Downloaded 142 times
















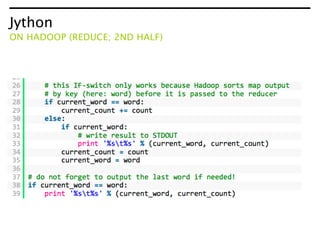


























The document provides an overview of using Python with Hadoop, discussing tools such as Jython, MRJob, and Pig to manage processing large datasets efficiently. It addresses the challenges associated with setting up and debugging distributed systems and emphasizes that while Hadoop facilitates data processing, it does not inherently optimize algorithms. Additionally, it outlines a structured approach for deployment and validation within Python and Hadoop environments.






![Interview questions on Apache spark [part 2]](https://cdn.slidesharecdn.com/ss_thumbnails/interviewquestionsonapachesparkpart2-150731093720-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)




















































































