Downloaded 20 times












![Pig Latin Basic Statements
LOAD [file]: For receive a file,
FOREACH [dataset] GENERATE [statement]: For iterate over the
dataset,
FILTER [dataset] BY [collumn] [type]: Used for filtering data,
GROUP [dataset] BY [collumn]: Used create groups in the dataset,
ORDER [dataset] BY [collumn] [type]: Can order records,
LIMIT [dataset] [integer]: For extract a number or rows,
STORE [dataset] INTO [file]: for save the new d.ataset
REGISTER for external libraries
13](https://image.slidesharecdn.com/pig-analyzingdatasets-150721215923-lva1-app6892/85/Pig-Analyzing-data-sets-13-320.jpg)

![UDF’s
A lot of times it necessary to add some functions at Pig Latin for
expecifics jobs.
Sudar Muthu (http://sudarmuthu.com/blog/writing-pig-udf-functions-using-python/)
@outputSchema("num:long")
def get_length(data):
str_data = ''.join([chr(x) for x in data])
return len(str_data)
REGISTER '/bkf-pig-live-talk/udf.py' USING jython as pyudf;
A = LOAD '/bkf-pig-live-talk/data.txt' USING PigStorage();
B = FOREACH A GENERATE $0, pyudf.get_length($0);
DUMP B;
15](https://image.slidesharecdn.com/pig-analyzingdatasets-150721215923-lva1-app6892/85/Pig-Analyzing-data-sets-15-320.jpg)



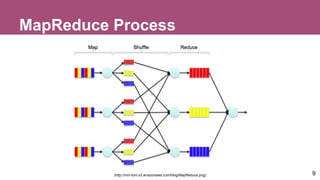
The document discusses Pig, a platform for creating MapReduce jobs in Hadoop, using the Pig Latin scripting language. It explains the basics of Pig Latin, how it compares to SQL, and emphasizes the importance of formulating good questions for data analysis. Additionally, it covers Hadoop's architecture, including HDFS and MapReduce's operational steps.








































































































