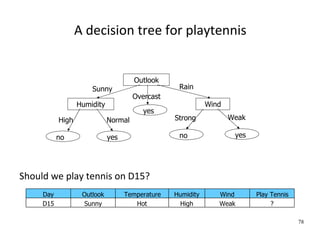
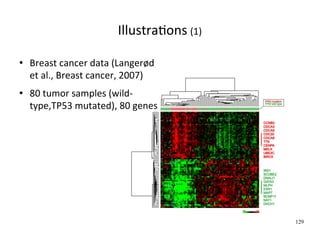
This document provides an introduction to machine learning. It defines machine learning as developing algorithms that allow computers to learn from experience to improve their performance on tasks. The document outlines supervised learning and other learning frameworks. It discusses applications of machine learning such as autonomous vehicles, recommendation systems, and credit risk analysis. The document also provides examples of machine learning applications at the University of Liege including medical diagnosis, gene expression analysis, and patient classification.




![ApplicaWons: autonomous driving
DARPA Grand challenge 2005: build a robot capable of
navigaWng 240 km through desert terrain in less than 10
hours, with no human intervenWon
The actual wining Wme of Stanley [Thrun et al., 05] was 6
hours 54 minutes.
http://www.darpa.mil/grandchallenge/ 5](https://image.slidesharecdn.com/an-introduc-on-to-machine-learning1339/85/An-introduc-on-to-Machine-Learning-5-320.jpg)














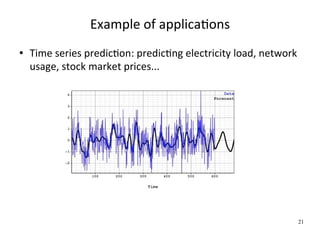
![Example of applicaWons
Perceptual tasks: handwriXen character recogniWon,
speech recogniWon...
Inputs:
● a grey intensity [0,255] for
each pixel
● each image is
represented by a vector of
pixel intensities
● eg.: 32x32=1024
dimensions
Output:
● 9 discrete values
● Y={0,1,2,...,9}
20](https://image.slidesharecdn.com/an-introduc-on-to-machine-learning1339/85/An-introduc-on-to-Machine-Learning-20-320.jpg)























































![Which aXribute is best ?
A1=? [29+,35-] A2=? [29+,35-]
T F T F
[21+,5-] [8+,30-] [18+,33-] [11+,2-]
A “score” measure is defined to evaluate splits
This score should favor class separaWon at each step (to shorten
the tree depth)
Common score measures are based on informaWon theory
I (LS, A) H( LS) | LS left | H(LS left ) | LSright | H(LS right)
| LS | | LS | 81](https://image.slidesharecdn.com/an-introduc-on-to-machine-learning1339/85/An-introduc-on-to-Machine-Learning-81-320.jpg)








































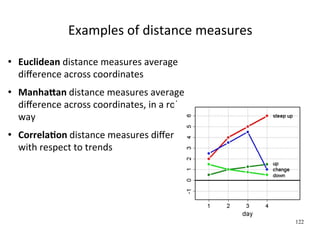
![Comparison of the distances
All distances are normalized to the interval
[0,10] and then rounded
123](https://image.slidesharecdn.com/an-introduc-on-to-machine-learning1339/85/An-introduc-on-to-Machine-Learning-123-320.jpg)






























![[Harvard CS264] 09 - Machine Learning on Big Data: Lessons Learned from Googl...](https://cdn.slidesharecdn.com/ss_thumbnails/machinelearningbigdata-maxlin-cs264opt-110331195757-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)










































