


















![NoSQL (often interpreted as Not only SQL[1][2]) database provides a
mechanism for storage and retrieval of data that is modeled in means other
than the tabular relations used in relational databases](https://image.slidesharecdn.com/gtg-introtohadoopecosystem-160229114248/85/Intro-to-hadoop-ecosystem-20-320.jpg)




















![Example
players = load 'baseball' as (name:chararray, team:chararray,
position:bag{t:(p:chararray)}, bat:map[]);
noempty = foreach players generate name,
((position is null or IsEmpty(position)) ? {('unknown')} :
position)as position;
pos = foreach noempty generate name, flatten(position) as position;
bypos = group pos by position;](https://image.slidesharecdn.com/gtg-introtohadoopecosystem-160229114248/85/Intro-to-hadoop-ecosystem-48-320.jpg)
![Example
players = load 'baseball' as (name:chararray, team:chararray,
position:bag{t:(p:chararray)}, bat:map[]);
noempty = foreach players generate name,
((position is null or IsEmpty(position)) ? {('unknown')} :
position)as position;
pos = foreach noempty generate name, flatten(position) as position;
bypos = group pos by position;](https://image.slidesharecdn.com/gtg-introtohadoopecosystem-160229114248/85/Intro-to-hadoop-ecosystem-49-320.jpg)


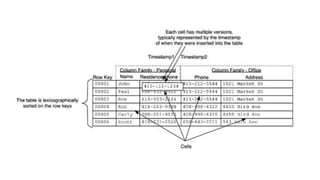



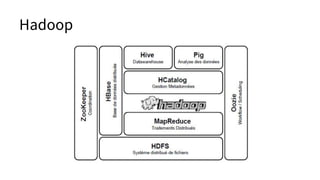
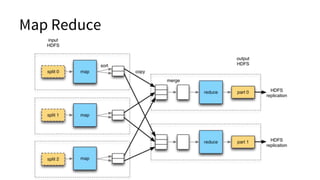
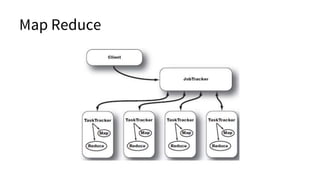
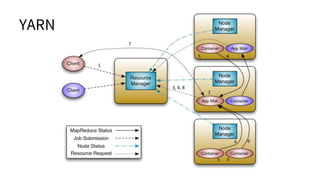
The document discusses various topics related to big data and distributed systems, including technologies such as Hadoop, NoSQL, and frameworks like Apache Spark and HBase. It outlines methodologies, best practices, and trends in the field, alongside details about upcoming presentations and workshops. Additionally, it highlights the importance of handling failures, distributed caching, and real-time data processing.



































































