The document is a summer training presentation on big data and Hadoop, covering key concepts such as the definition of big data, the characteristics of different data structures, and an overview of the Hadoop ecosystem. It discusses various tools like MapReduce, Apache Pig, Hive, Flume, and Sqoop, along with practical examples of data analysis using these technologies. The conclusion emphasizes the learning achieved regarding big data sources and the use of Hadoop tools for data management.

![Index:
Sunday, 14 October 2018
2
Slide no. Content
1. Introduction
2 - 3 Index
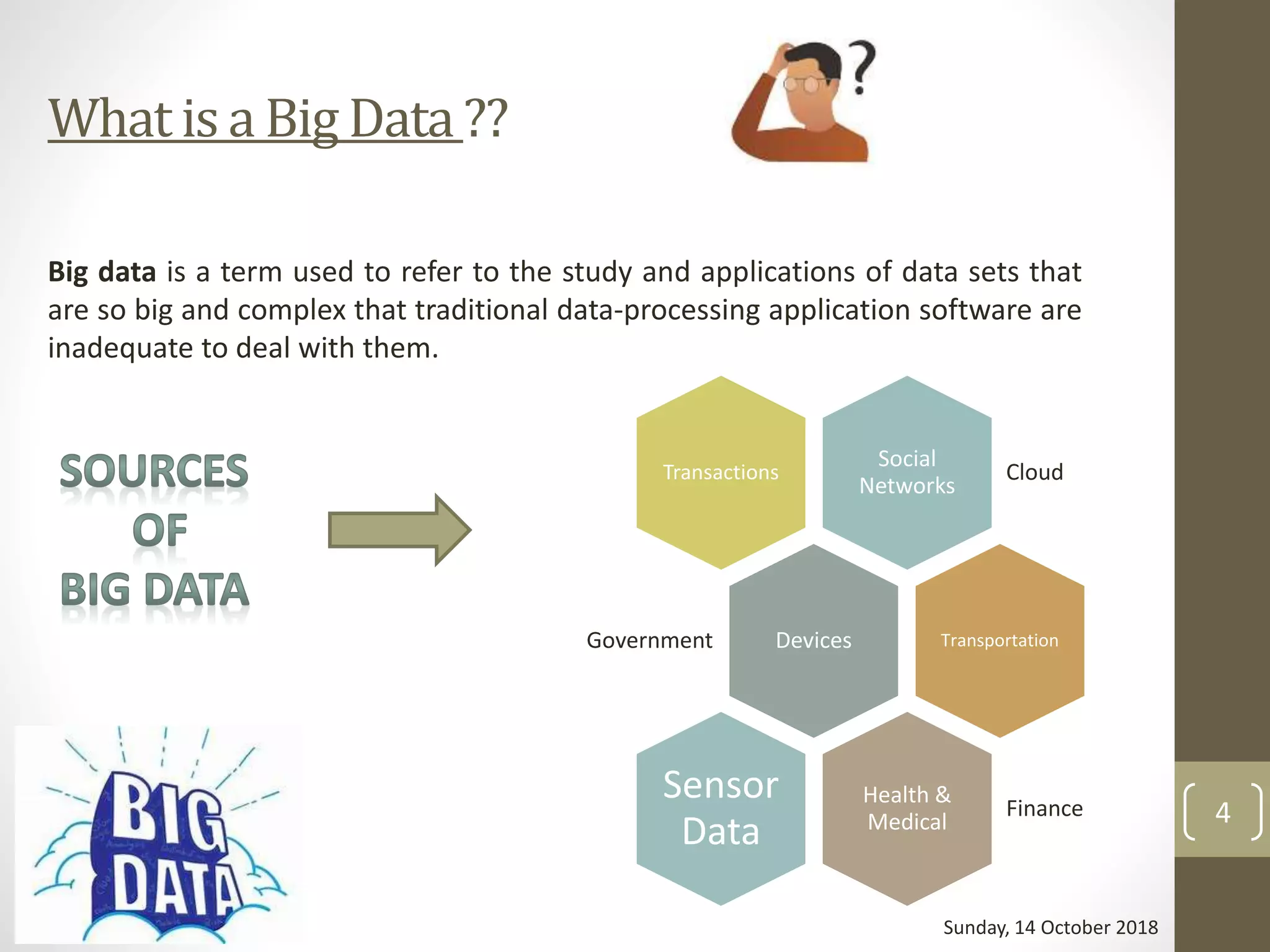
4. What is Big Data ?
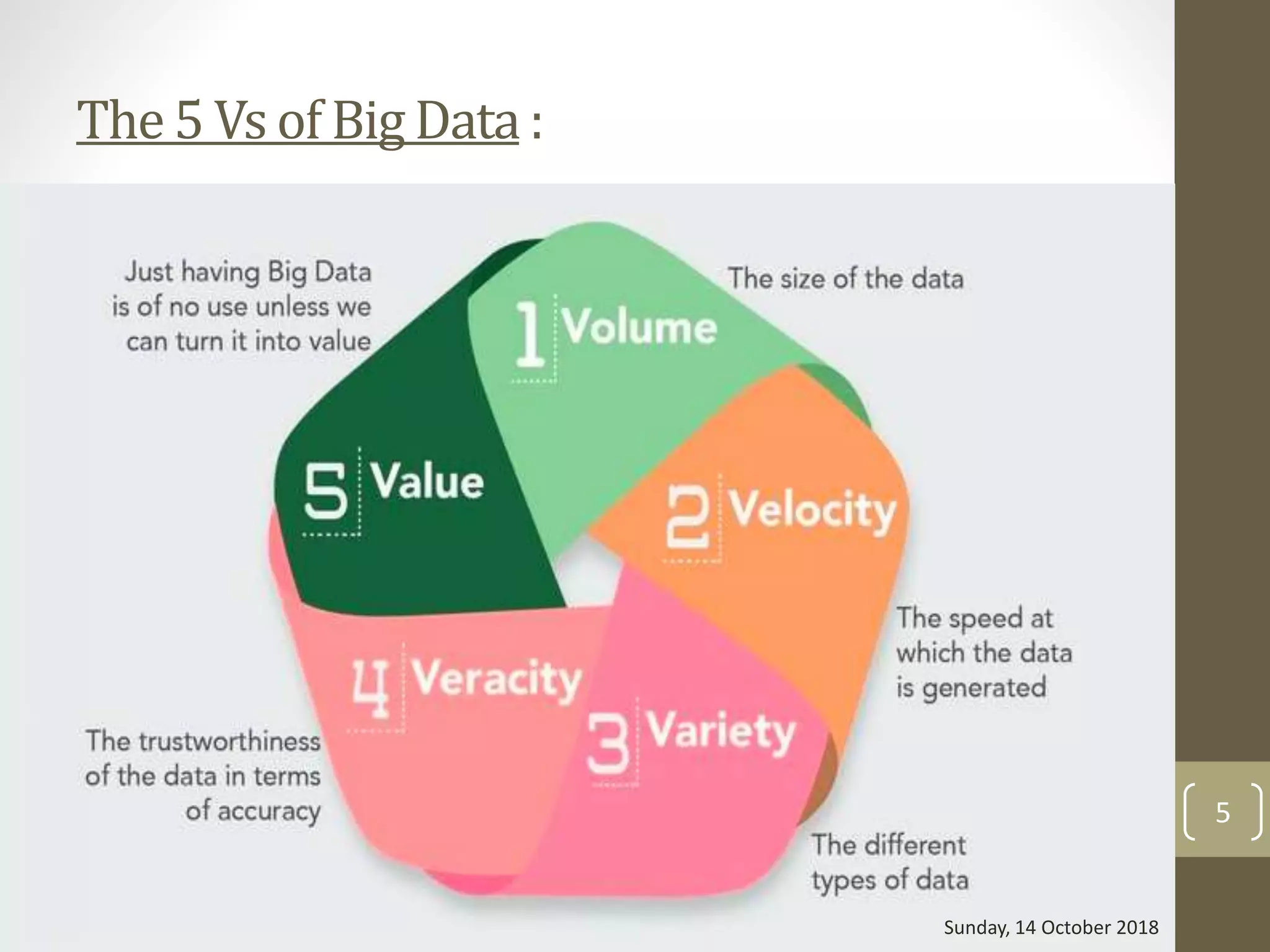
5. The 5 Vs of Big Data
6. Data Structures: Characteristics of Big Data
7. Introduction to Hadoop
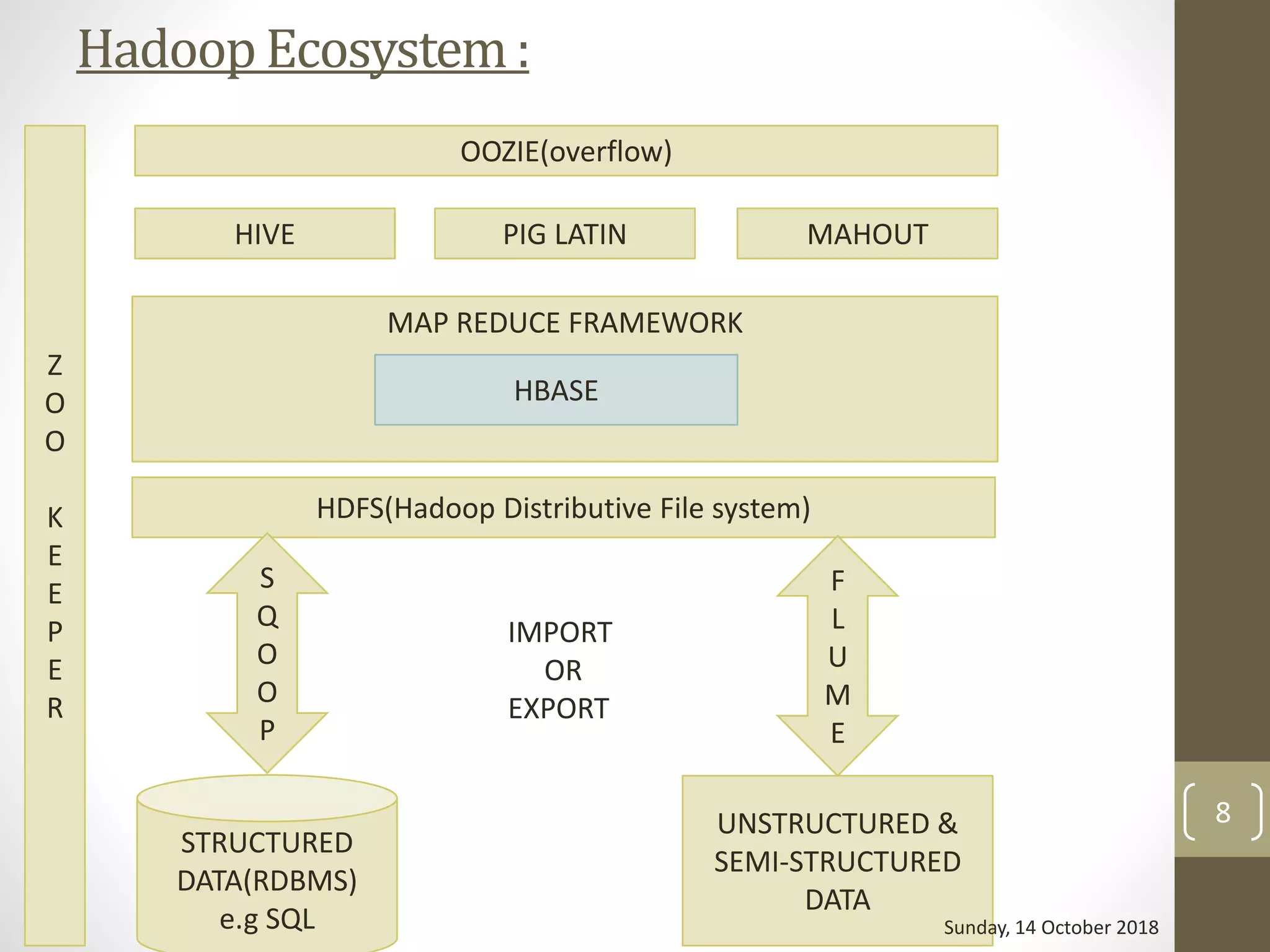
8. Hadoop Ecosystem
9. Hadoop Distributive File System [ HDFS ]
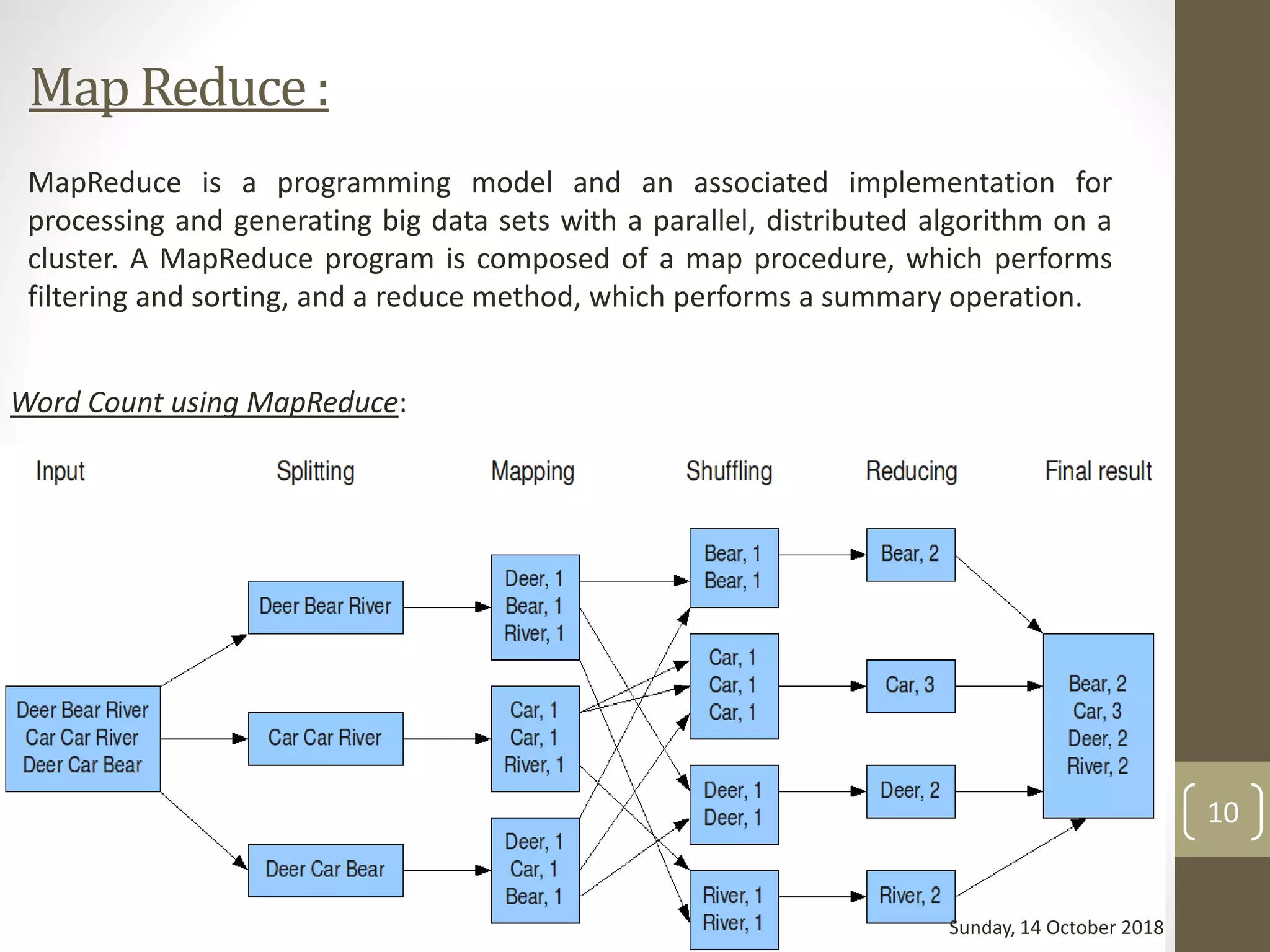
10. Map Reduce
11. Apache Pig
12. Modes of Pig
13. What is Hive ?
14. Example
15. What is Flume ?
16. Advantages of Flume](https://image.slidesharecdn.com/summertrainingpresentation-181014062304/75/Big-Data-Summer-training-presentation-2-2048.jpg)





![Example:
hive> CREATE DATABASE IF NOT EXISTS user;
hive> USE user;
hive> CREATE TABLE IF NOT EXISTS employee ( eid int, name String,
> salary String, destination String)
> COMMENT ‘Employee details’
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ‘t’
> LINES TERMINATED BY ‘n’
> STORED AS TEXTFILE;
hive> LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE
employee;
Sunday, 14 October 2018
14](https://image.slidesharecdn.com/summertrainingpresentation-181014062304/75/Big-Data-Summer-training-presentation-14-2048.jpg)






















































![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)


