Download as PDF, PPTX



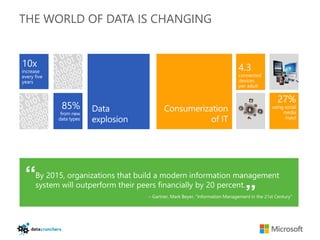






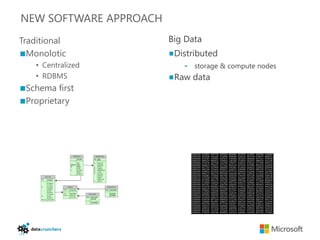
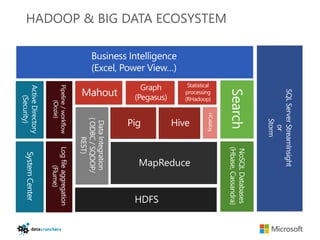

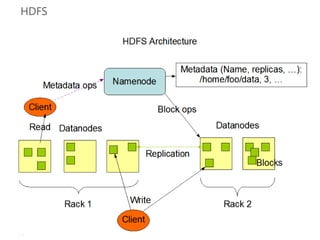
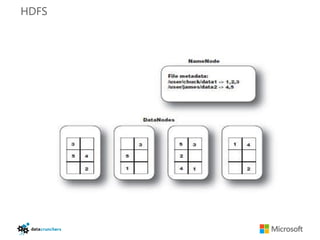


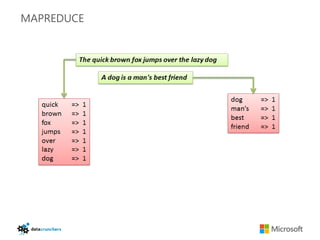
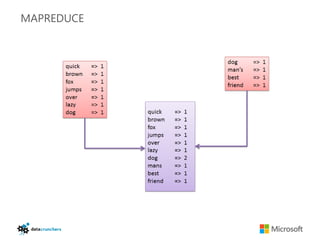







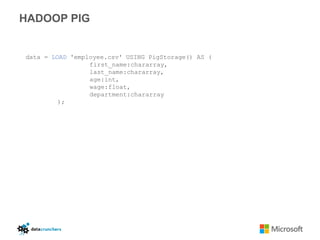







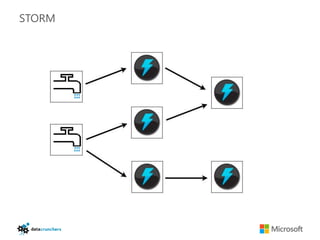

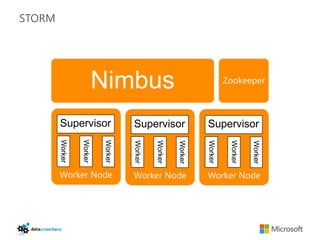
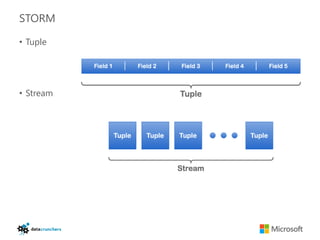
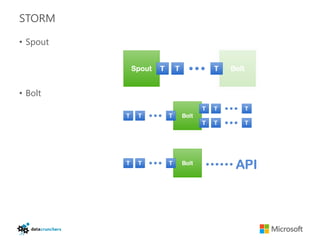
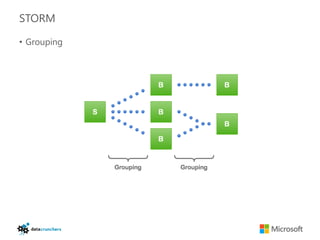









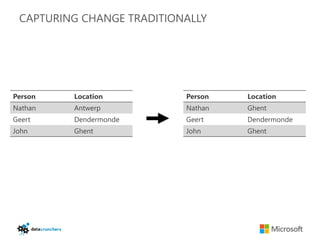




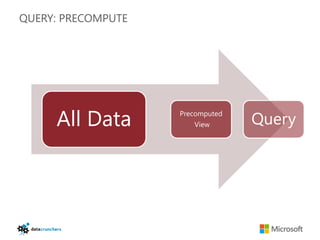
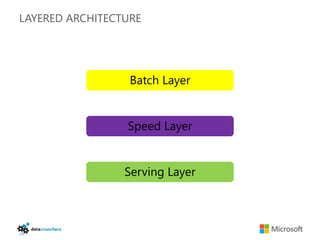
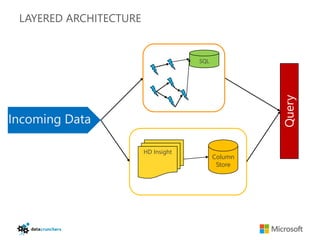

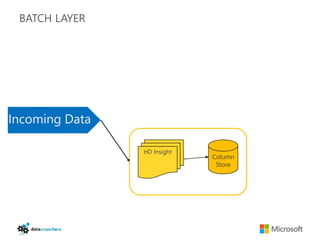





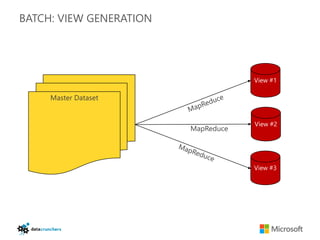
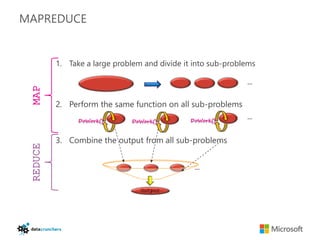



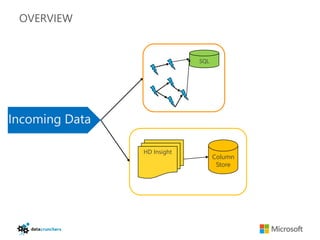







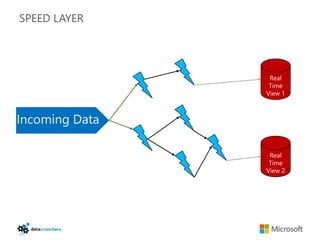


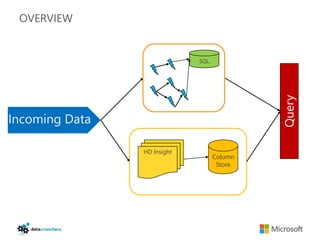

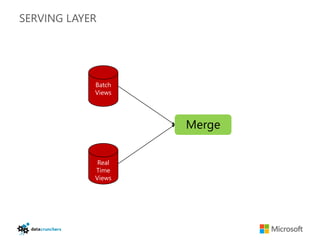


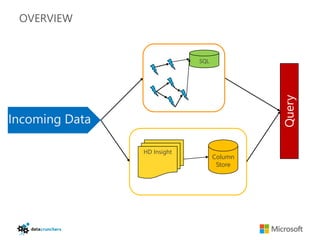

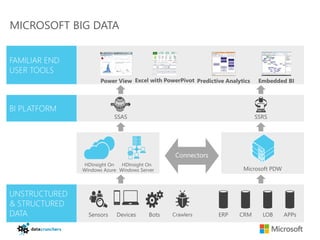





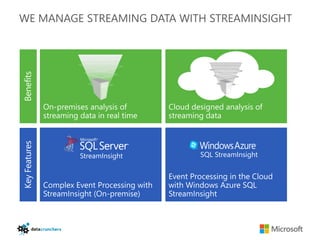



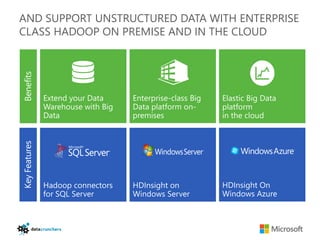
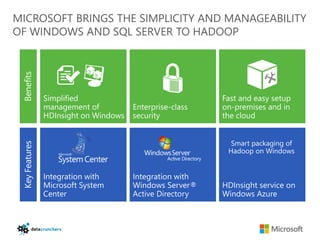
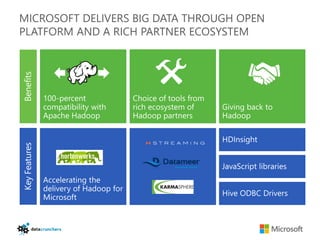





The document discusses big data and Hadoop. It provides an overview of key components in Hadoop including HDFS for storage, MapReduce for distributed processing, Hive for SQL-like queries, Pig for data flows, HBase for column-oriented storage, and Storm for real-time processing. It also discusses building a layered data system with batch, speed, and serving layers to process streaming data at scale.











![Resilience: the key requirement of a [big] [data] architecture - StampedeCon...](https://cdn.slidesharecdn.com/ss_thumbnails/resiliencethekeyrequirementofabigdataarchitecture-stampedecon2015-150717135240-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)























































































