Downloaded 18 times








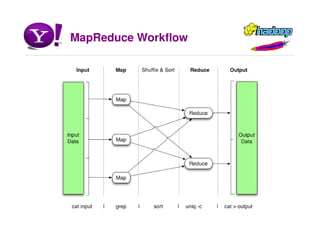


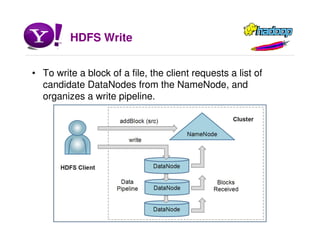







Hadoop is an open source software framework for distributed storage and processing of large datasets across clusters of commodity hardware. It allows for the parallel processing of large datasets in a reliable, fault-tolerant manner. The core components of Hadoop include HDFS for distributed file storage, MapReduce for distributed processing, and other tools like HBase, Pig and Hive for data modeling, analysis and abstraction.











































































































