Downloaded 23 times


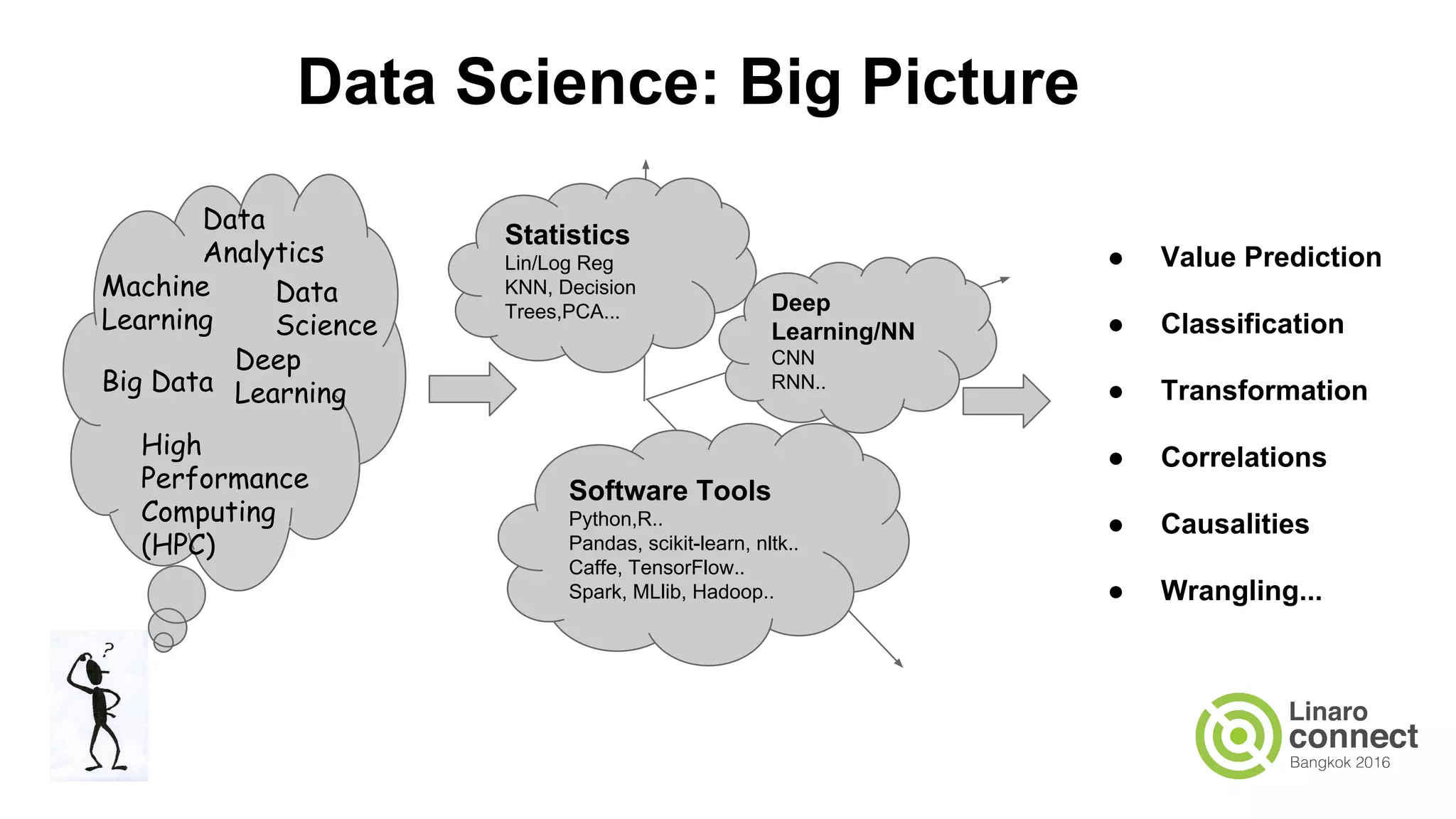



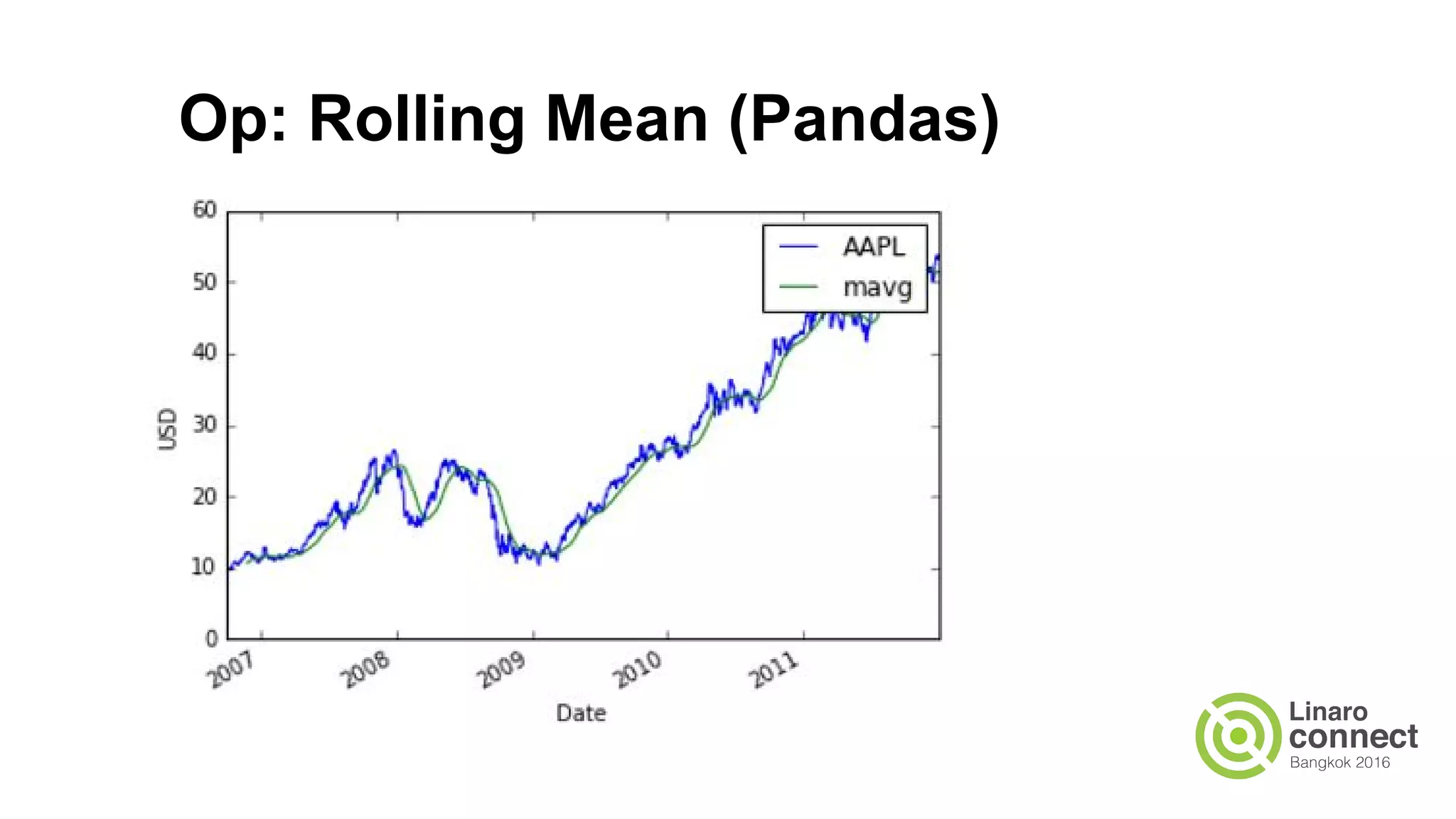
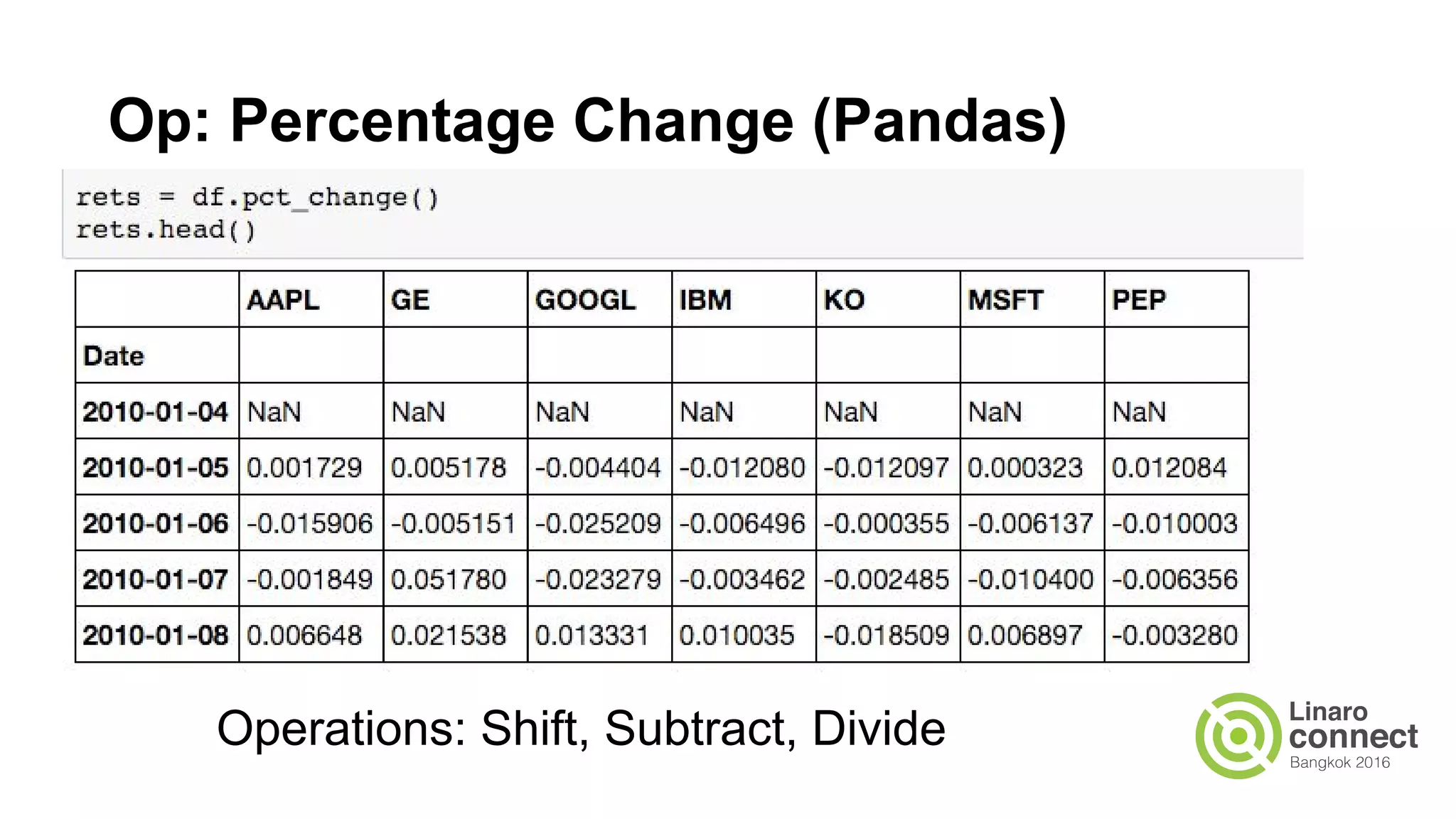
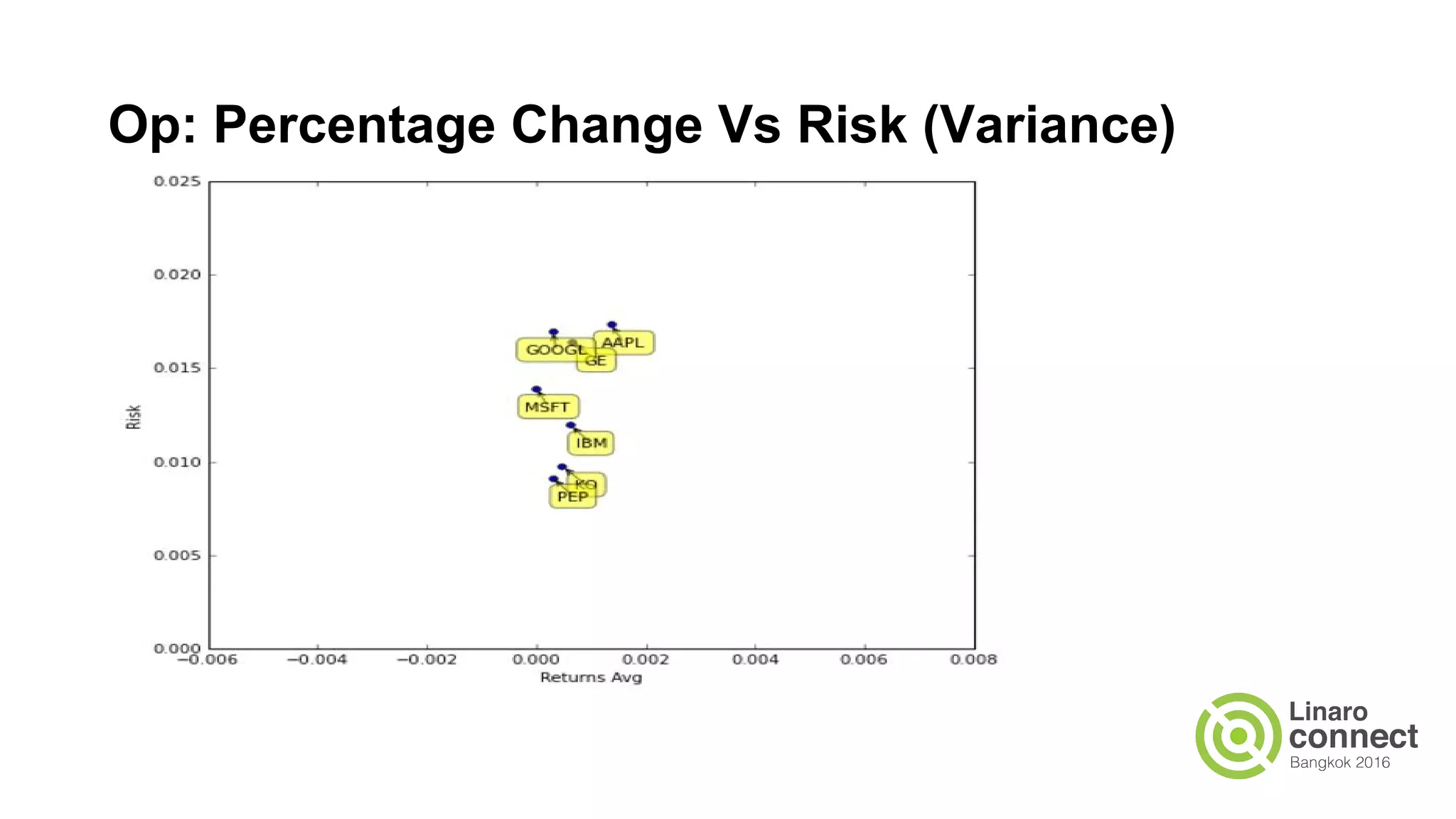
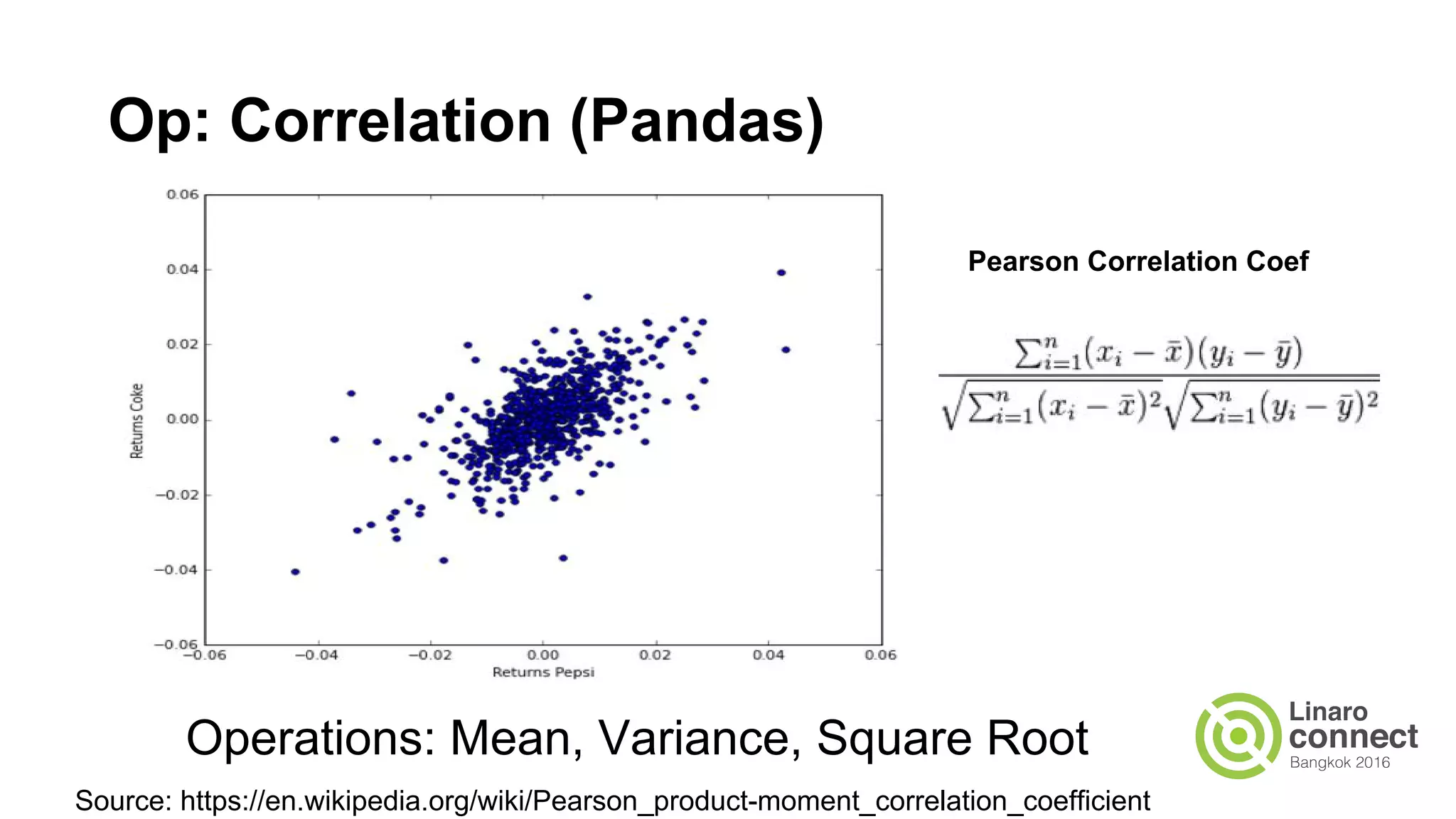
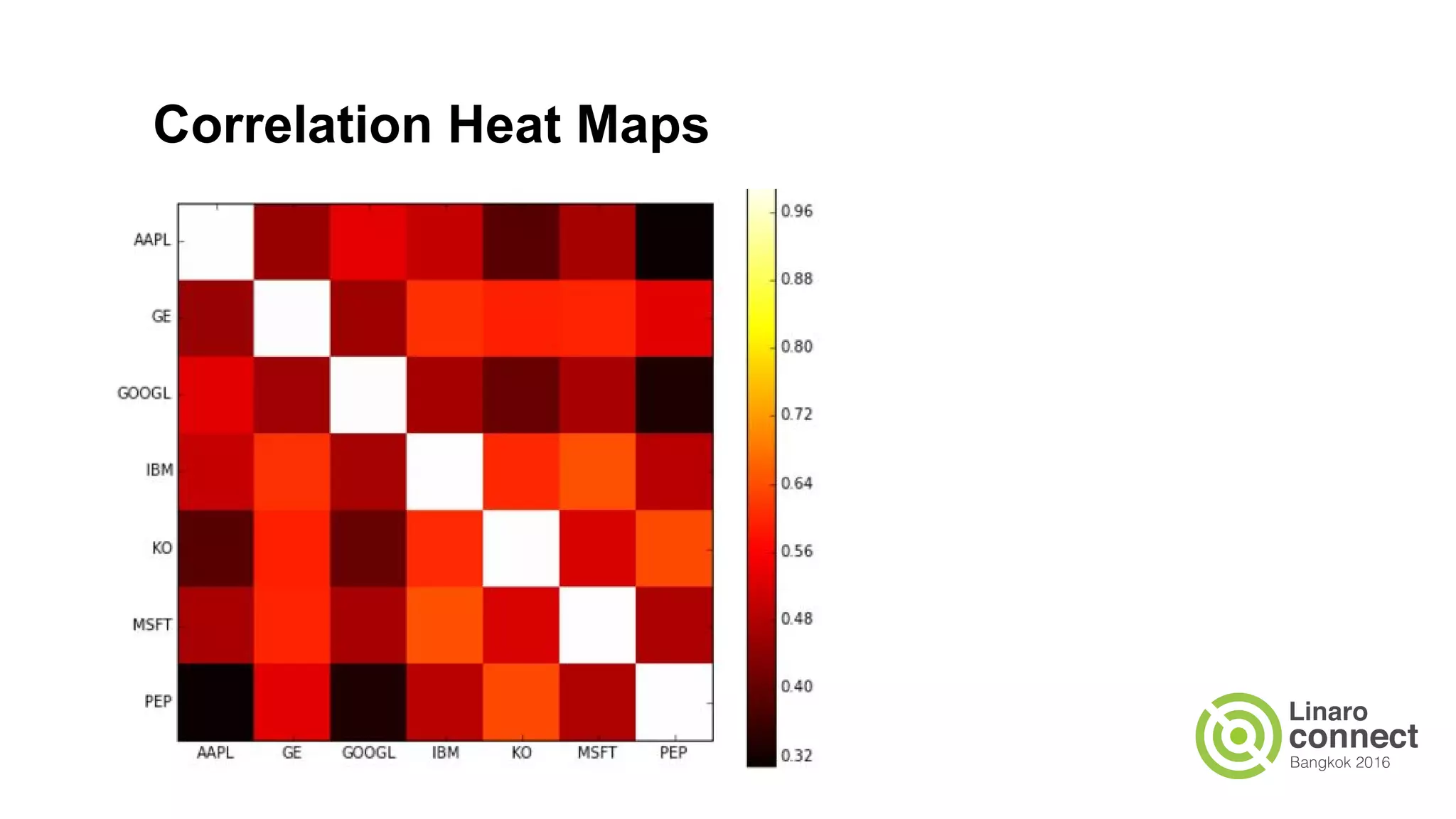
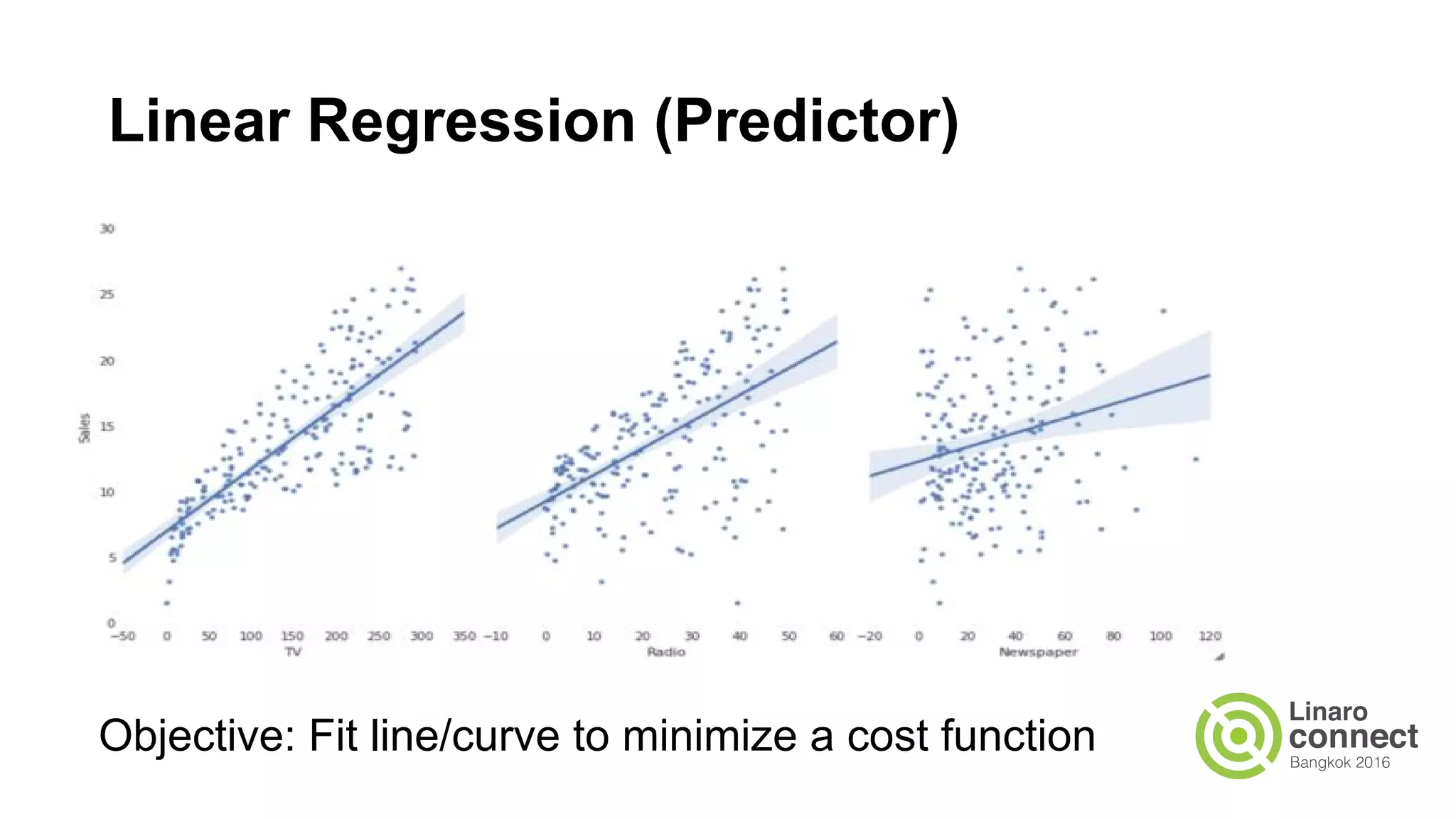
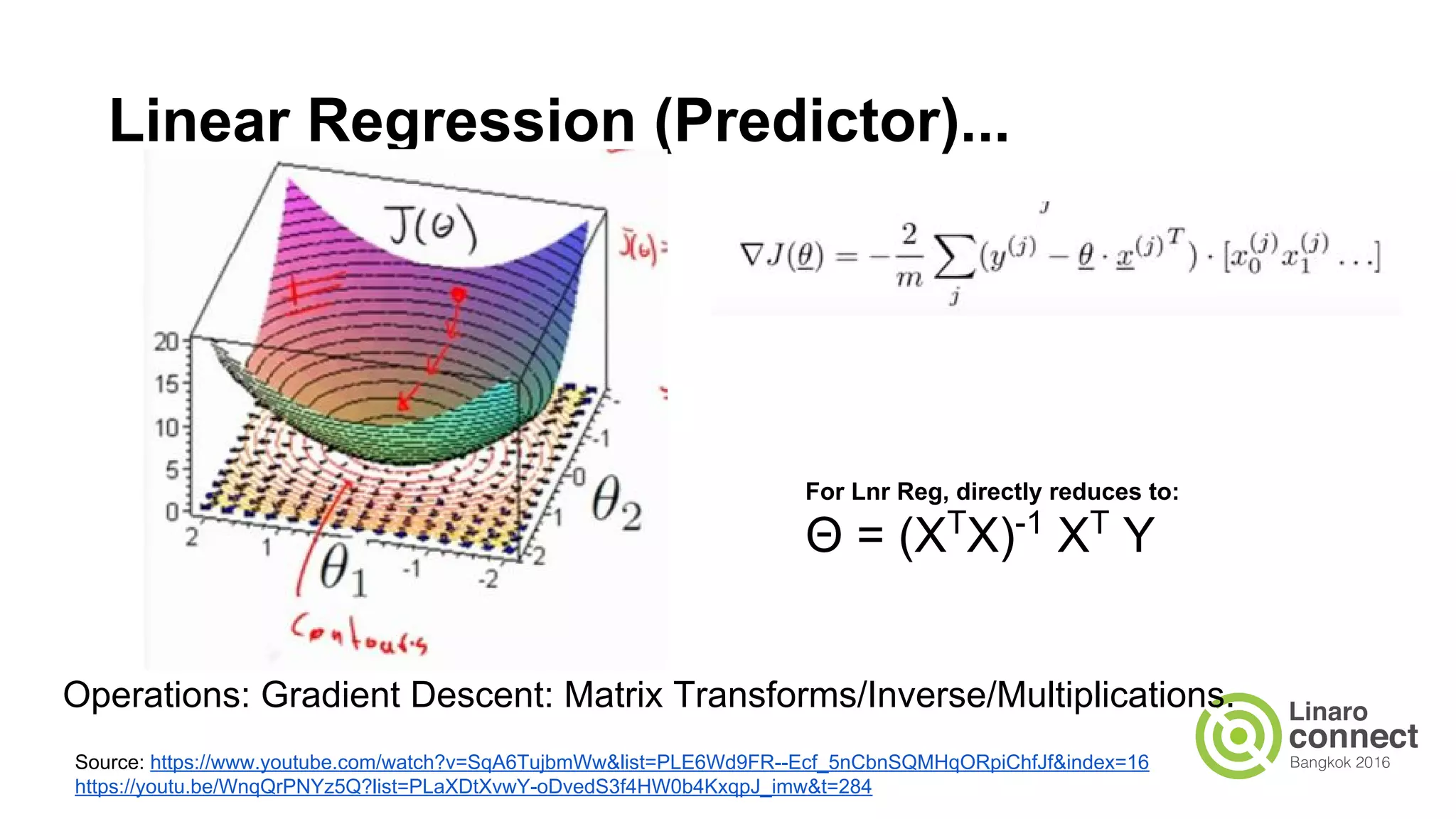
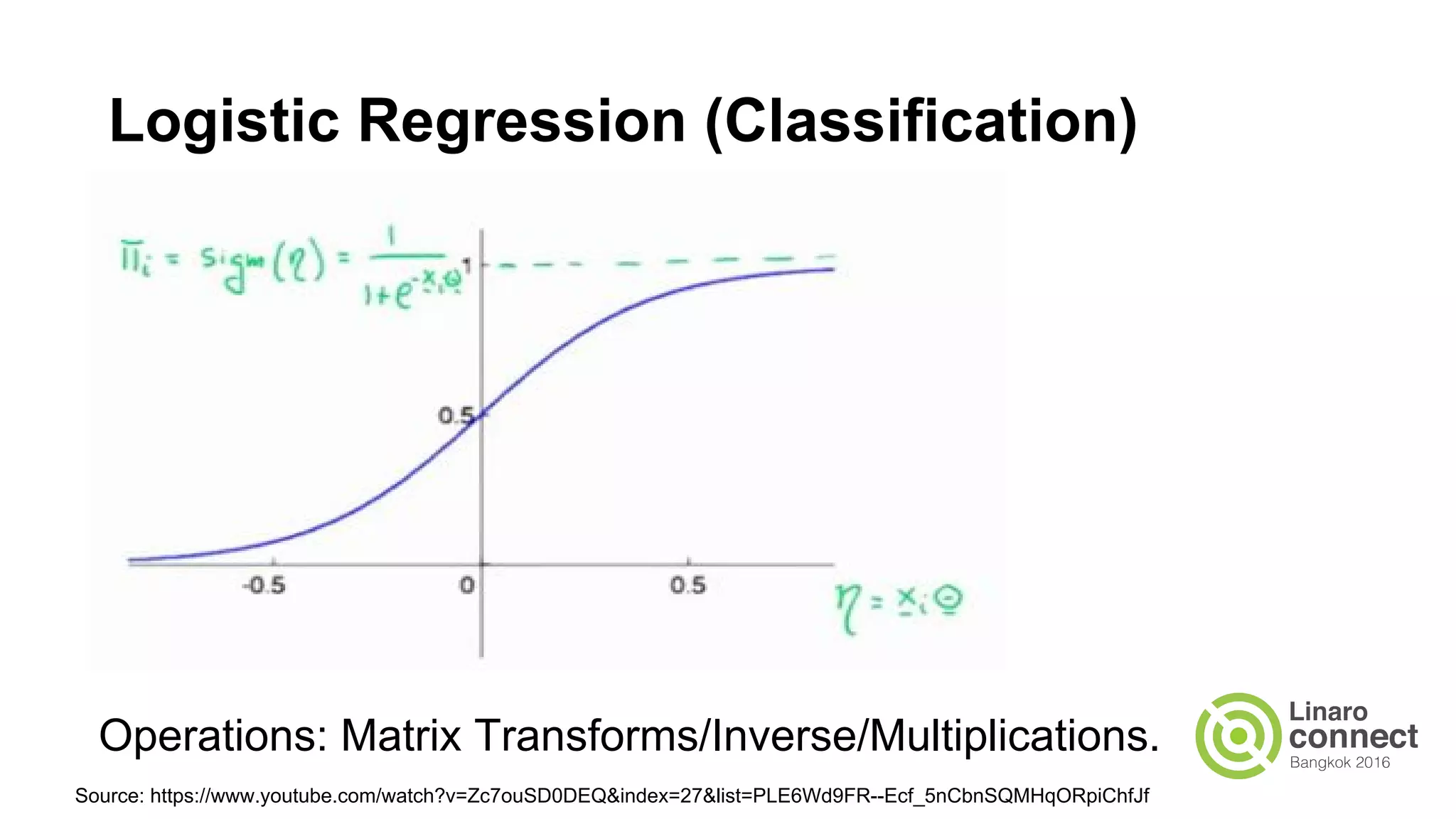
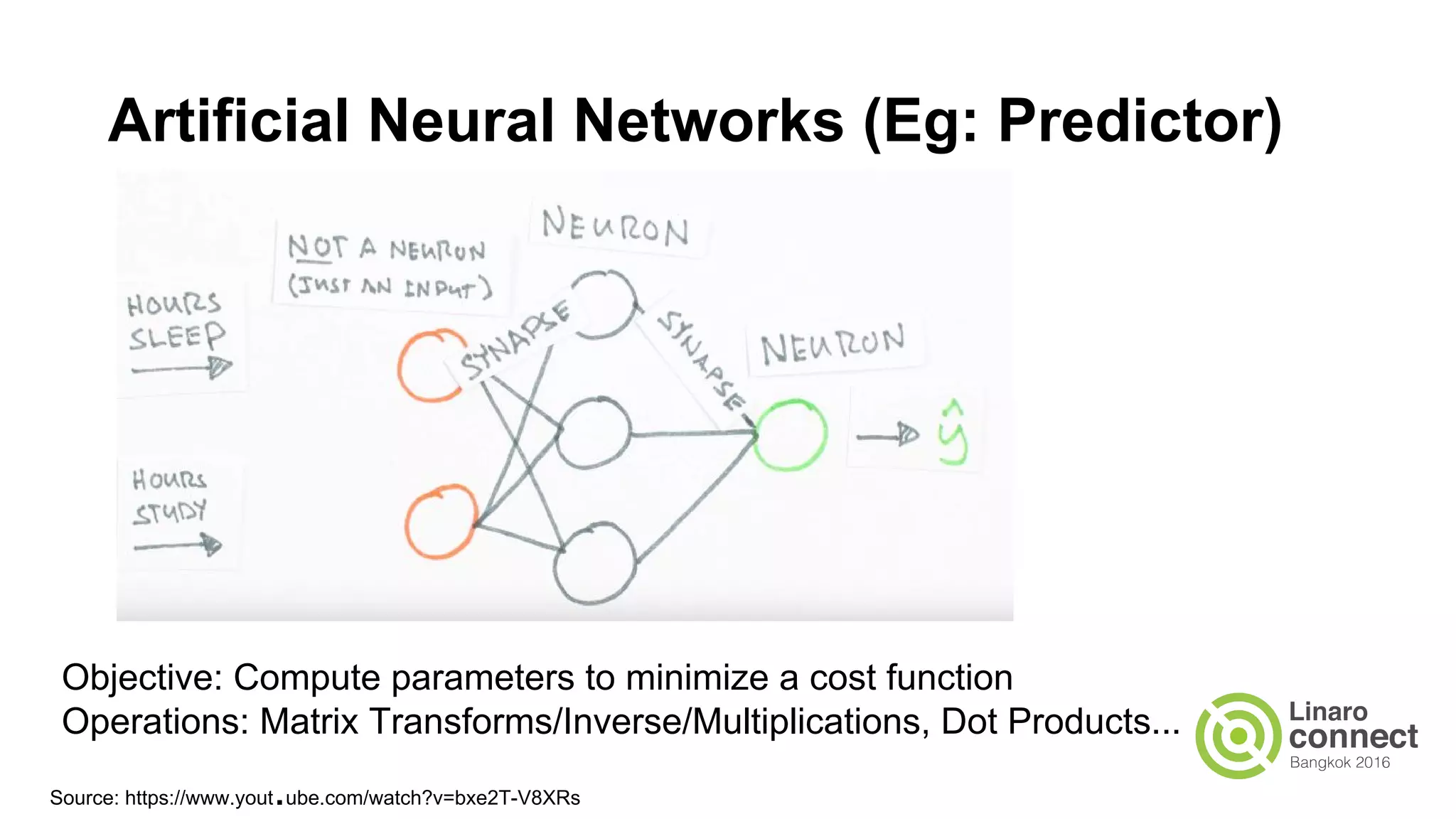
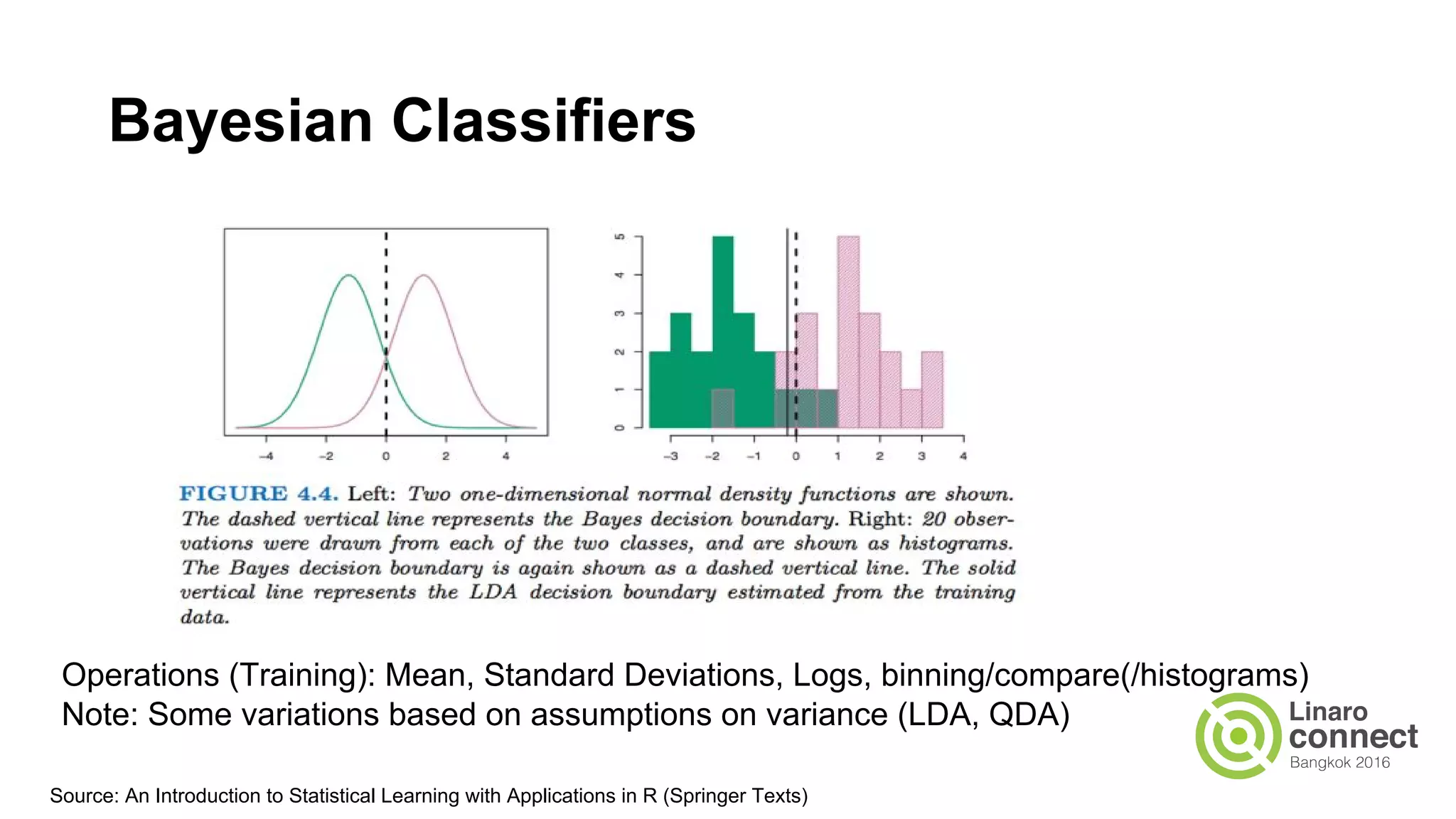
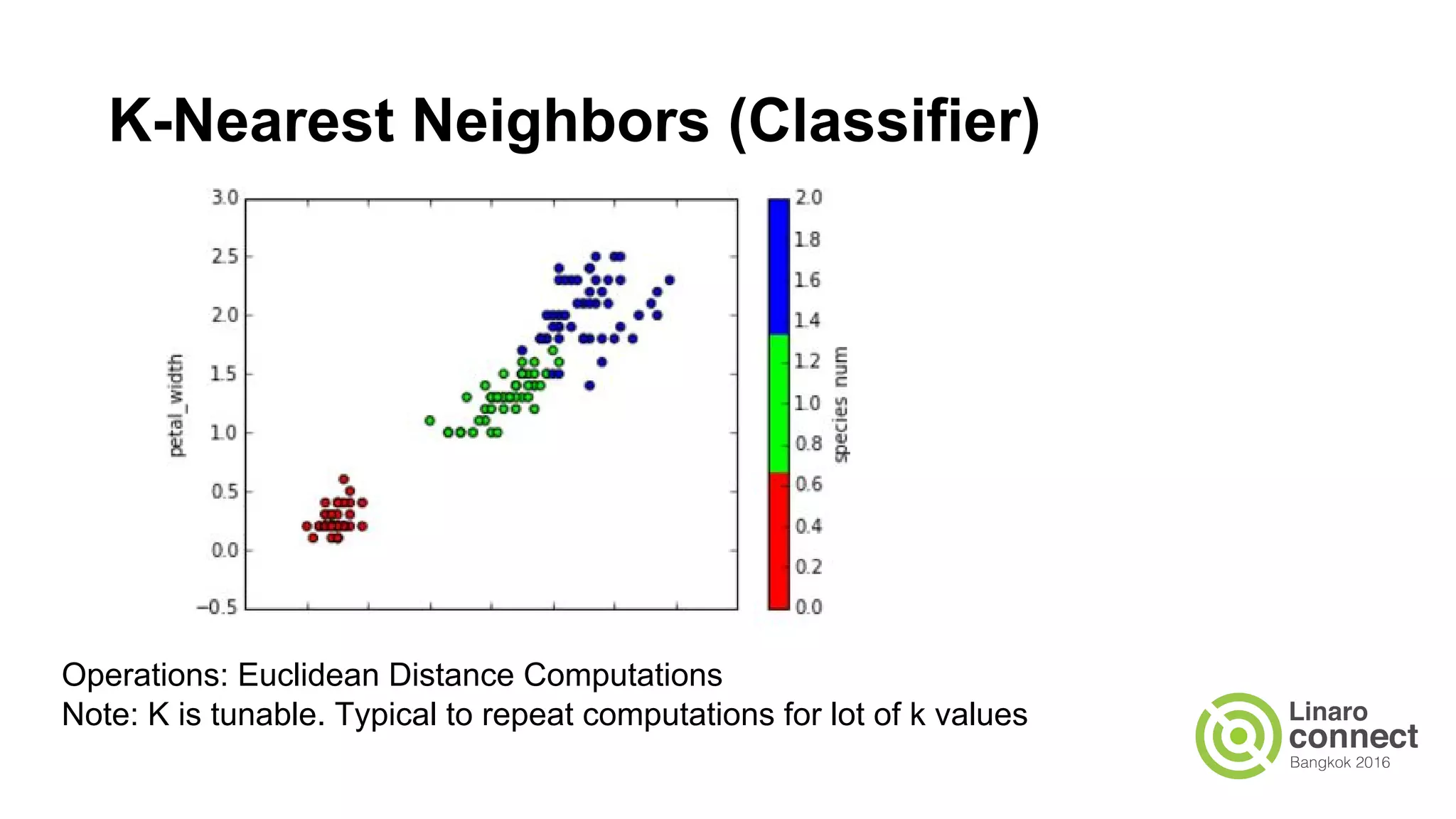
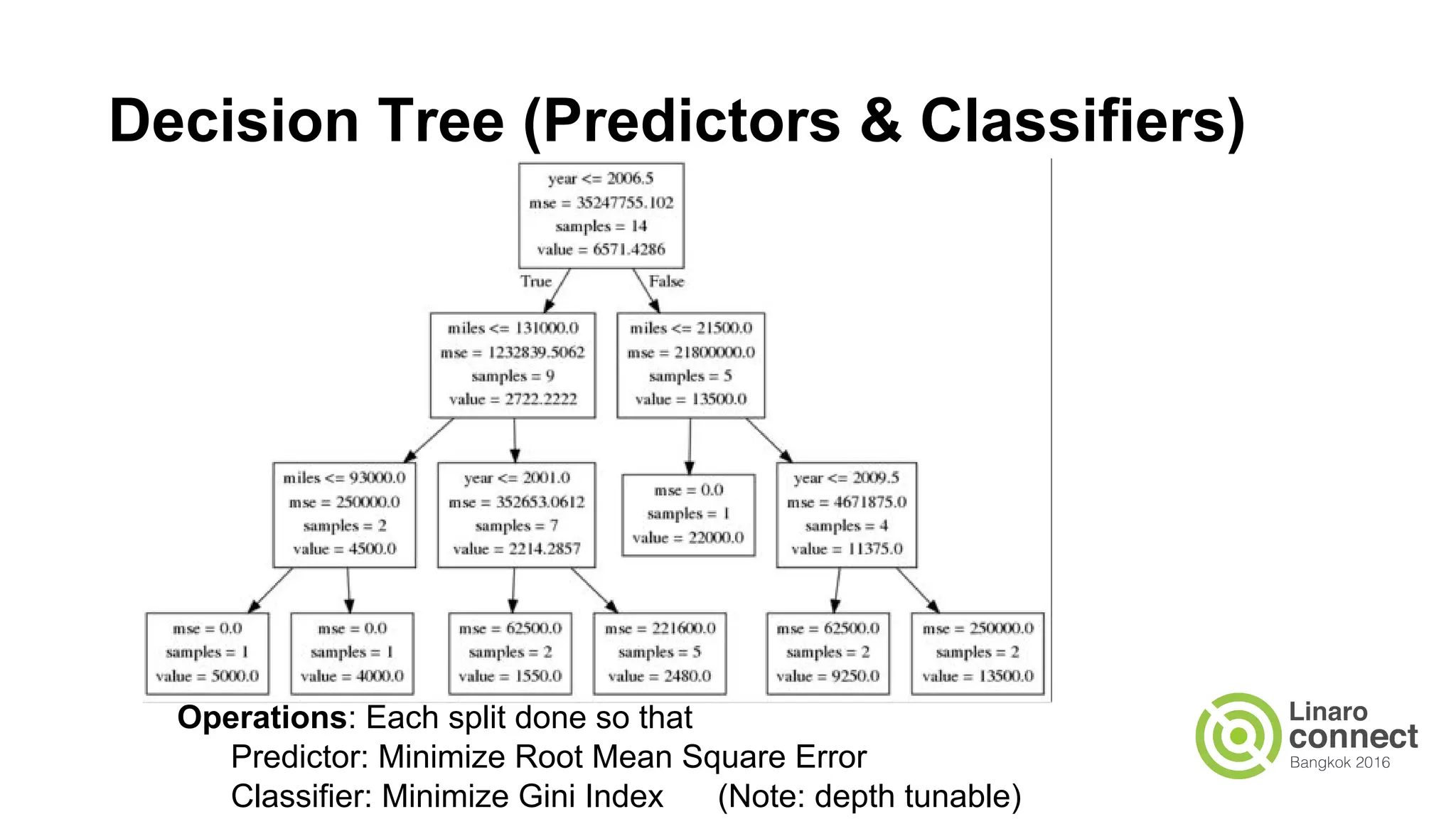
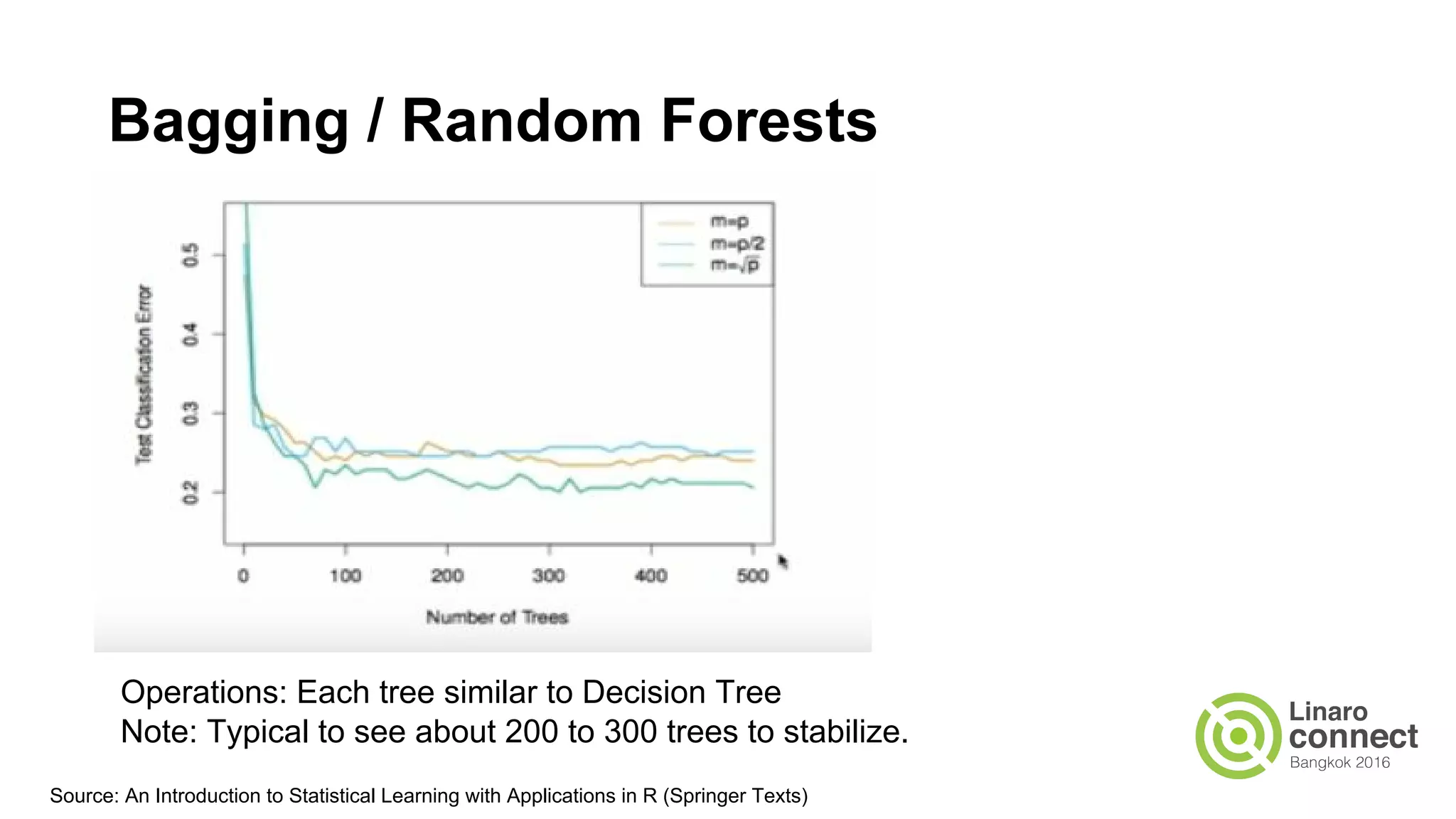






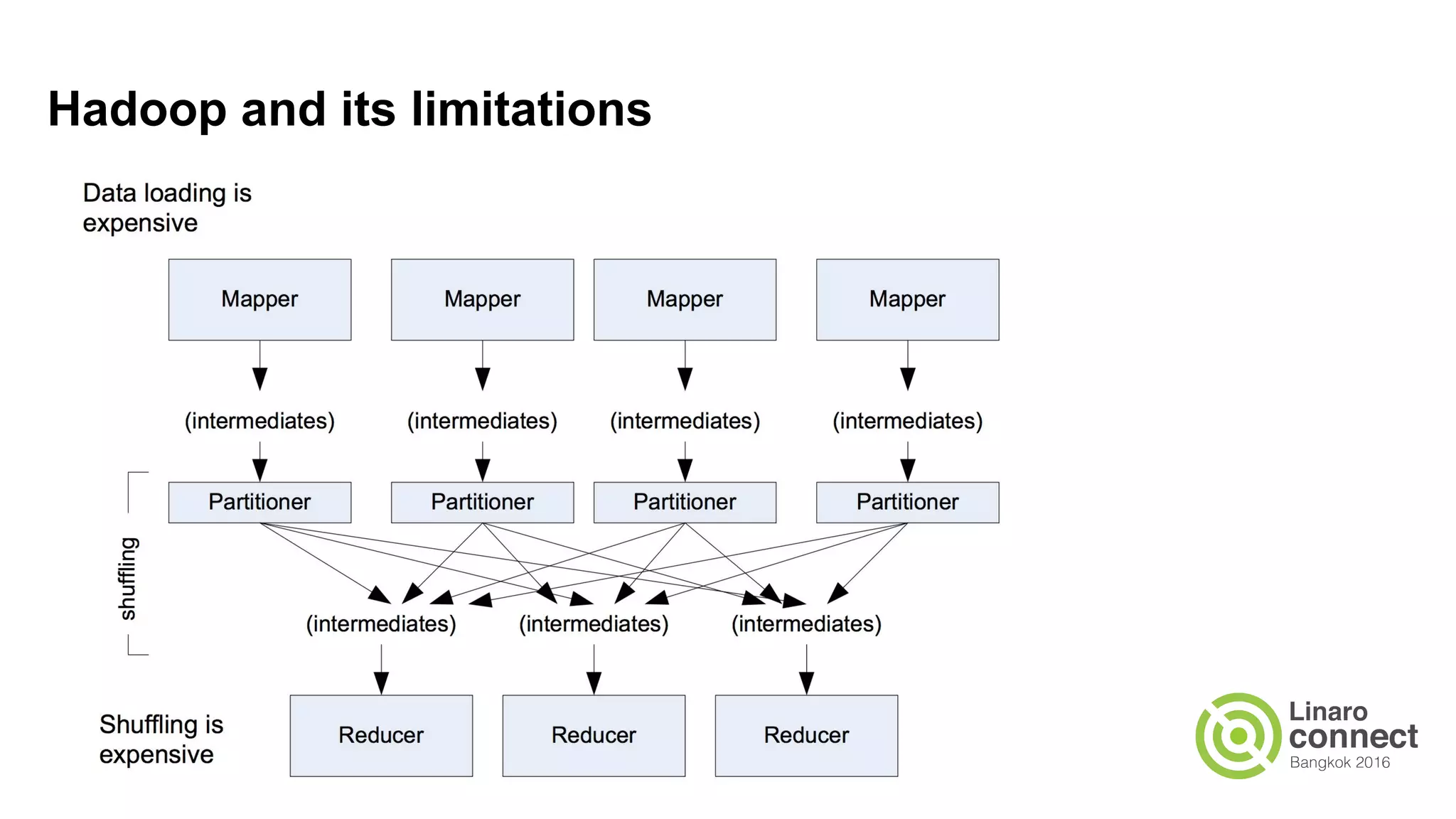
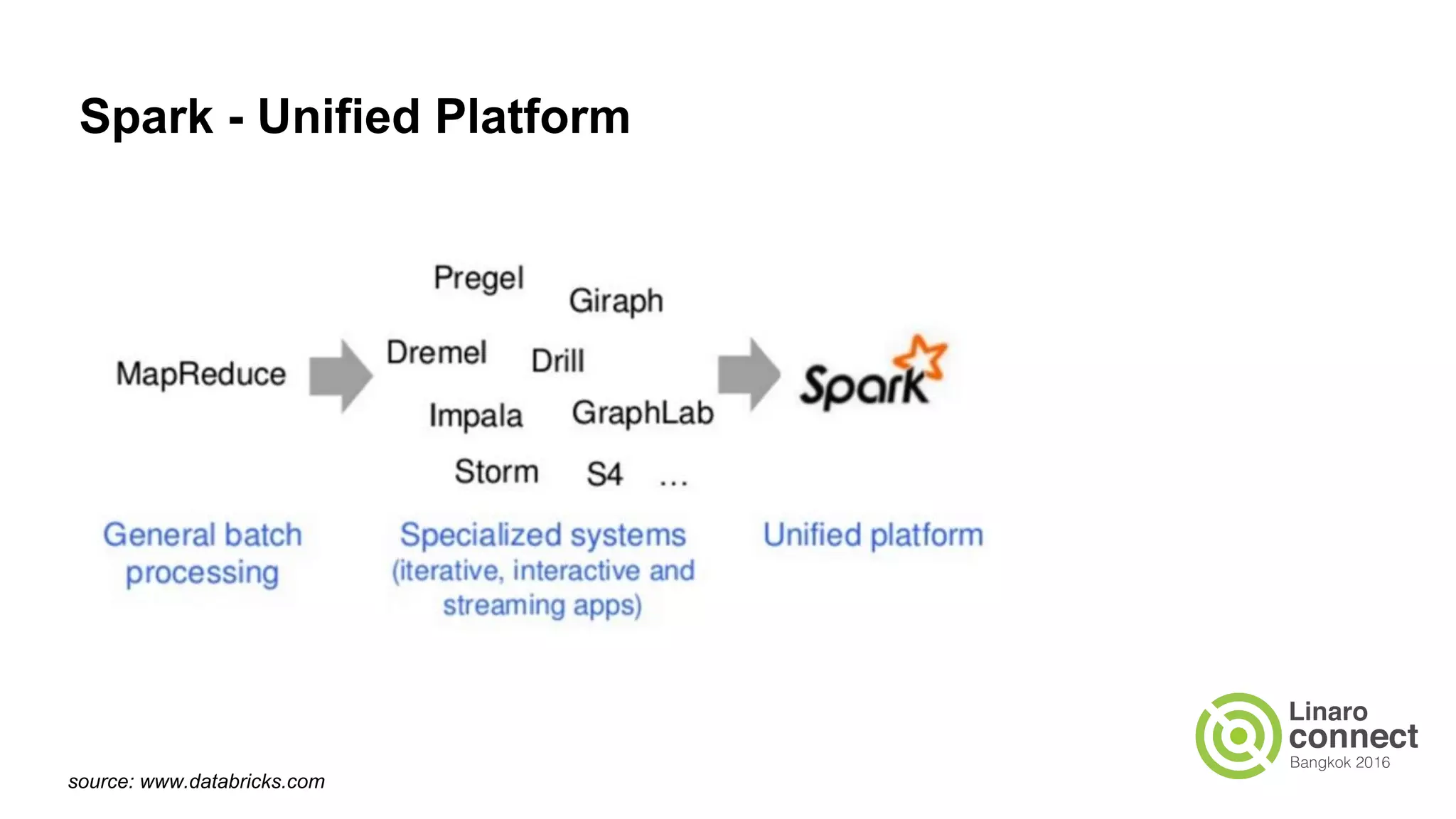
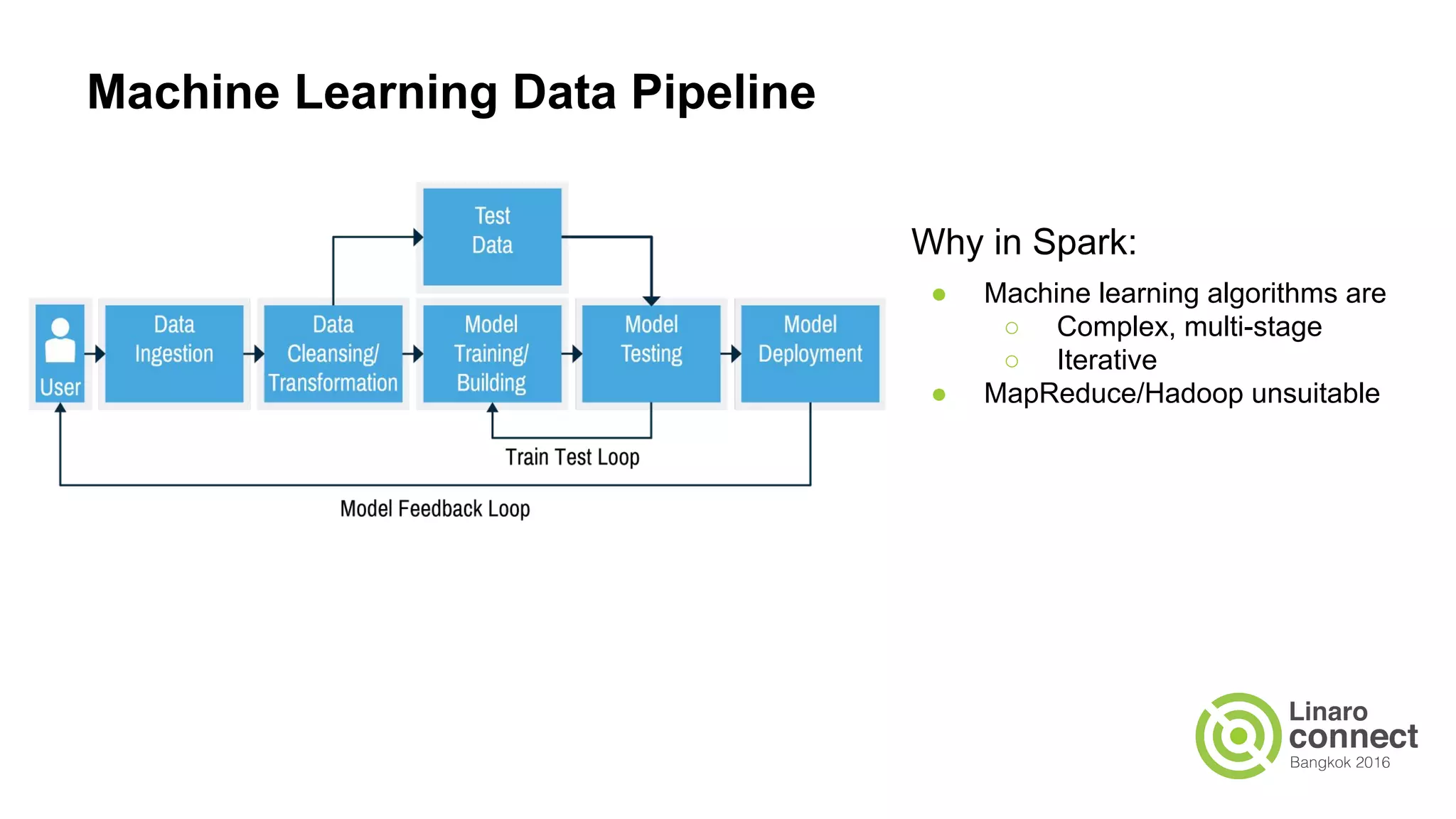
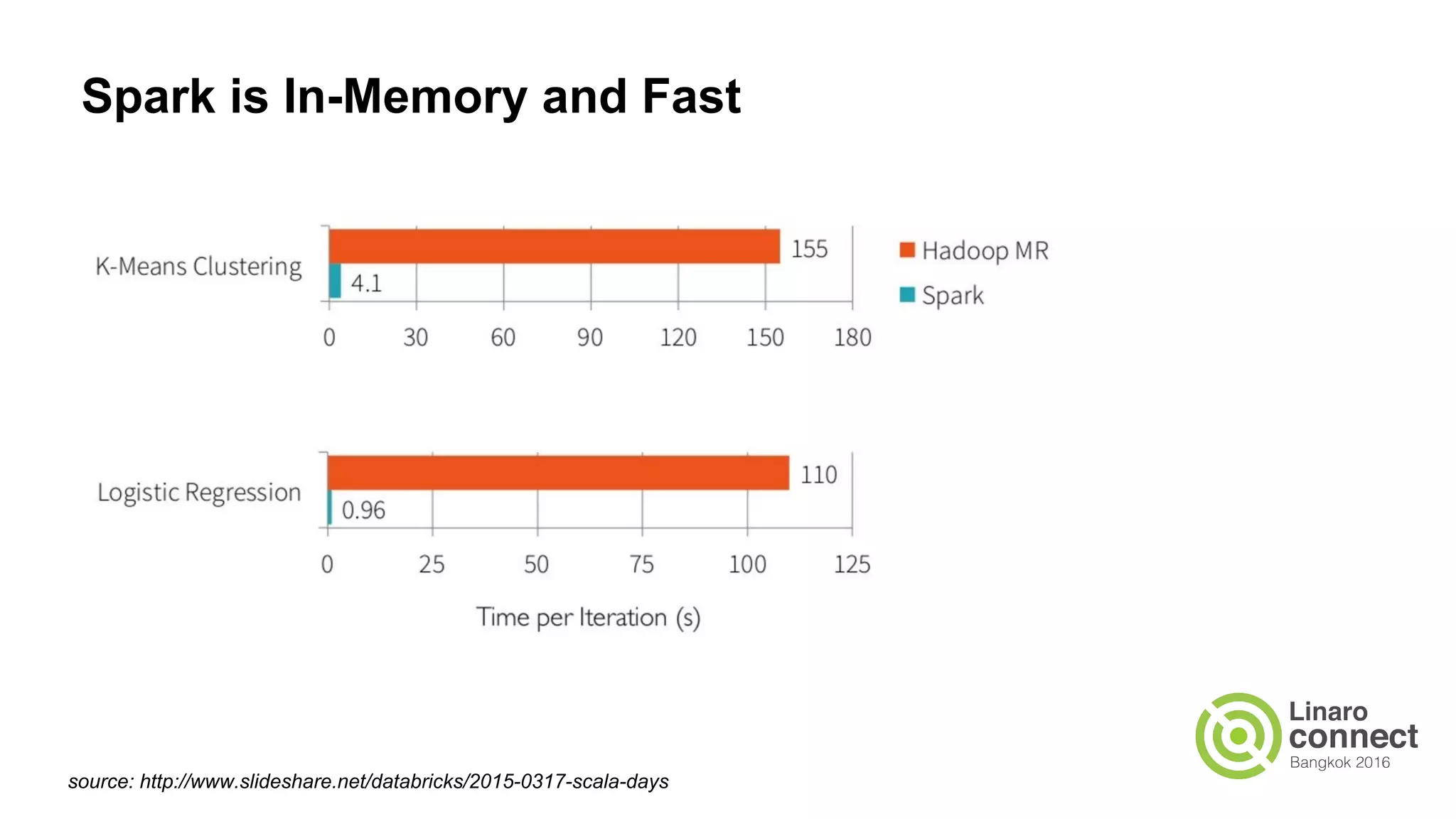
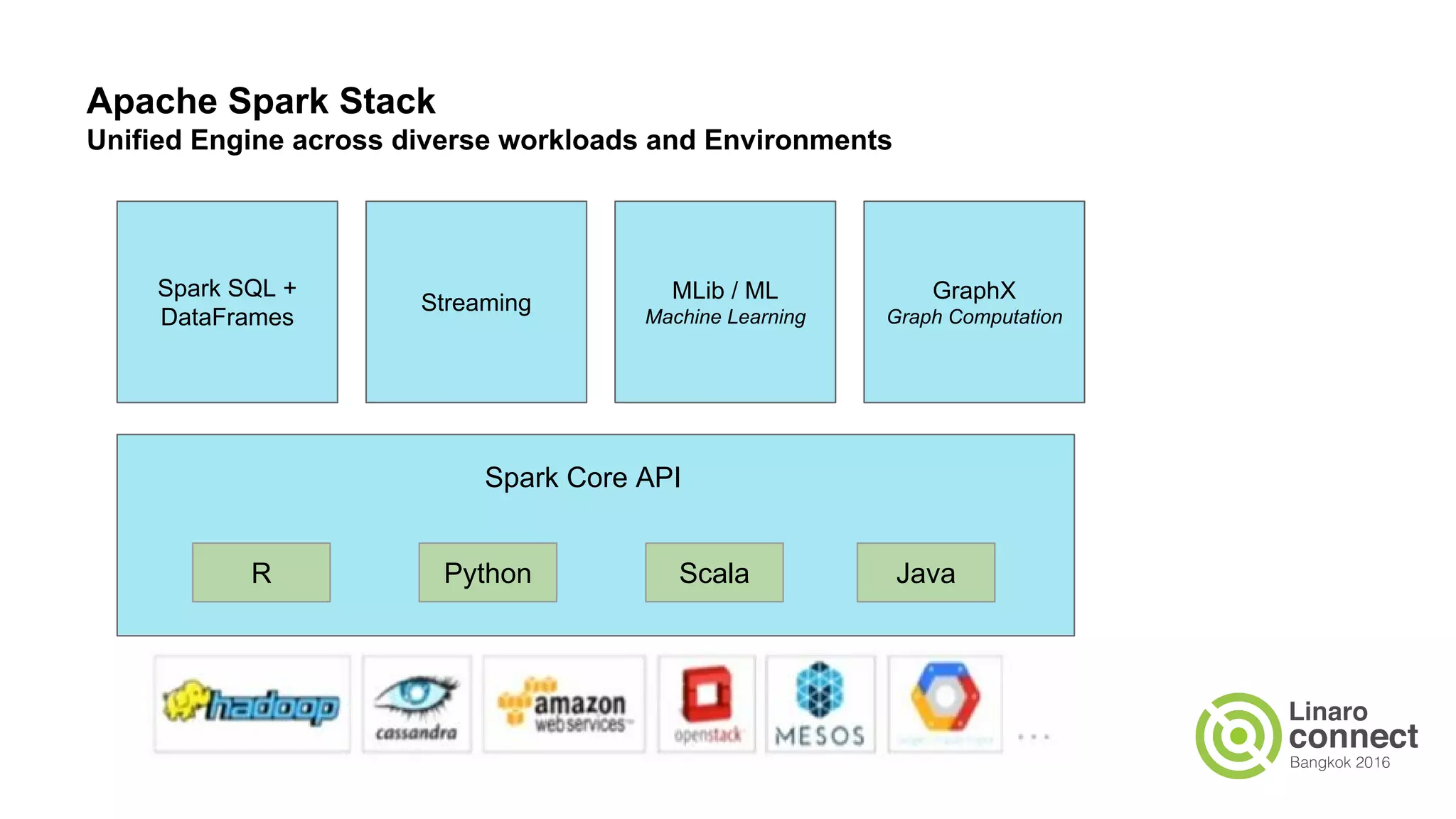
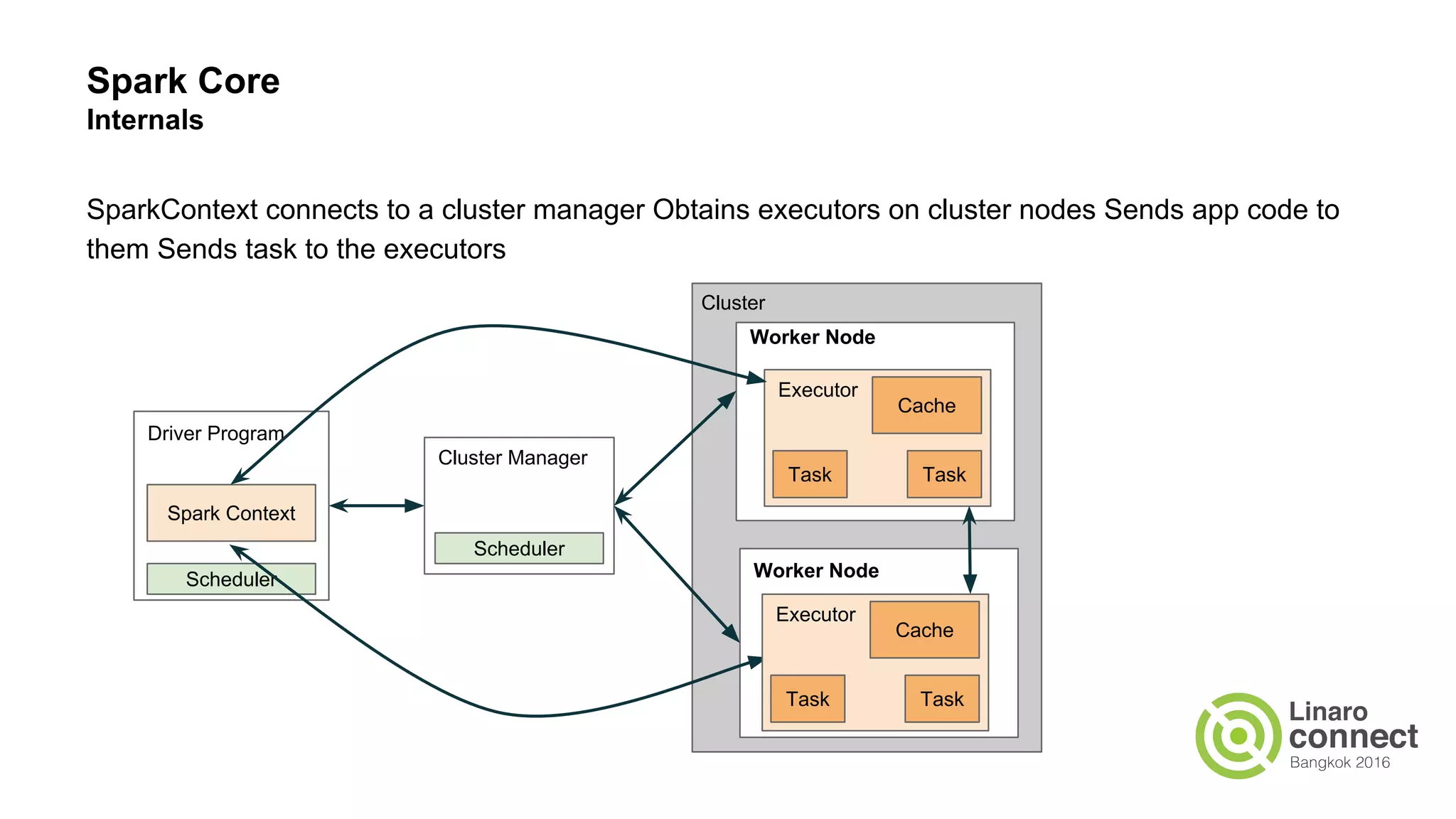
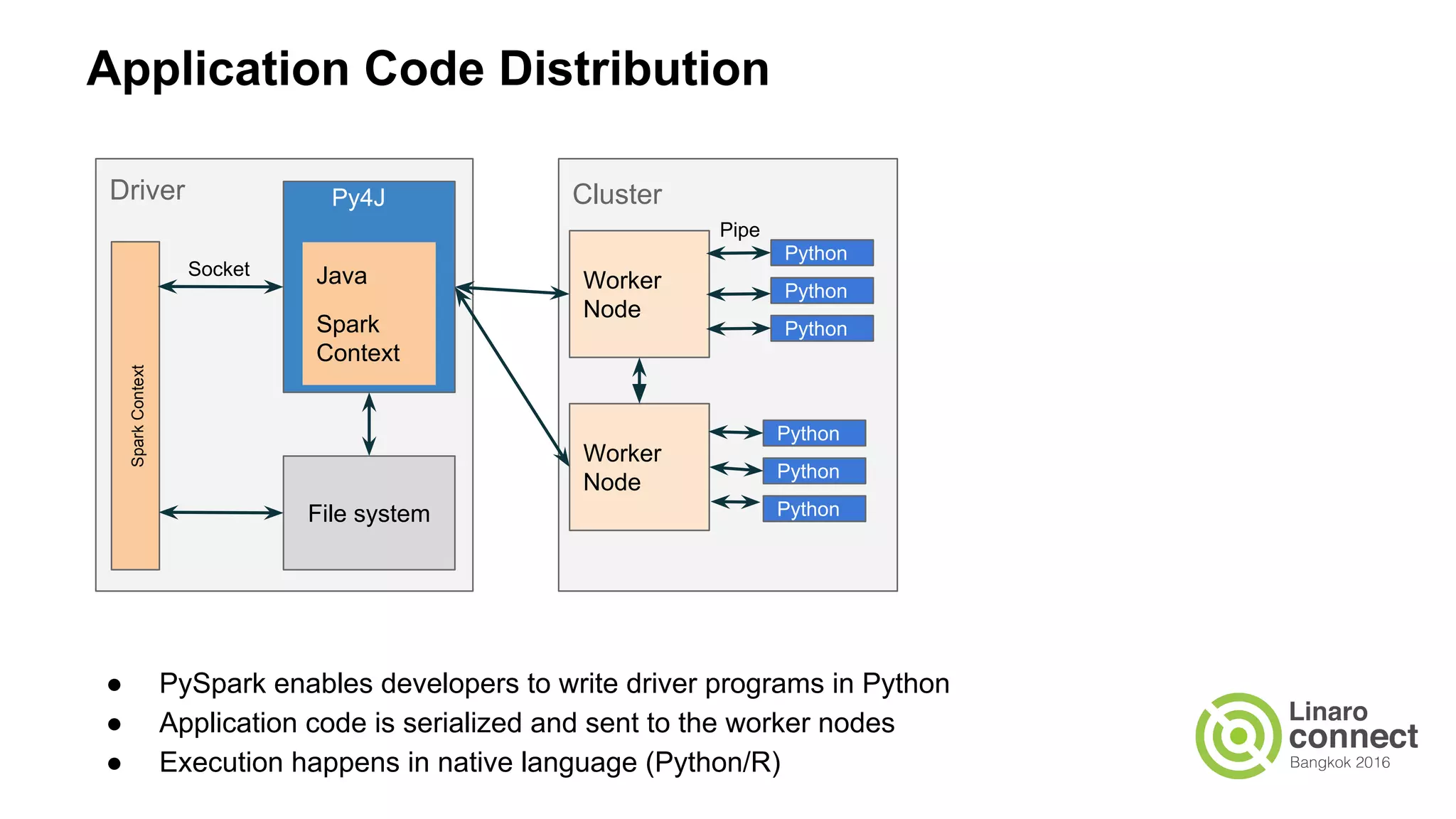

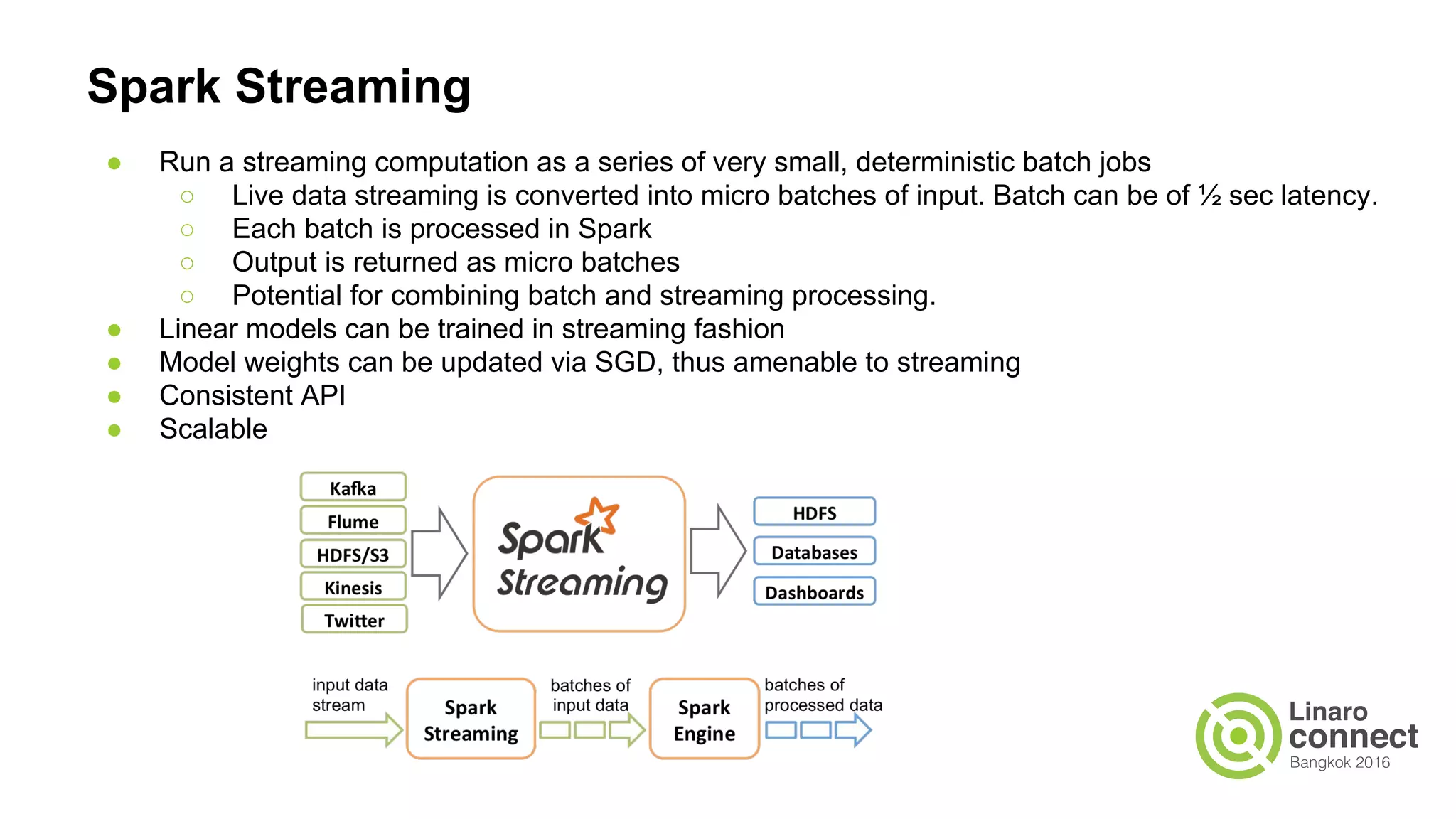



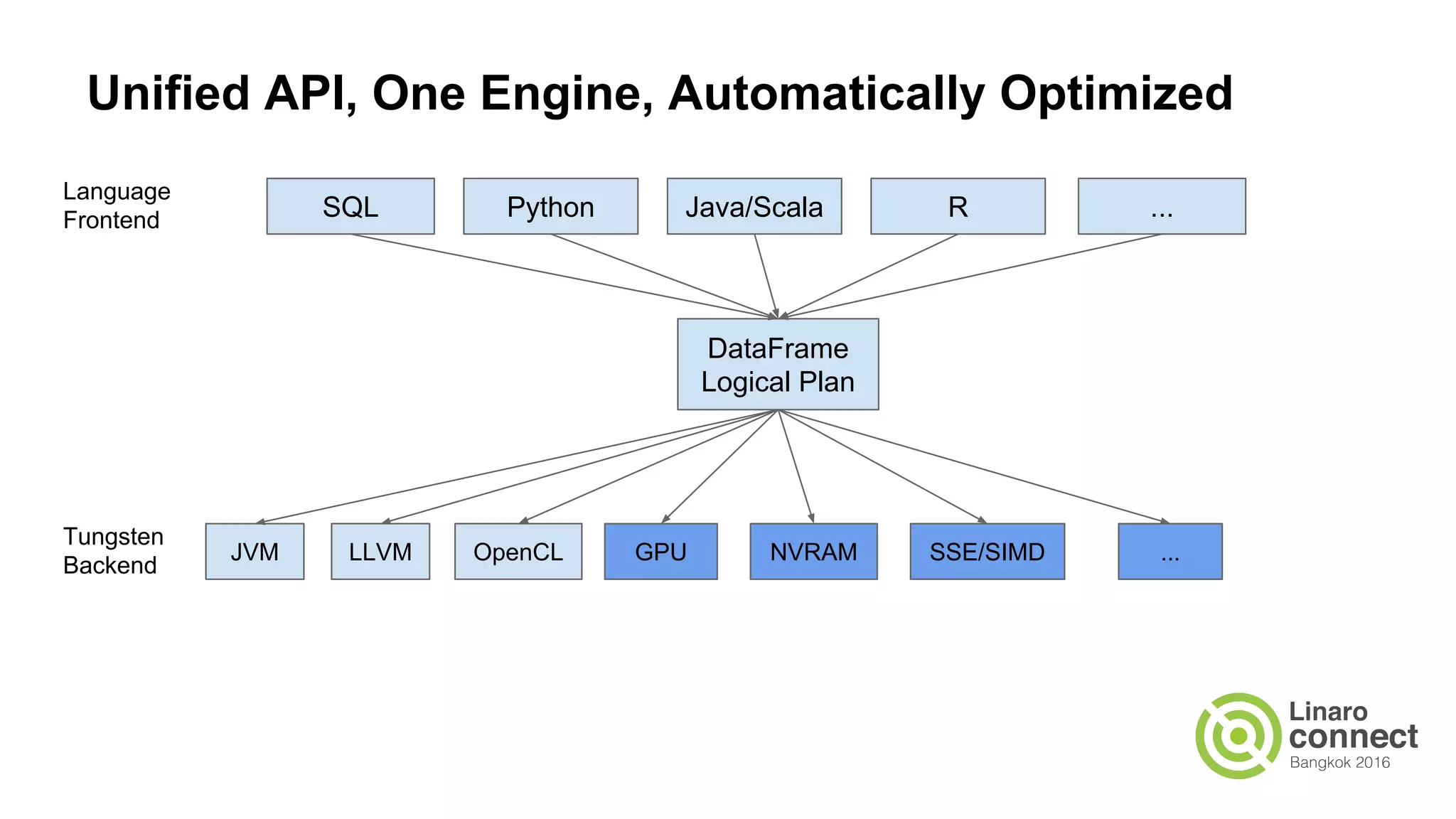

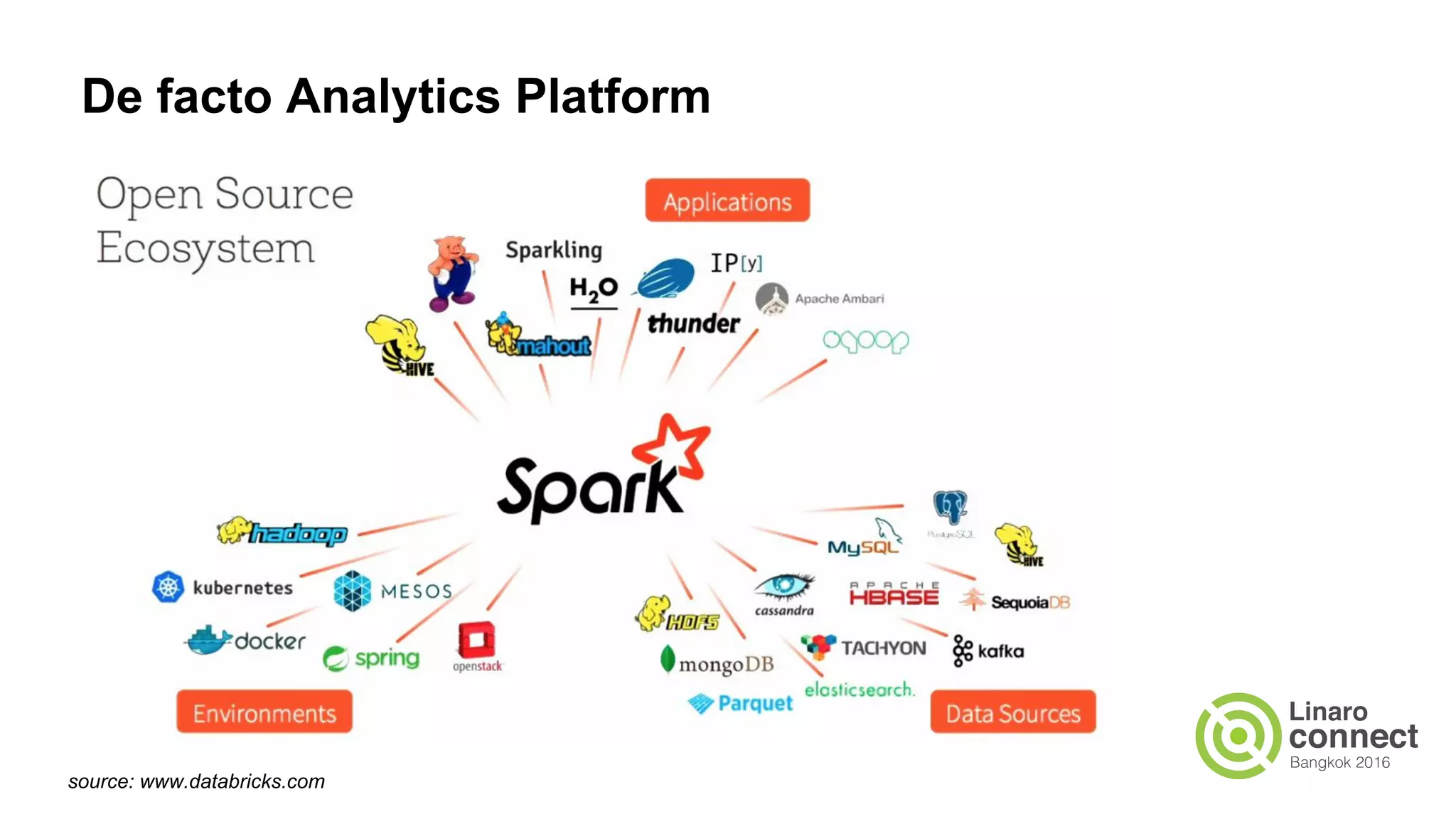


The document discusses the integration of data analytics and machine learning within the ARM ecosystem, emphasizing the need for optimized tools like Python libraries (e.g., pandas, scikit-learn) and tools for handling big data solutions. It outlines the operational capabilities of Apache Spark, comparing it with Hadoop, while presenting the necessity for a unified platform that supports various machine learning algorithms and efficient data pipelines. The document further explores strategies for scaling data science applications across clusters and highlights significant advancements in Spark's architecture and capabilities, particularly focusing on in-memory processing and resource optimization.

































![[Harvard CS264] 09 - Machine Learning on Big Data: Lessons Learned from Googl...](https://cdn.slidesharecdn.com/ss_thumbnails/machinelearningbigdata-maxlin-cs264opt-110331195757-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

















































![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)




