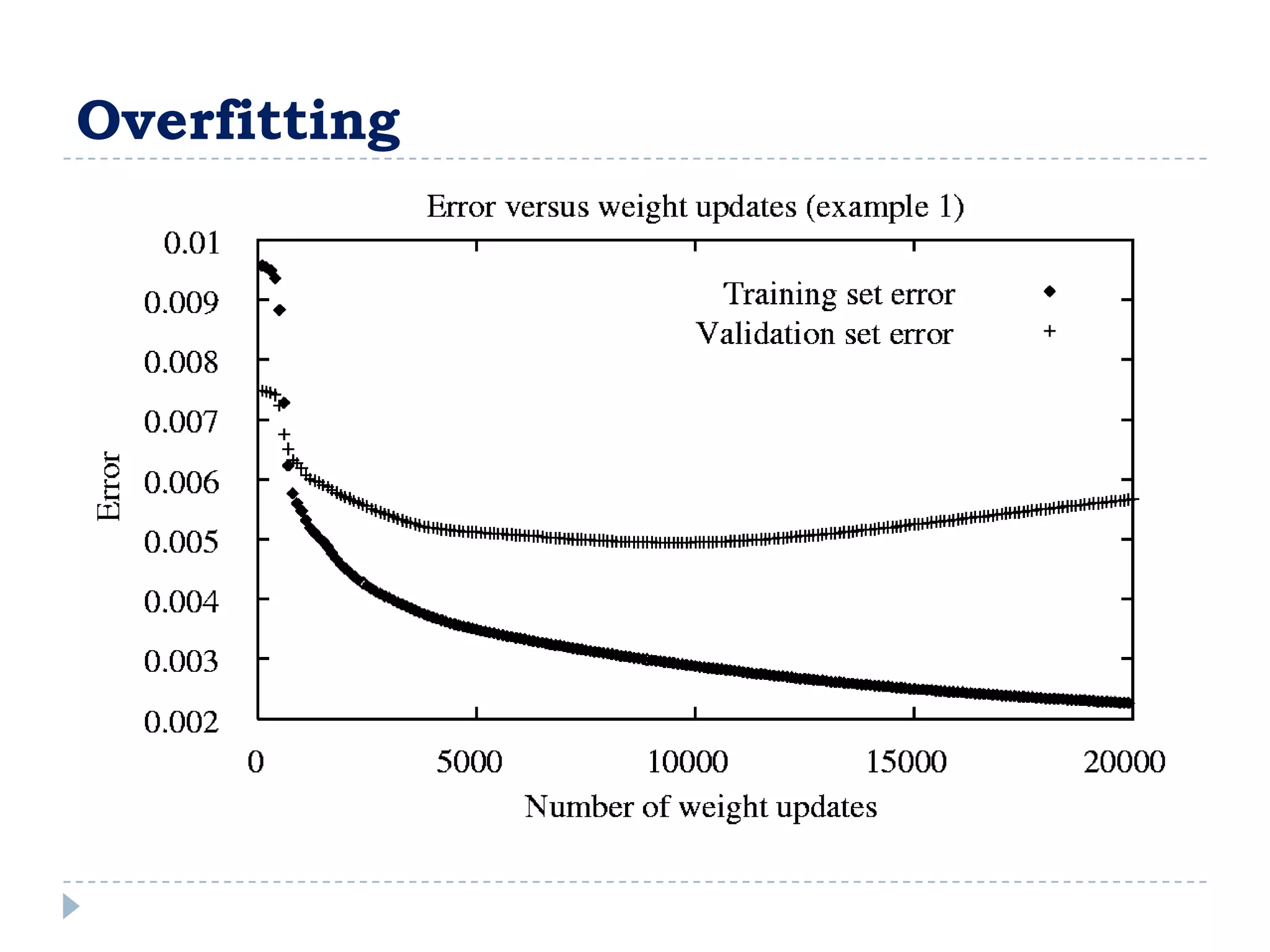





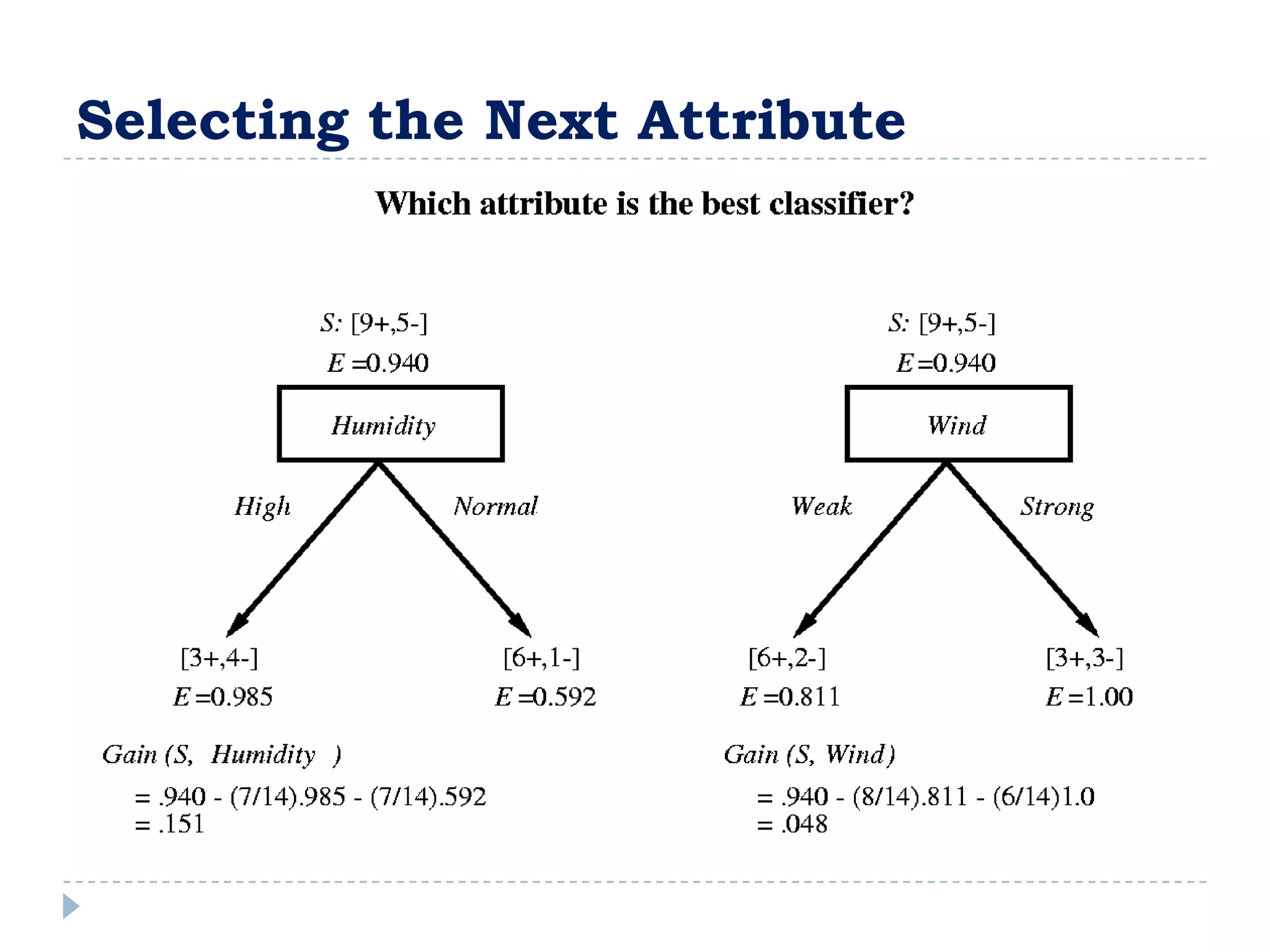
![Entropy
Example
14 examples
Entropy([9,5])
(9 /14) log 2 (9 /14) (5 /14) log 2 (5 /14) 0.940
Entropy 0 : all members positive or negative
Entropy 1 : equal number of positive & negative
0 < Entropy < 1 : unequal number of positive & negative](https://image.slidesharecdn.com/introduction-to-machine-learning2924/75/Introduction-to-Machine-Learning-37-2048.jpg)











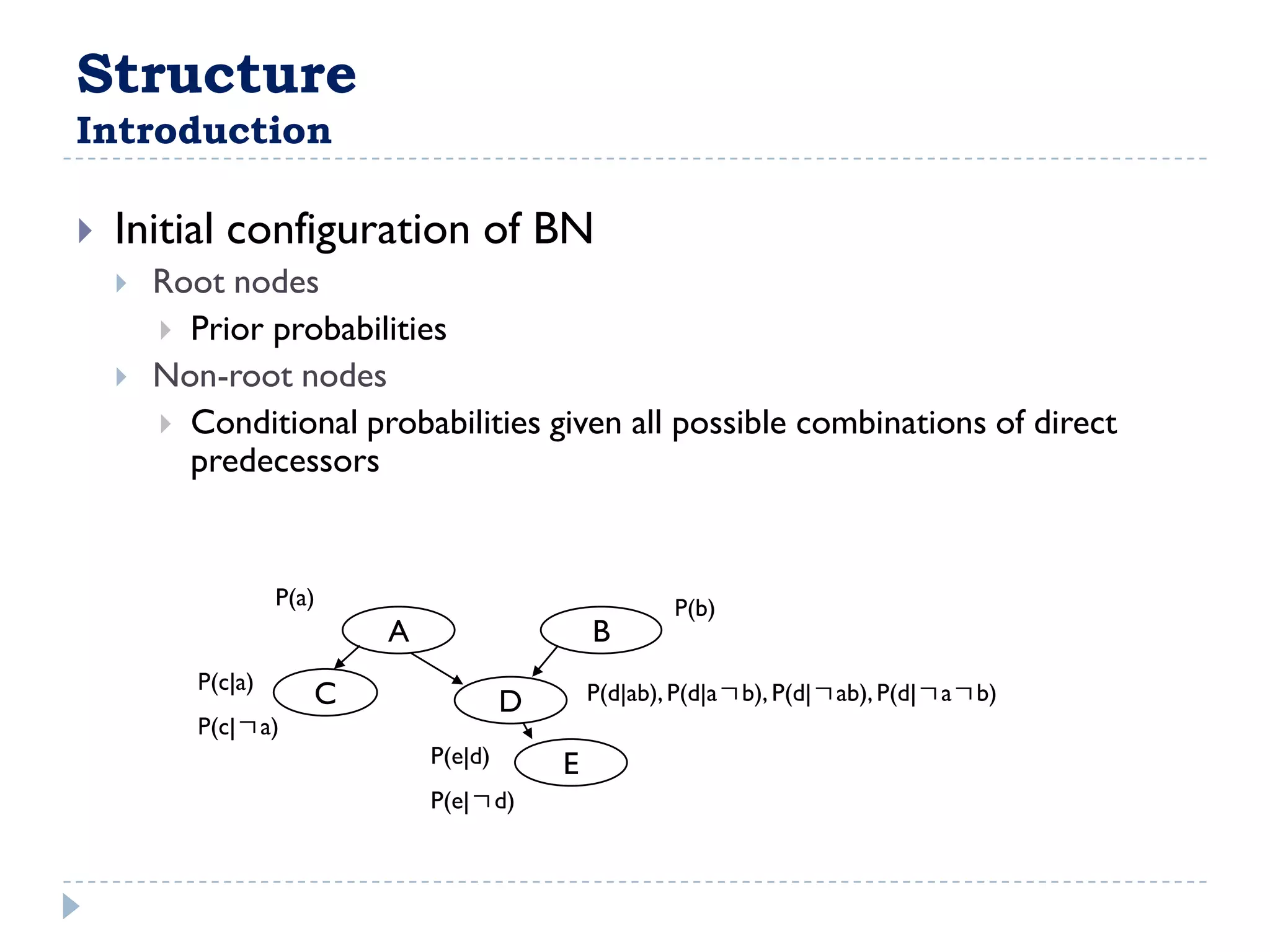
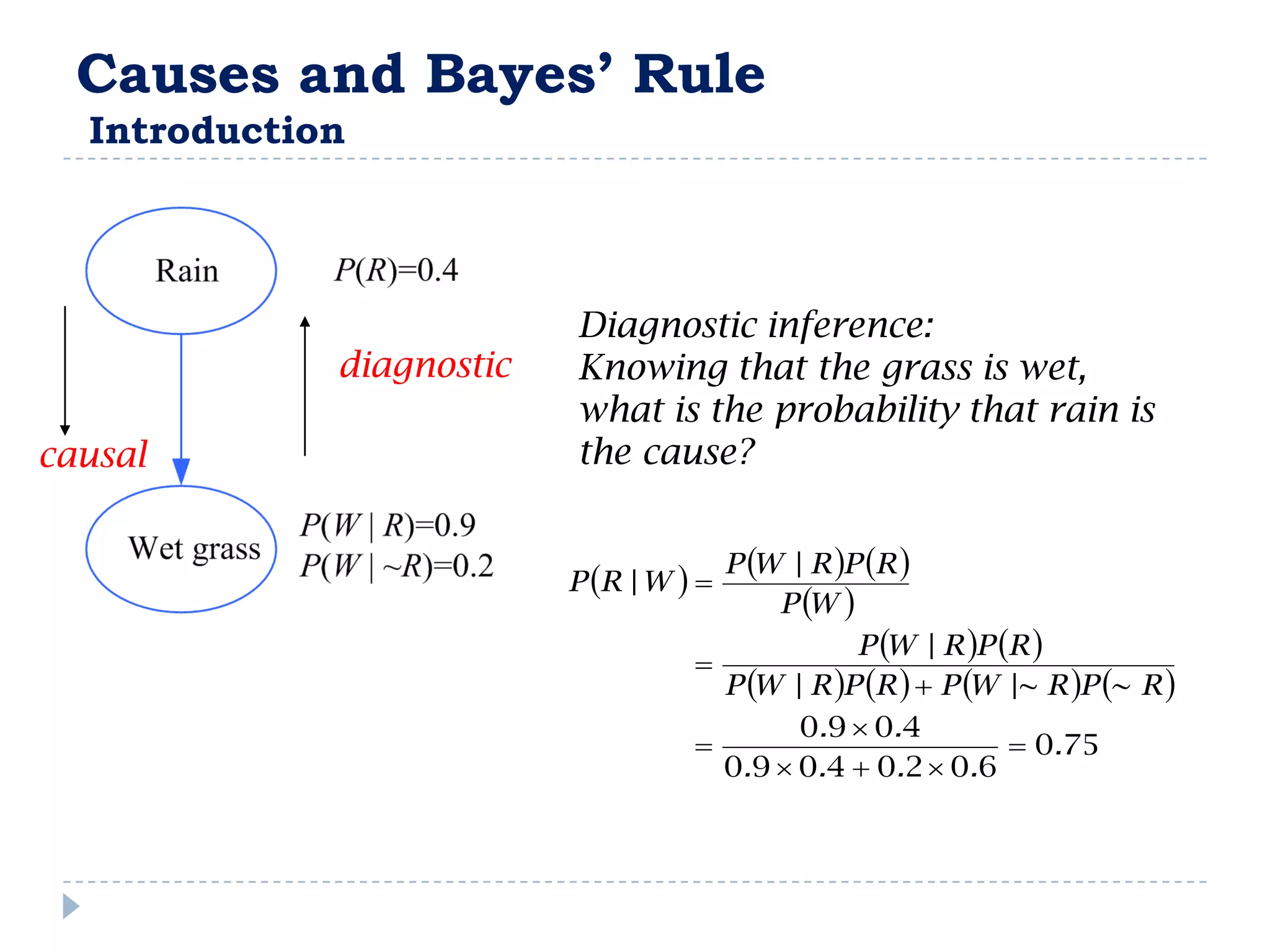

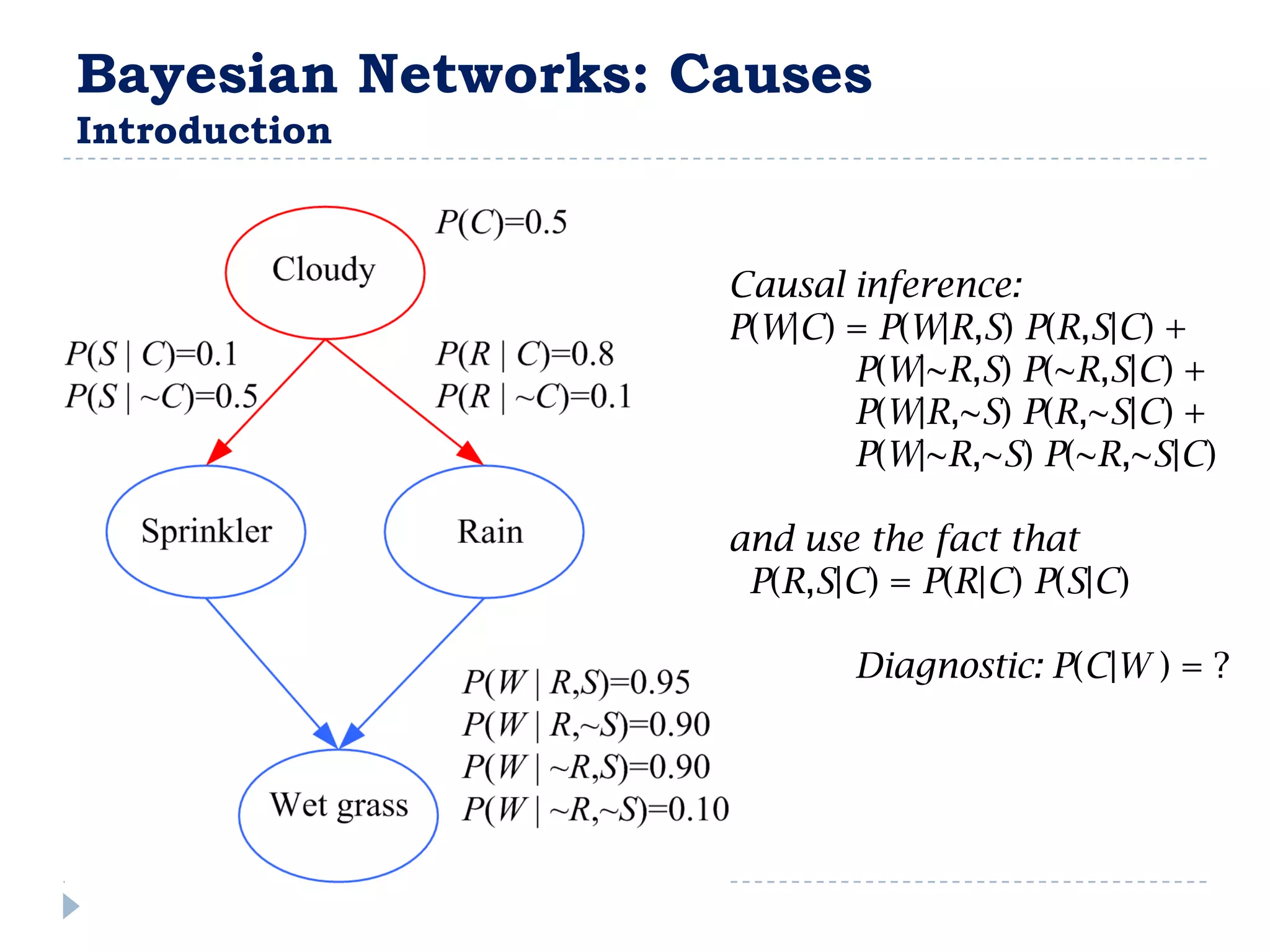
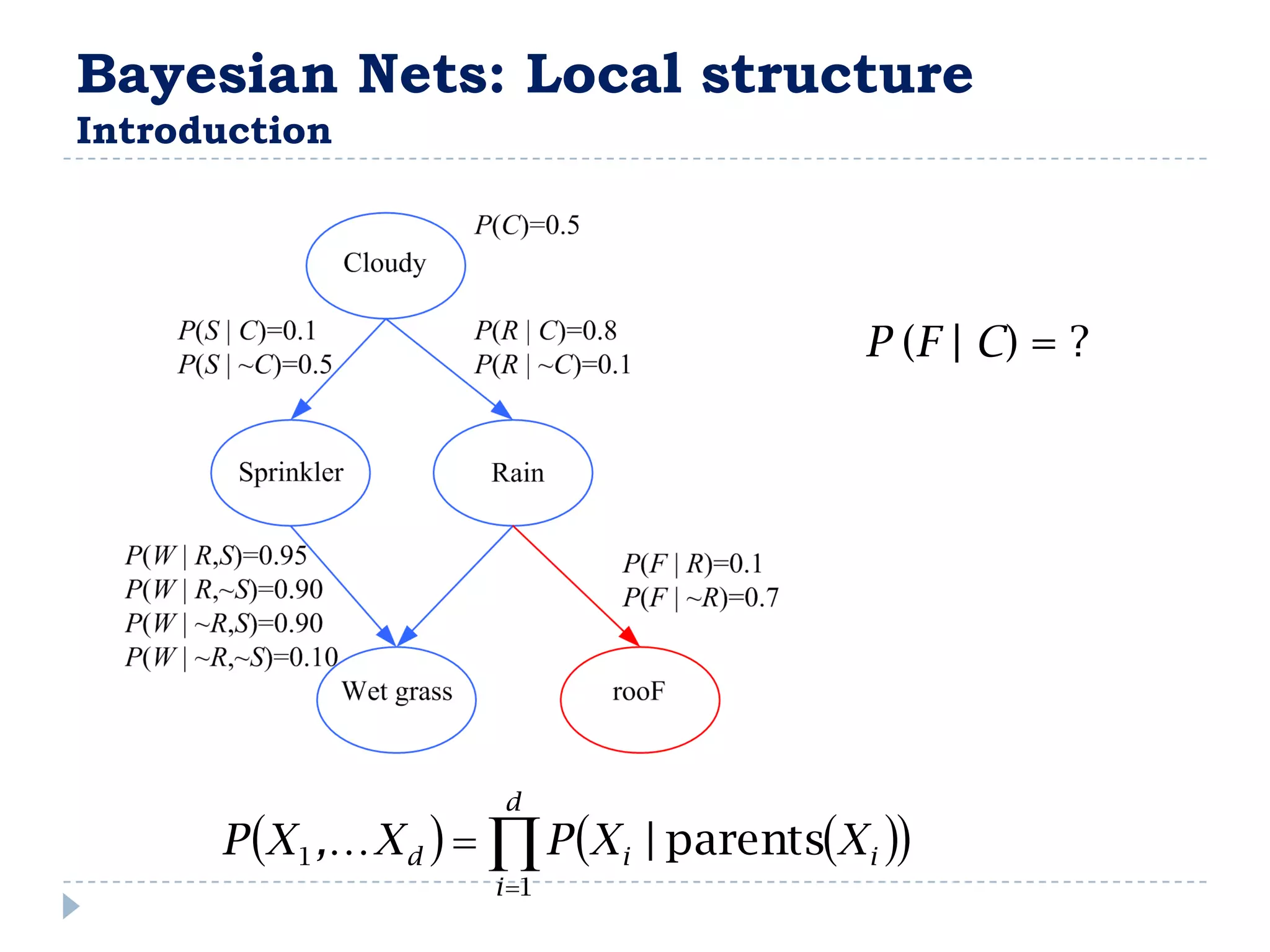

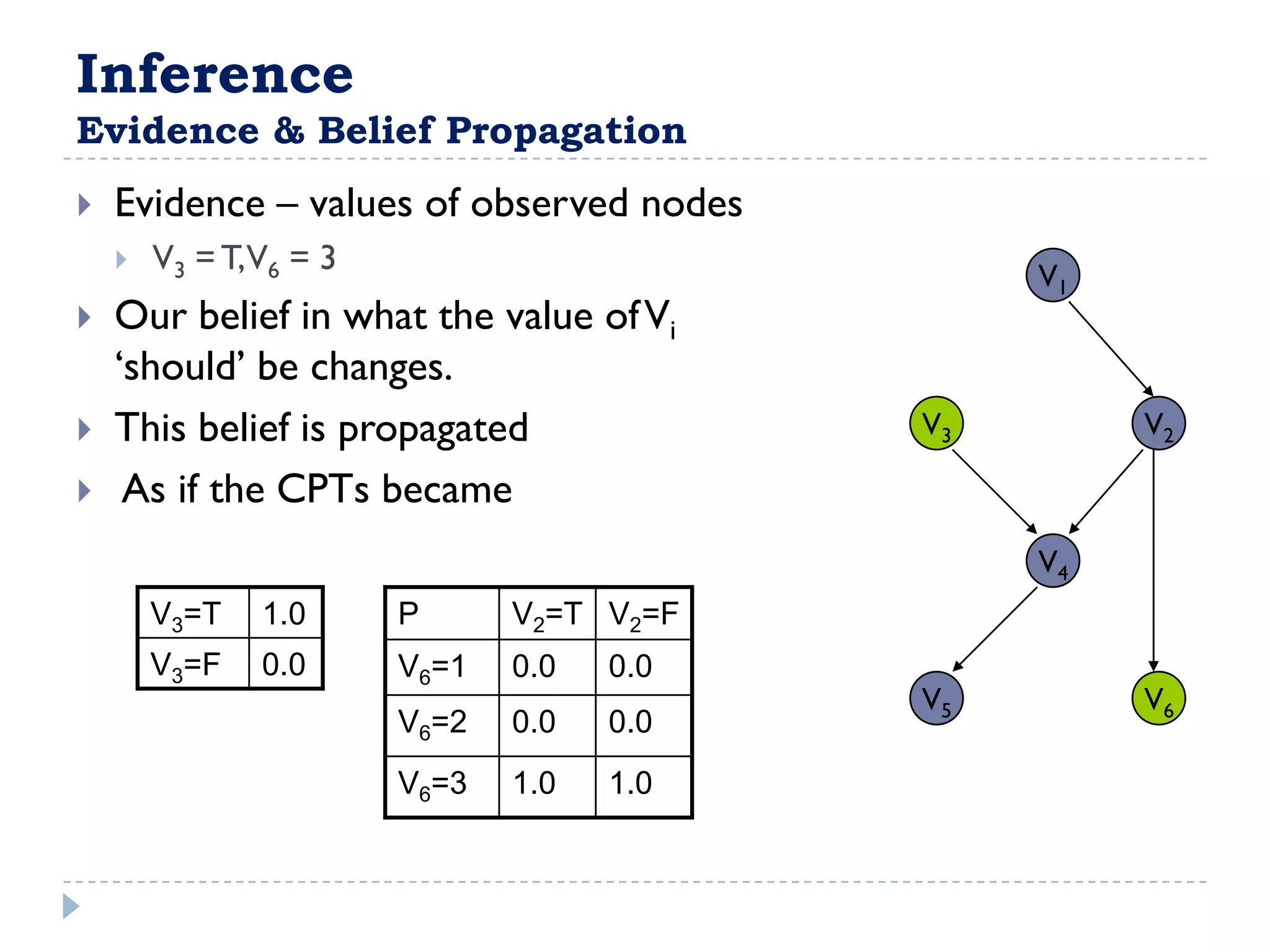
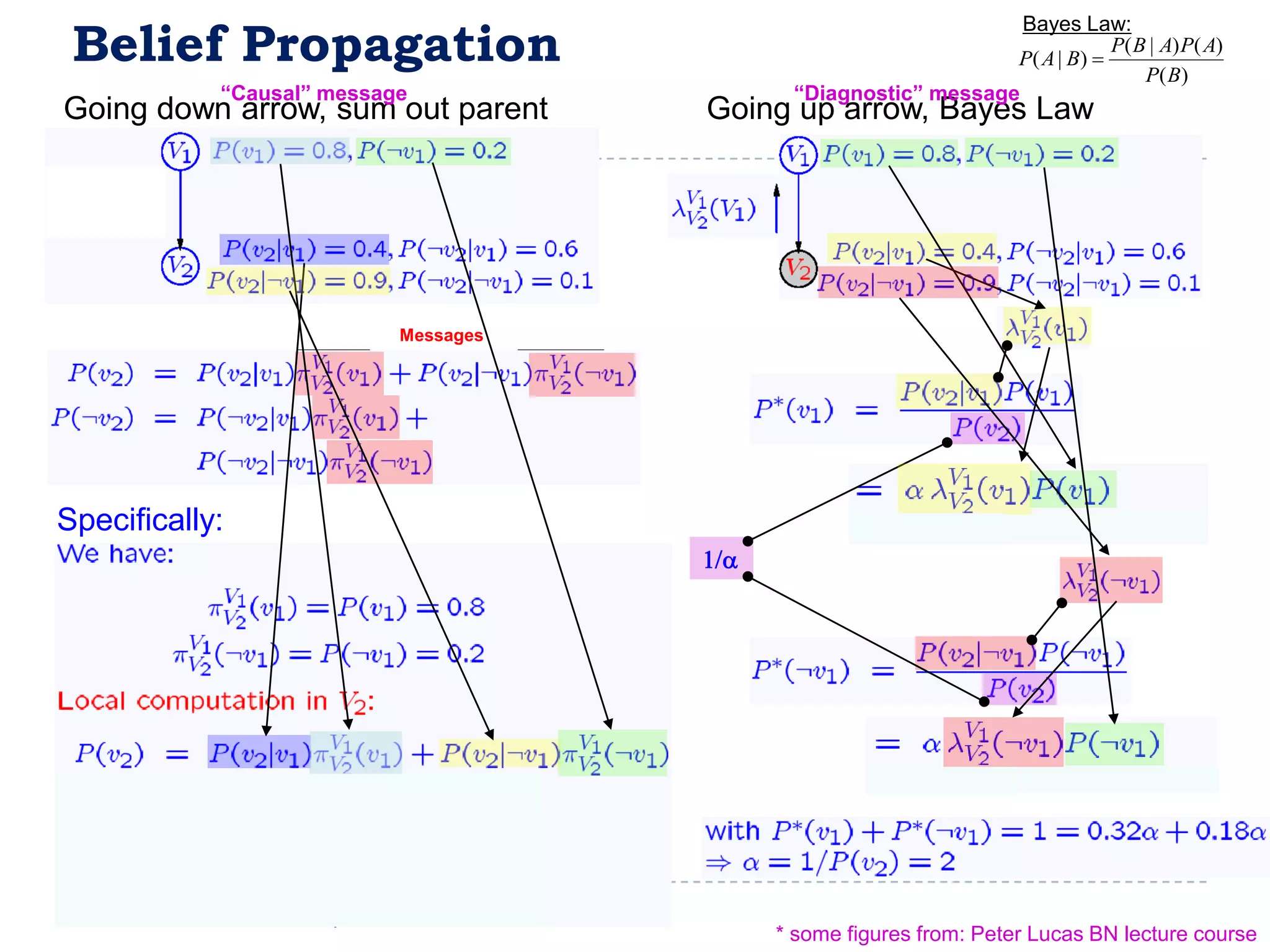
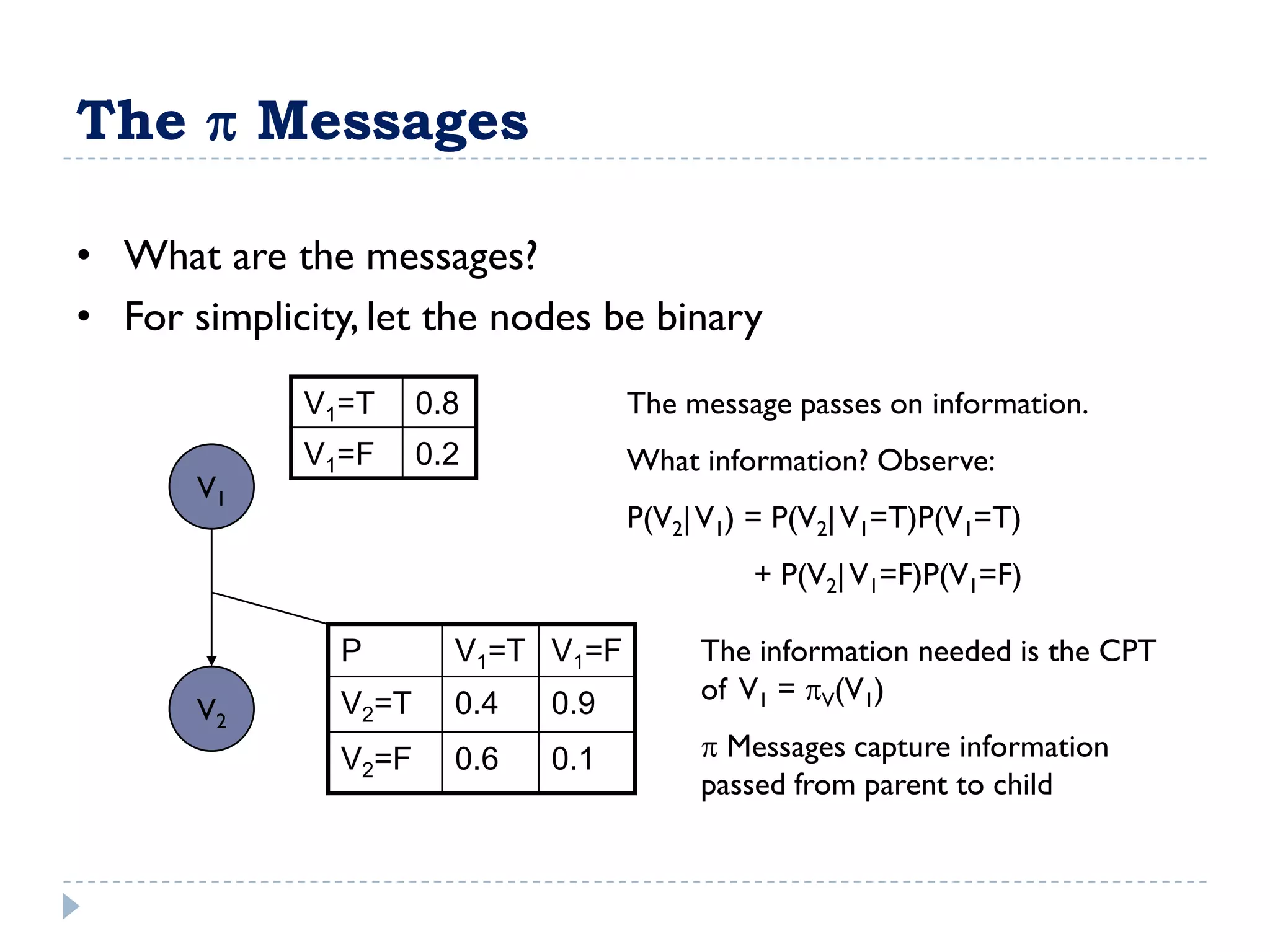

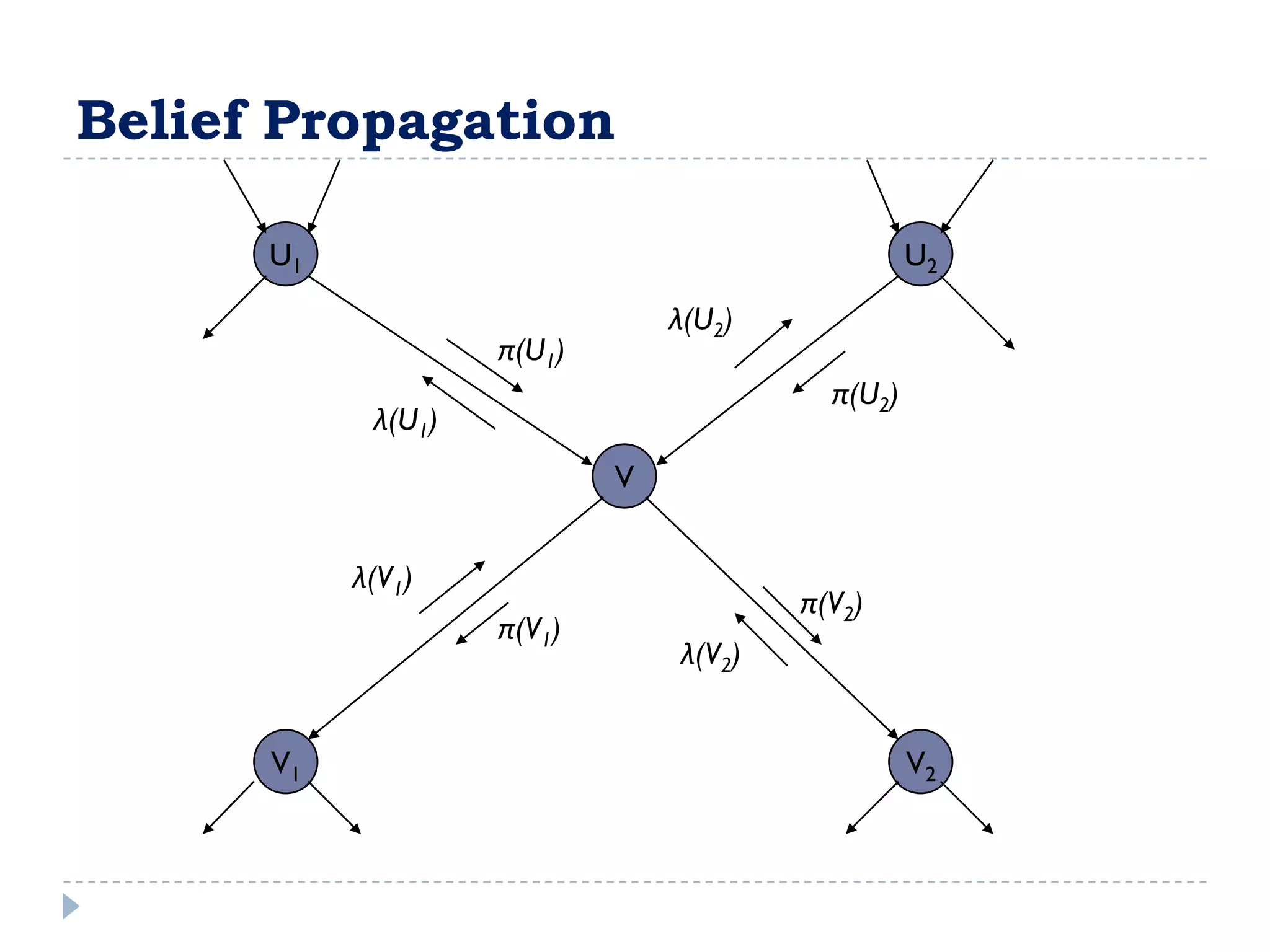
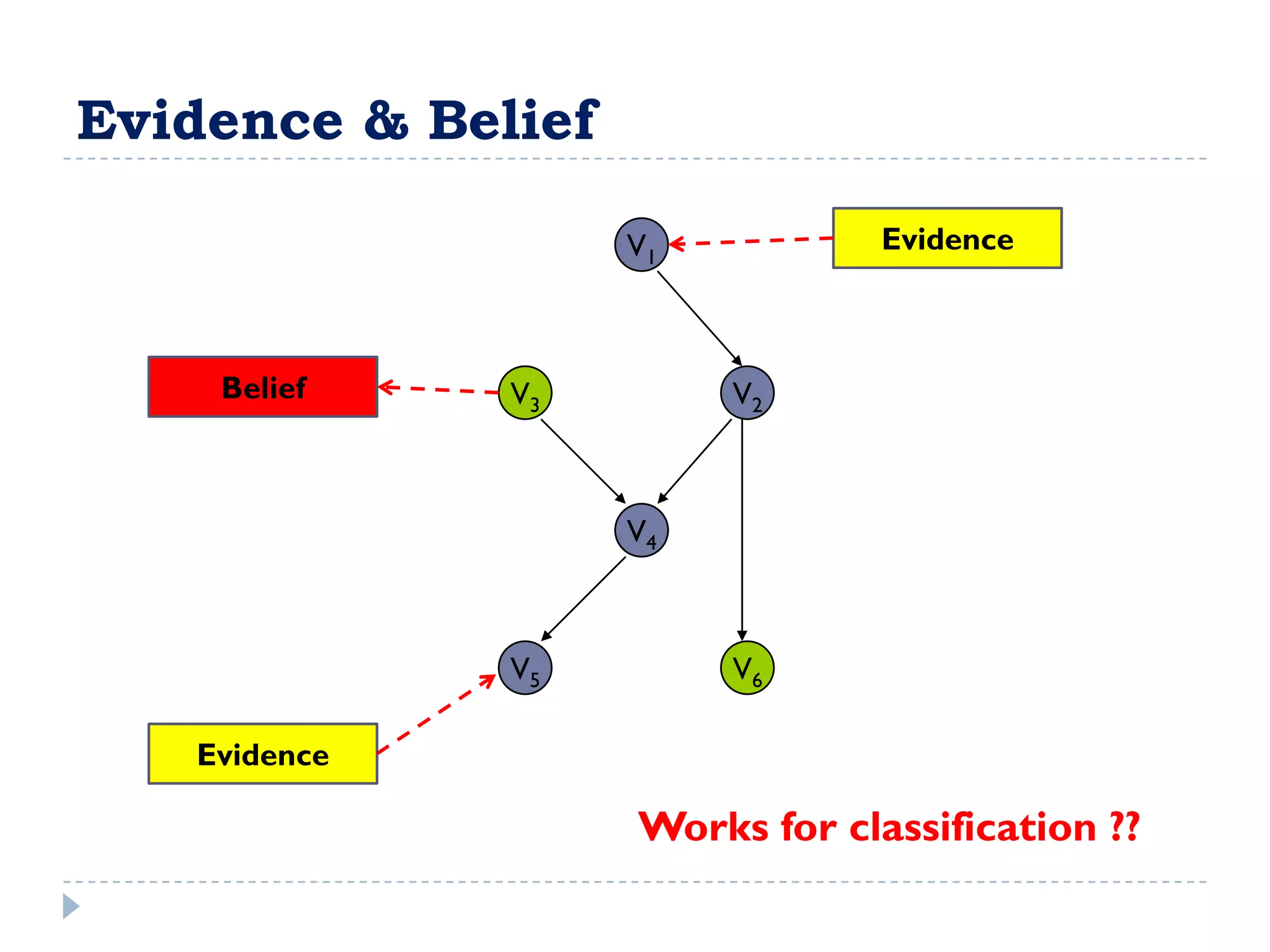
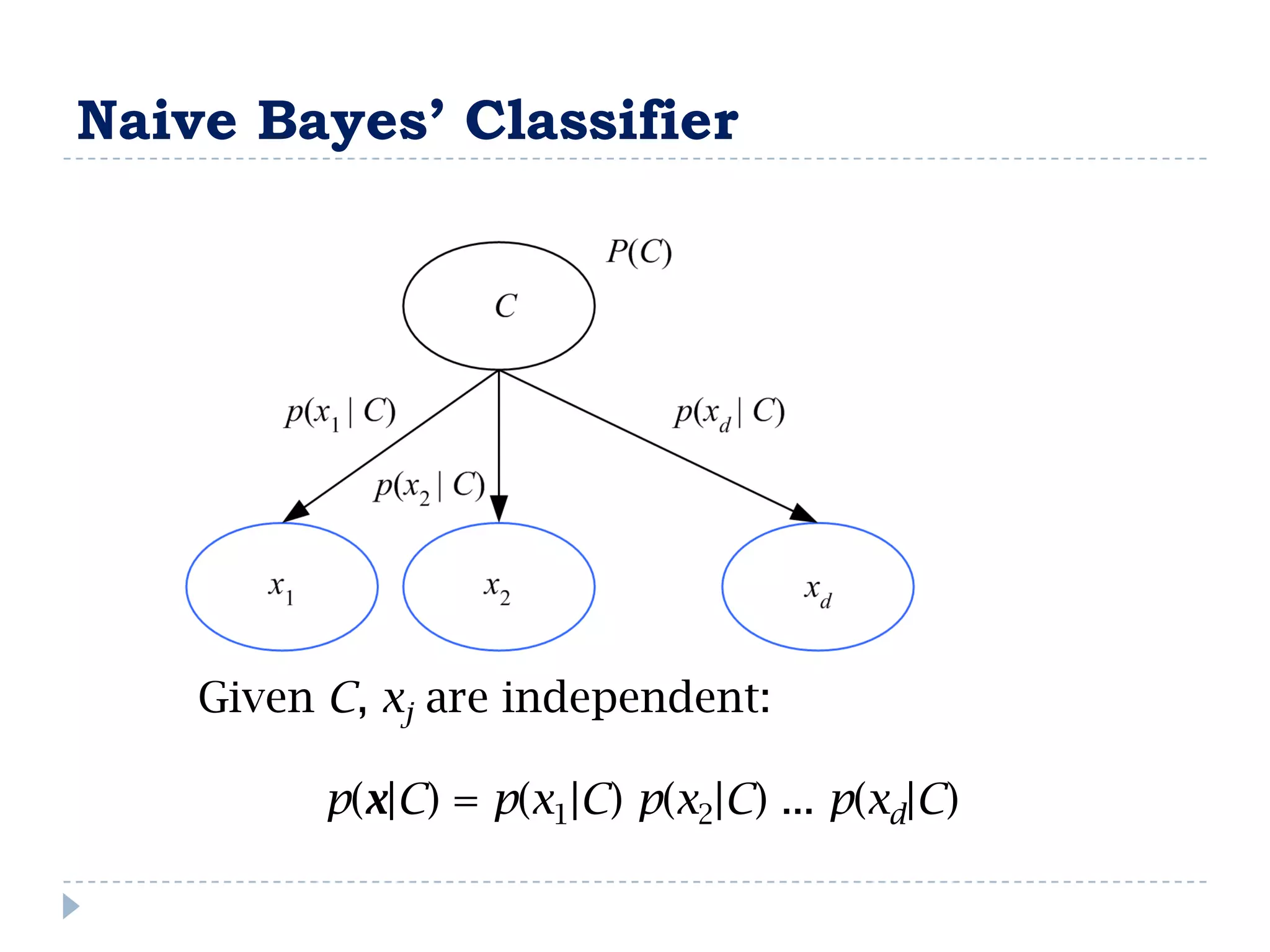



![FullBNT
clear all
N = 4; % 노드의 개수
dag = zeros(N,N); % 네크워크 구조 shell
C = 1; S = 2; R = 3; W = 4; % 각 노드 Naming
dag(C,[R S]) = 1; % 네트워크 구조 명시
dag(R,W) = 1;
dag(S,W)=1;
%discrete_nodes = 1:N;
node_sizes = 2*ones(1,N); % 각 노드가 가질 수 있는 값의 개수
%node_sizes = [4 2 3 5];
%onodes = [];
%bnet = mk_bnet(dag, node_sizes, 'discrete', discrete_nodes, 'observed', onodes);
bnet = mk_bnet(dag, node_sizes, 'names', {'C','S','R','W'}, 'discrete', 1:4);
%C = bnet.names('cloudy'); % bnet.names is an associative array
%bnet.CPD{C} = tabular_CPD(bnet, C, [0.5 0.5]);
%%%%%% Specified Parameters
%bnet.CPD{C} = tabular_CPD(bnet, C, [0.5 0.5]);
%bnet.CPD{R} = tabular_CPD(bnet, R, [0.8 0.2 0.2 0.8]);
%bnet.CPD{S} = tabular_CPD(bnet, S, [0.5 0.9 0.5 0.1]);
%bnet.CPD{W} = tabular_CPD(bnet, W, [1 0.1 0.1 0.01 0 0.9 0.9 0.99]);](https://image.slidesharecdn.com/introduction-to-machine-learning2924/75/Introduction-to-Machine-Learning-68-2048.jpg)










































![[Harvard CS264] 09 - Machine Learning on Big Data: Lessons Learned from Googl...](https://cdn.slidesharecdn.com/ss_thumbnails/machinelearningbigdata-maxlin-cs264opt-110331195757-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
































