Downloaded 26 times




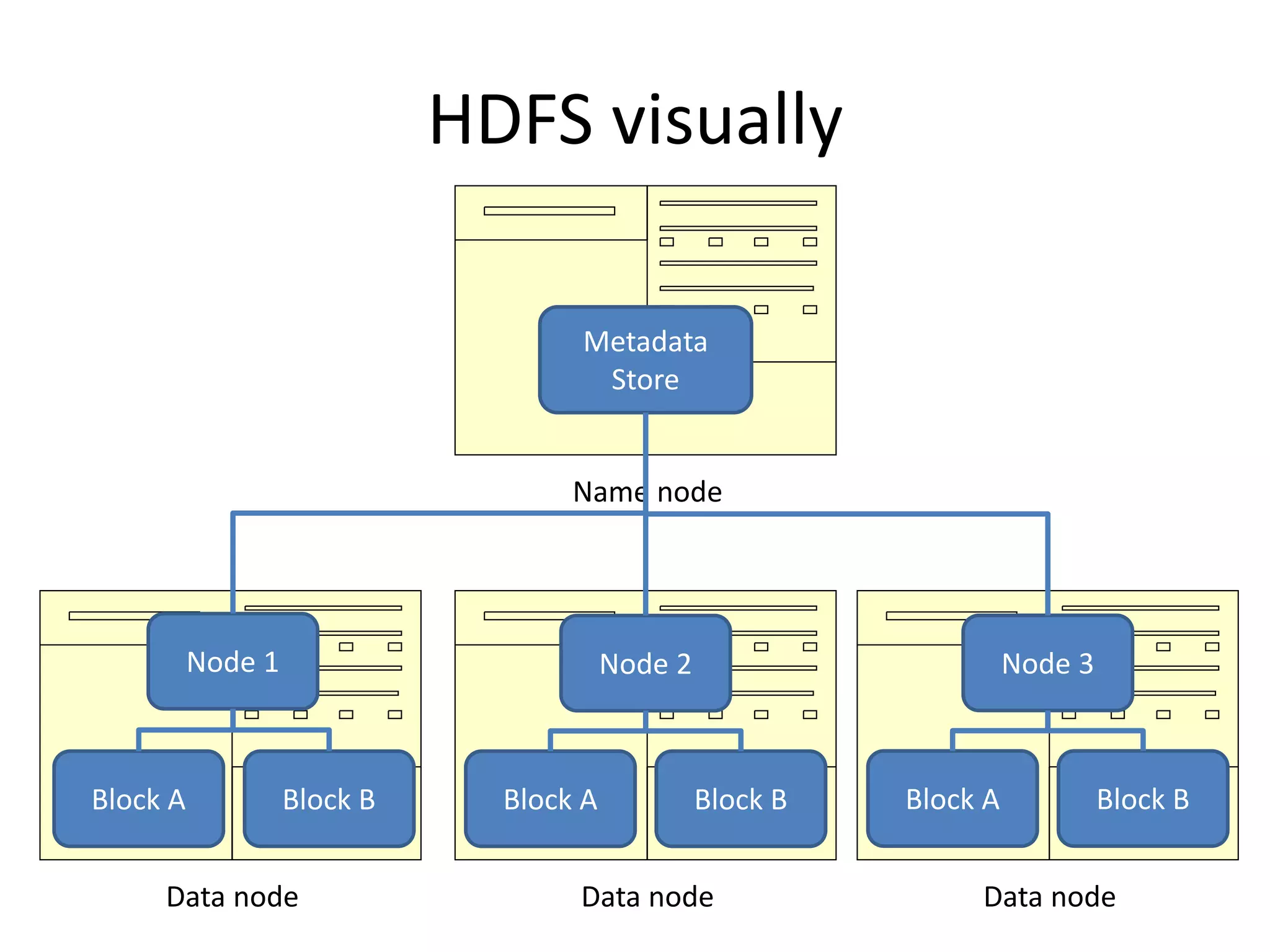
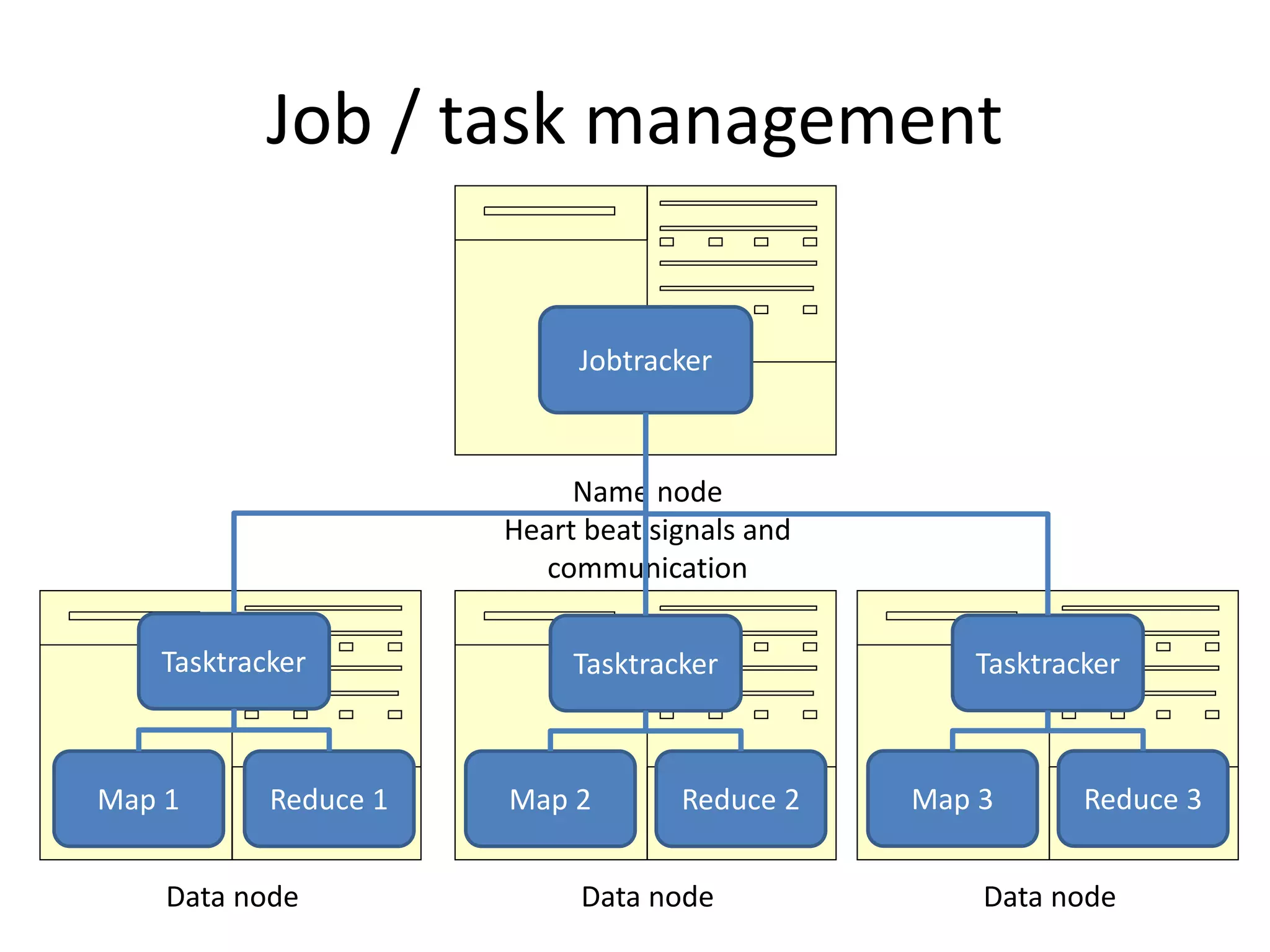


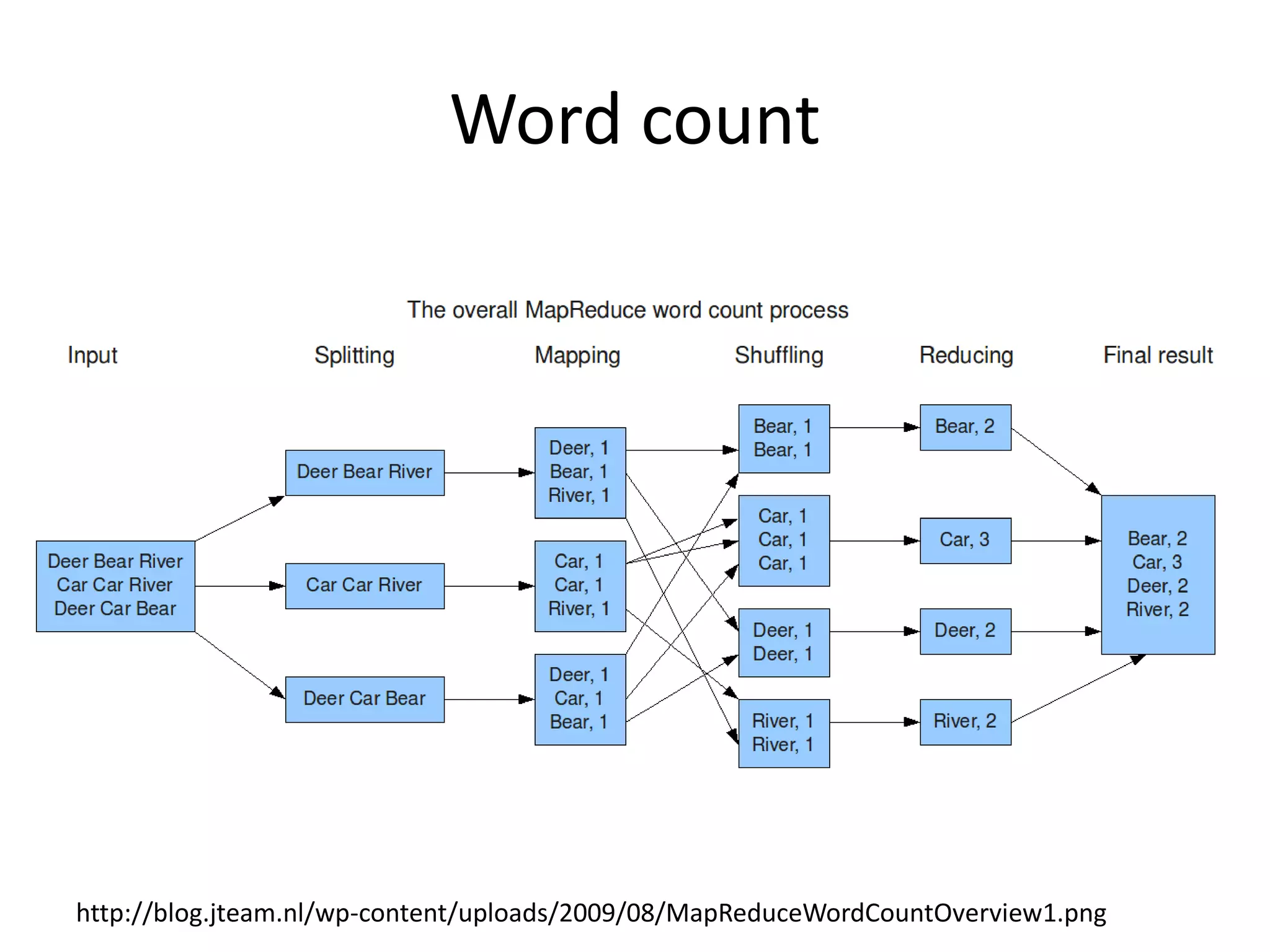
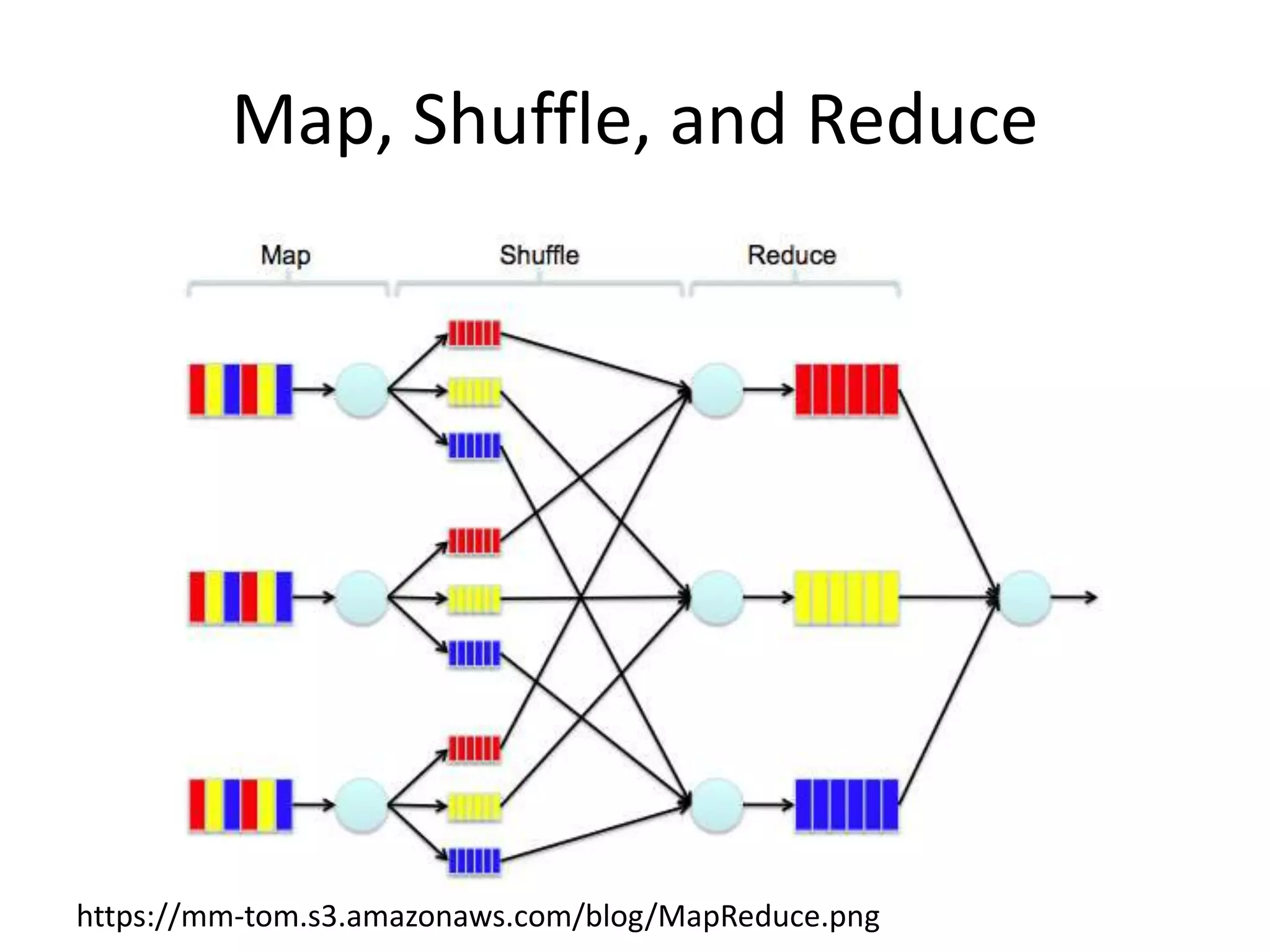


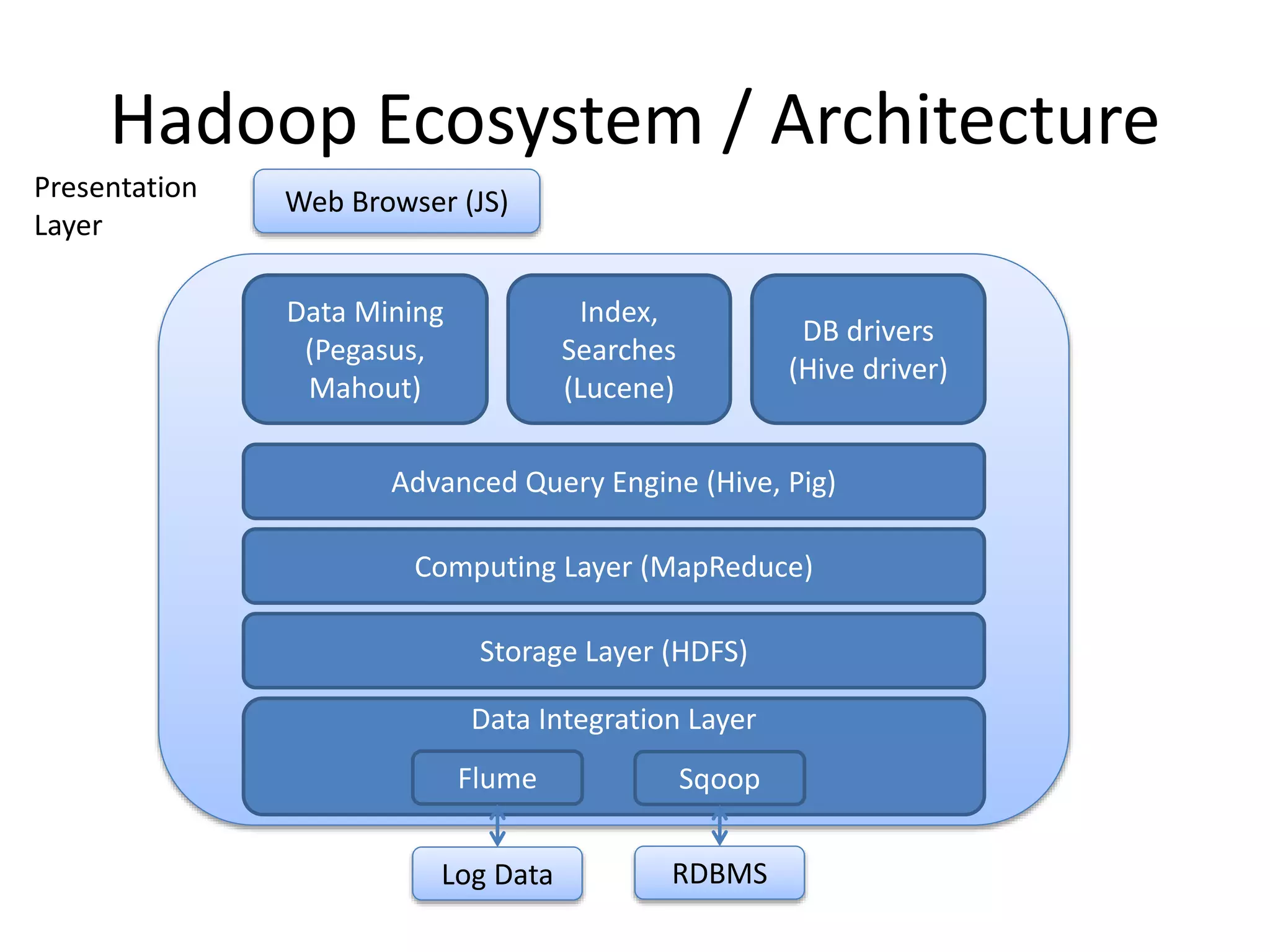



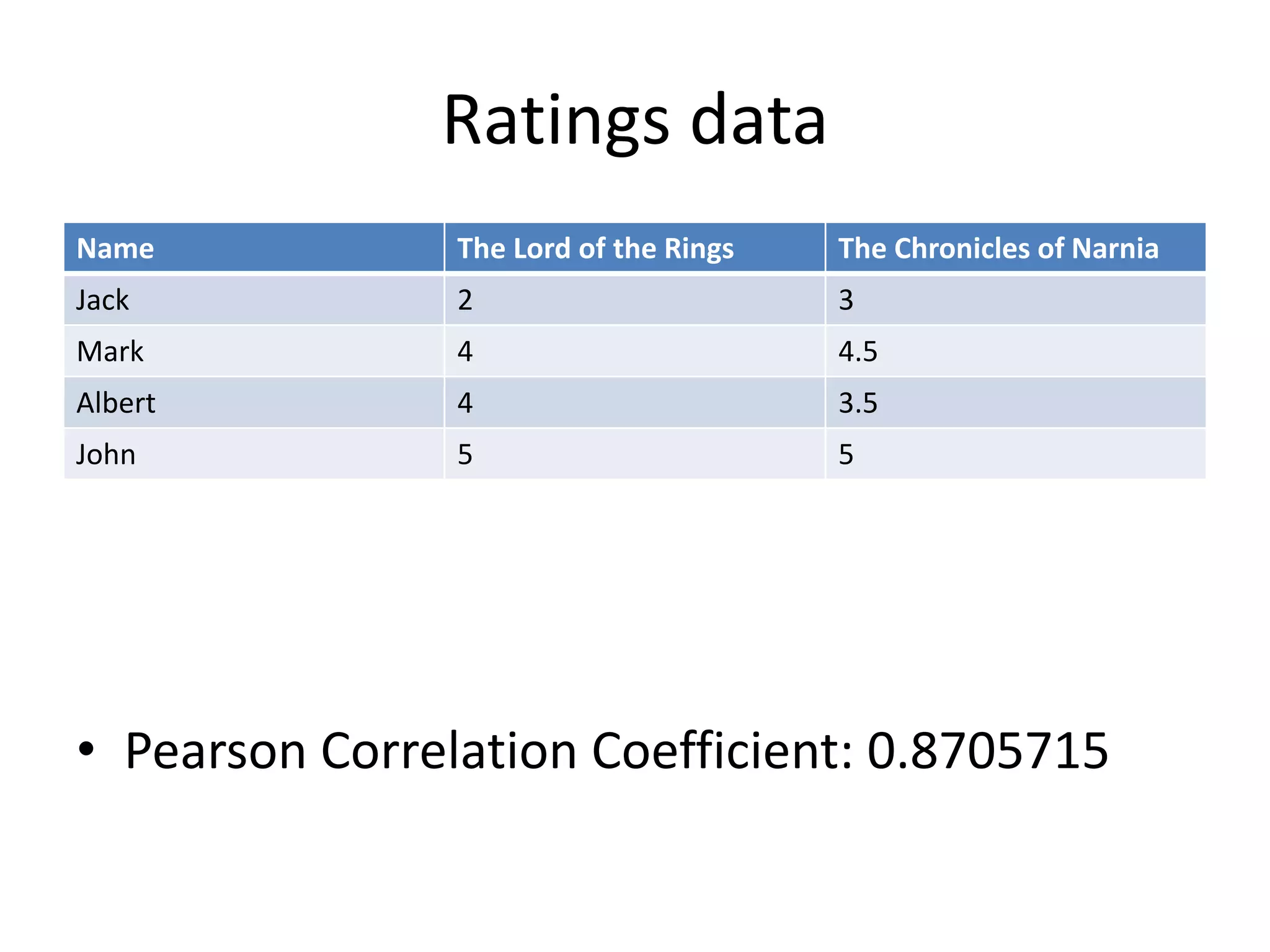
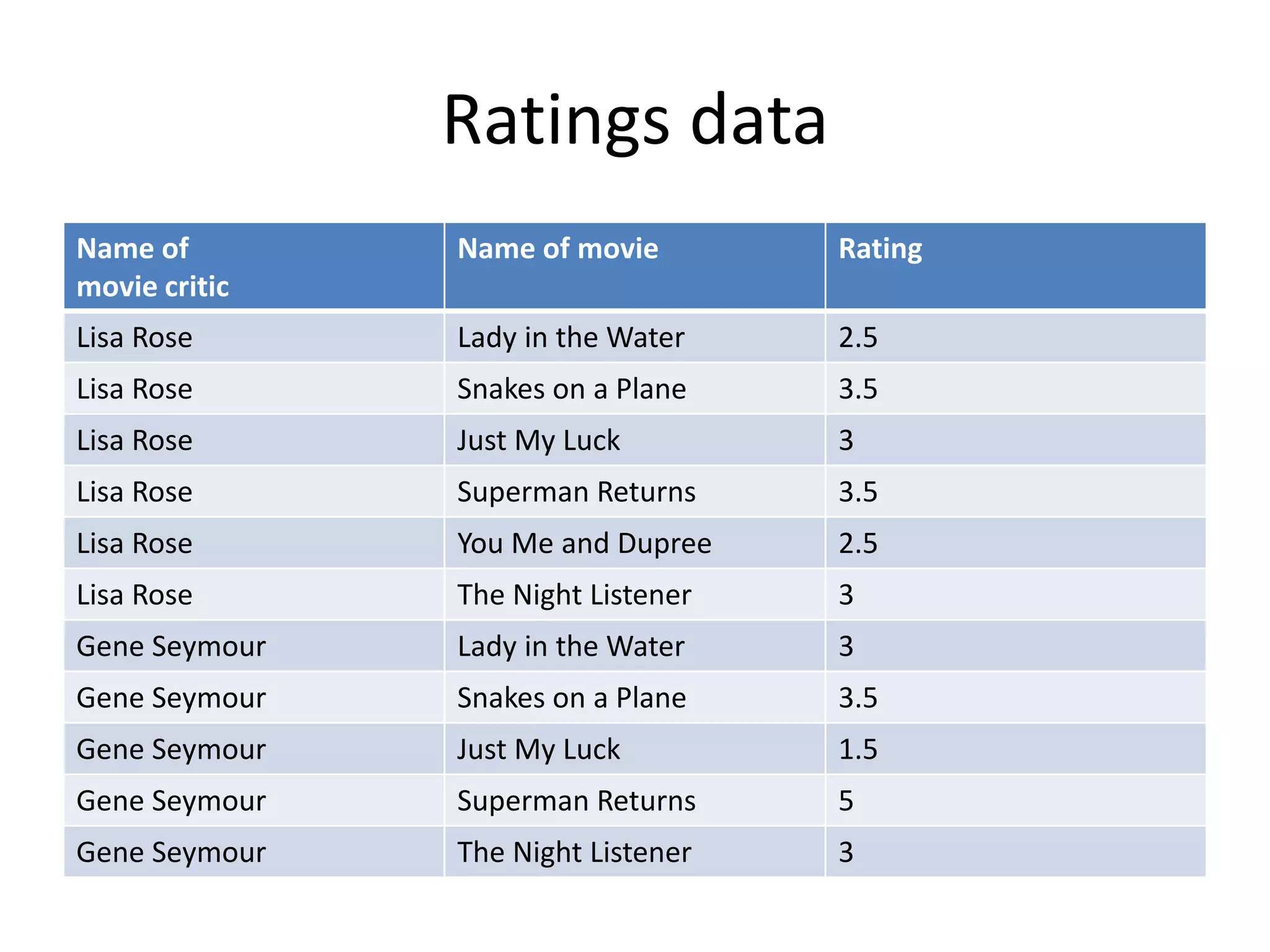










This document summarizes a meeting about Pig and Hive for Hadoop. The agenda included an overview of Hadoop and MapReduce, demonstrations of Pig and Hive, and demos of exercises and projects using an on-premise Hadoop emulator and Azure HDInsight. Pig and Hive were presented as domain-specific languages that simplify writing MapReduce jobs by translating queries into the jobs. Recommendation algorithms were demonstrated in C# and Pig.




















































































